Filter By
387 Repositories
Python
Python framework to scrape Pastebin pastes and analyze them
pastepwn - Paste-Scraping Python Framework Pastebin is a very helpful tool to store or rather share ascii encoded data online. In the world of OSINT,
 105 Dec 29, 2022
105 Dec 29, 2022
Tool to scan for secret files on HTTP servers
snallygaster Finds file leaks and other security problems on HTTP servers. what? snallygaster is a tool that looks for files accessible on web servers
 2k Dec 28, 2022
2k Dec 28, 2022
薅薅乐 - JD 测试脚本
薅薅乐 安裝 使用docker docker一键安装: docker run -d --name jd classmatelin/hhl:latest. 使用 进入容器: docker exec -it jd bash 获取JD_COOKIES: python get_jd_cookies.py,
 575 Dec 28, 2022
575 Dec 28, 2022
Pseudo API for Google Trends
pytrends Introduction Unofficial API for Google Trends Allows simple interface for automating downloading of reports from Google Trends. Only good unt
 2.6k Dec 28, 2022
2.6k Dec 28, 2022

A Telegram crawler to search groups and channels automatically and collect any type of data from them.
Introduction This is a crawler I wrote in Python using the APIs of Telethon months ago. This tool was not intended to be publicly available for a numb
 39 Dec 28, 2022
39 Dec 28, 2022
robobrowser - A simple, Pythonic library for browsing the web without a standalone web browser.
RoboBrowser: Your friendly neighborhood web scraper Homepage: http://robobrowser.readthedocs.org/ RoboBrowser is a simple, Pythonic library for browsi
 3.7k Dec 27, 2022
3.7k Dec 27, 2022
a small library for extracting rich content from urls
A small library for extracting rich content from urls. what does it do? micawber supplies a few methods for retrieving rich metadata about a variety o
 588 Dec 27, 2022
588 Dec 27, 2022

Python script to check if there is any differences in responses of an application when the request comes from a search engine's crawler.
crawlersuseragents This Python script can be used to check if there is any differences in responses of an application when the request comes from a se
 13 Dec 27, 2022
13 Dec 27, 2022
Command line program to download documents from web portals.
command line document download made easy Highlights list available documents in json format or download them filter documents using string matching re
 16 Dec 26, 2022
16 Dec 26, 2022
A high-level distributed crawling framework.
Cola: high-level distributed crawling framework Overview Cola is a high-level distributed crawling framework, used to crawl pages and extract structur
 1.5k Dec 24, 2022
1.5k Dec 24, 2022
A modern CSS selector implementation for BeautifulSoup
Soup Sieve Overview Soup Sieve is a CSS selector library designed to be used with Beautiful Soup 4. It aims to provide selecting, matching, and filter
 151 Dec 23, 2022
151 Dec 23, 2022
抢京东茅台脚本,定时自动触发,自动预约,自动停止
jd_maotai 抢京东茅台脚本,定时自动触发,自动预约,自动停止 小白信用 99.6,暂时还没抢到过,朋友 80 多抢到了一瓶,所以我感觉是跟信用分没啥关系,完全是看运气的。
 117 Dec 22, 2022
117 Dec 22, 2022

🥫 The simple, fast, and modern web scraping library
About gazpacho is a simple, fast, and modern web scraping library. The library is stable, actively maintained, and installed with zero dependencies. I
 692 Dec 22, 2022
692 Dec 22, 2022
Simple Web scrapper Bot to scrap webpages using Requests, html5lib and Beautifulsoup.
WebScrapperRoBot Simple Web scrapper Bot to scrap webpages using Requests, html5lib and Beautifulsoup. Mark your Star ⭐ ⭐ What is Web Scraping ? Web s
 53 Dec 21, 2022
53 Dec 21, 2022
Pro Football Reference Game Data Webscraper
Pro Football Reference Game Data Webscraper Code Copyright Yeetzsche This is a simple Pro Football Reference Webscraper that can either collect all ga
 6 Dec 21, 2022
6 Dec 21, 2022
An Automated udemy coupons scraper which scrapes coupons and autopost the result in blogspot post
Autoscraper-n-blogger An Automated udemy coupons scraper which scrapes coupons and autopost the result in blogspot post and notifies via Telegram bot
 13 Dec 21, 2022
13 Dec 21, 2022
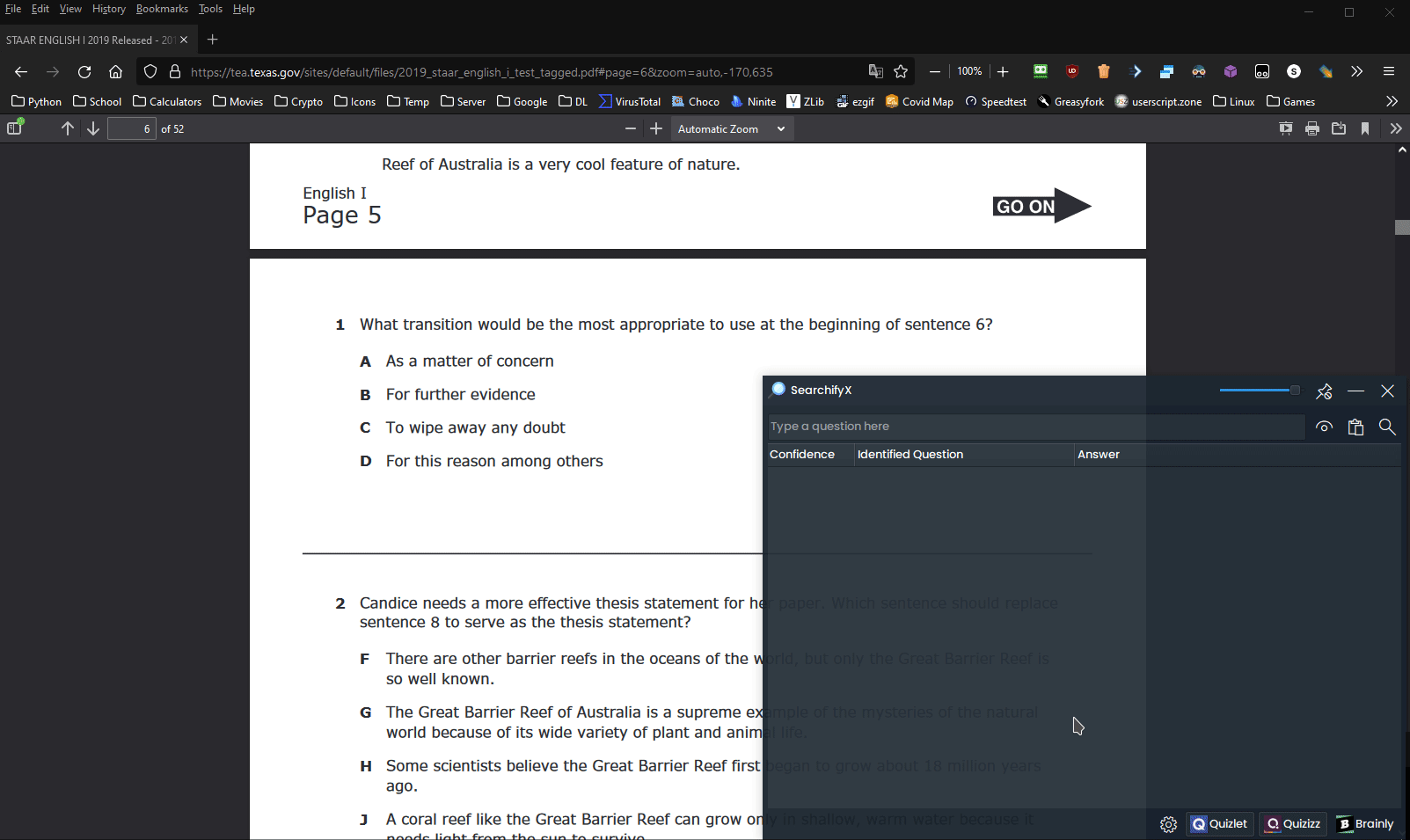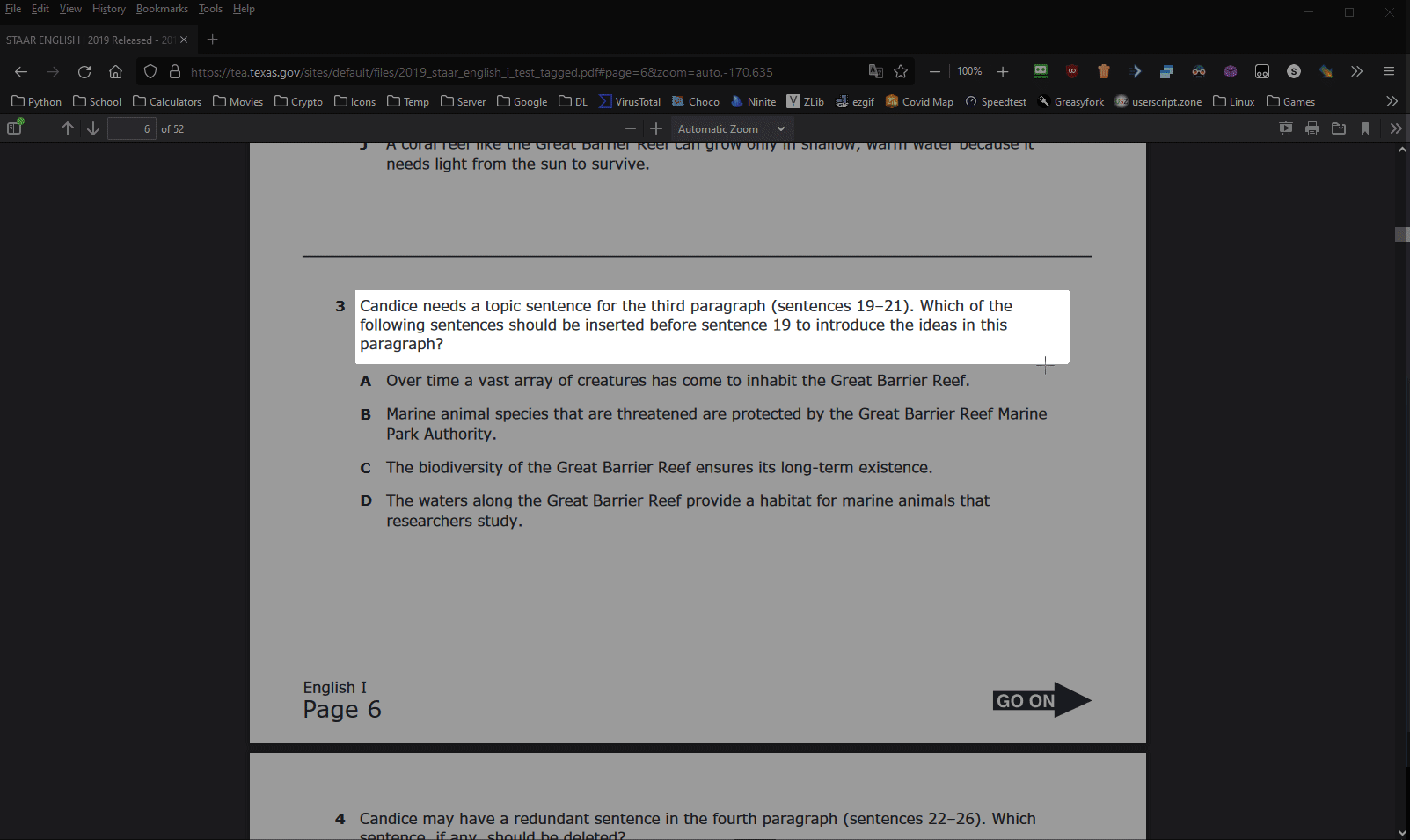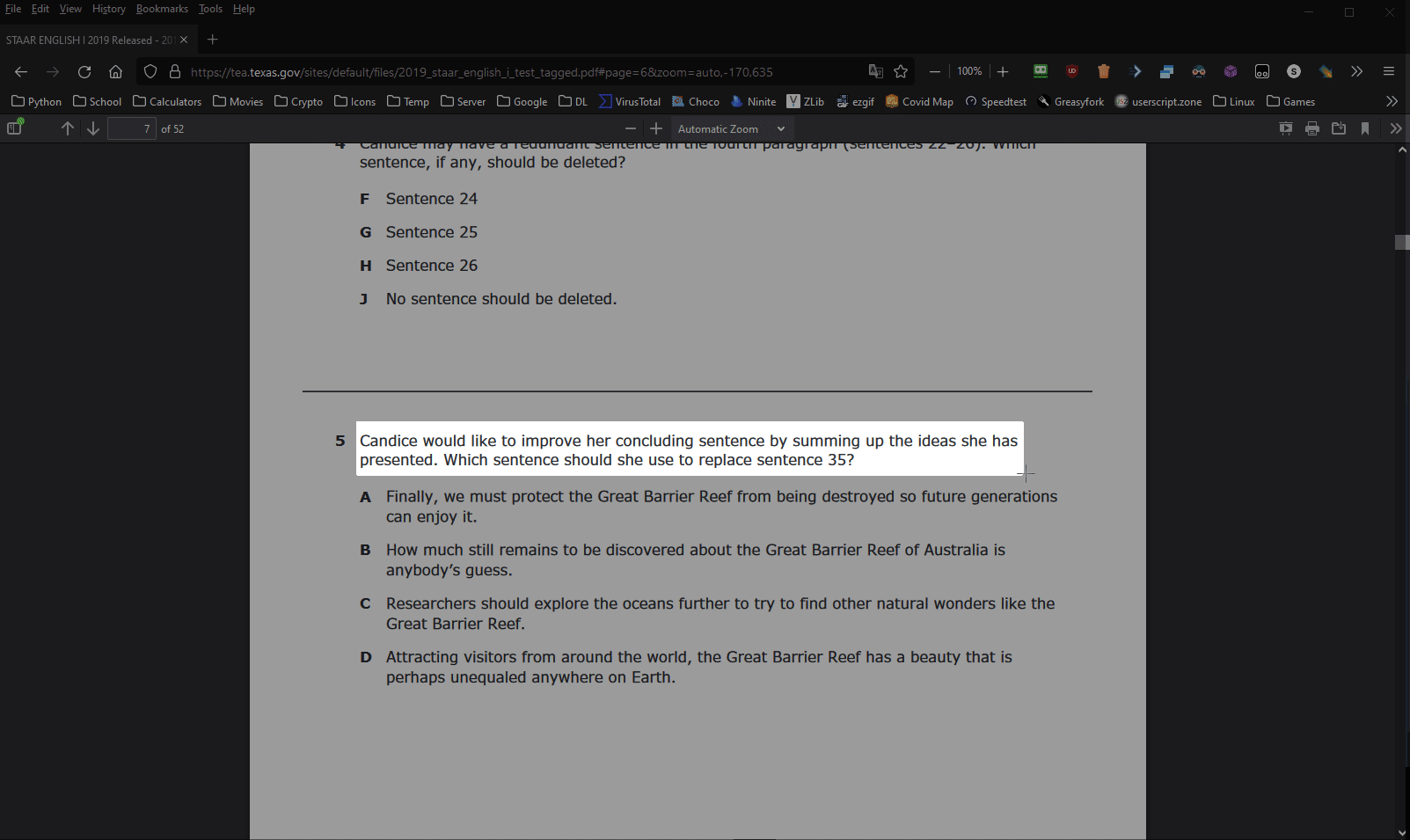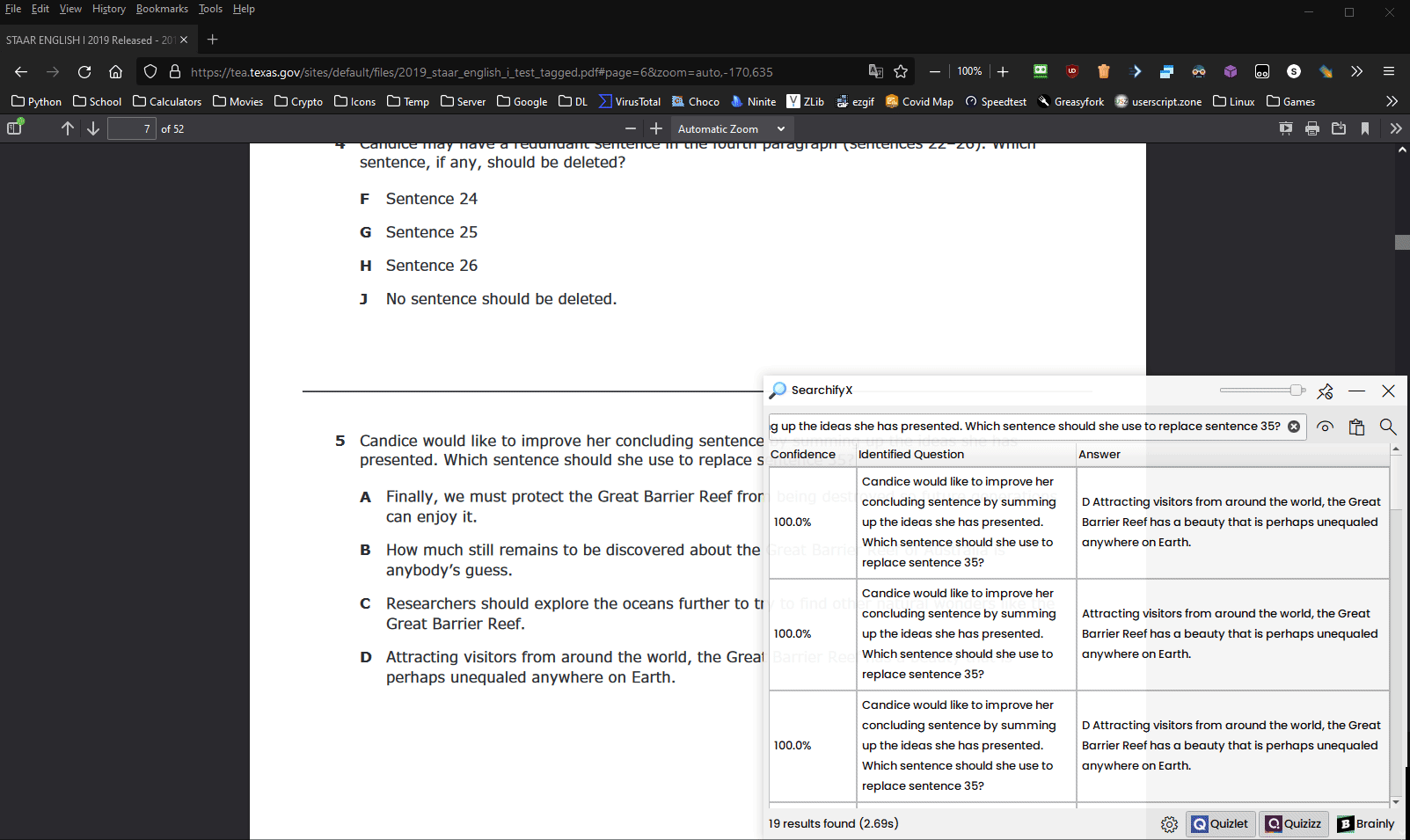
SearchifyX, predecessor to Searchify, is a fast Quizlet, Quizizz, and Brainly webscraper with various stealth features.
SearchifyX SearchifyX, predecessor to Searchify, is a fast Quizlet, Quizizz, and Brainly webscraper with various stealth features. SearchifyX lets you
 28 Dec 20, 2022
28 Dec 20, 2022
UsernameScraperTool - Username Scraper Tool With Python
UsernameScraperTool Username Scraper for 40+ Social sites. How To use git clone
 1 Dec 20, 2022
1 Dec 20, 2022
Web Content Retrieval for Humans™
Lassie Lassie is a Python library for retrieving basic content from websites. Usage import lassie lassie.fetch('http://www.youtube.com/watch?v
 570 Dec 19, 2022
570 Dec 19, 2022
TikTok Username Swapper/Claimer/etc
TikTok-Turbo TikTok Username Swapper/Claimer/etc I wanted to create it as fast as possible but i eventually gave up and recoded it many many many many
 12 Dec 19, 2022
12 Dec 19, 2022
A Python Oriented tool to Scrap WhatsApp Group Link using Google Dork it Scraps Whatsapp Group Links From Google Results And Gives Working Links.
WaGpScraper A Python Oriented tool to Scrap WhatsApp Group Link using Google Dork it Scraps Whatsapp Group Links From Google Results And Gives Working
 27 Dec 18, 2022
27 Dec 18, 2022
Creating Scrapy scrapers via the Django admin interface
django-dynamic-scraper Django Dynamic Scraper (DDS) is an app for Django which builds on top of the scraping framework Scrapy and lets you create and
 1.1k Dec 17, 2022
1.1k Dec 17, 2022
淘宝茅台抢购最新优化版本,淘宝茅台秒杀,优化了茅台抢购线程队列
淘宝茅台抢购最新优化版本,淘宝茅台秒杀,优化了茅台抢购线程队列
 118 Dec 16, 2022
118 Dec 16, 2022
Google Maps crawler using Selenium
Google Maps Crawler using Selenium Built as part of the Antifragile Dev Project Selenium crawler that browses Google Maps as a regular user and stores
 46 Dec 16, 2022
46 Dec 16, 2022
script to scrape direct download links (ddls) from google drive index.
bhadoo Google Personal/Shared Drive Index scraper. A small script to scrape direct download links (ddls) of downloadable files from bhadoo google driv
 53 Dec 16, 2022
53 Dec 16, 2022
A universal package of scraper scripts for humans
Scrapera is a completely Chromedriver free package that provides access to a variety of scraper scripts for most commonly used machine learning and data science domains.
 299 Dec 15, 2022
299 Dec 15, 2022
This is a python api to scrape search results from a url.
googlescrape Installation Installation is simple! # Stable version pip install googlescrape Examples from googlescrape import client scrapeClient=cli
 1 Dec 15, 2022
1 Dec 15, 2022
Find papers by keywords and venues. Then download it automatically
paper finder Find papers by keywords and venues. Then download it automatically. How to use this? Search CLI python search.py -k "knowledge tracing,kn
 2 Dec 15, 2022
2 Dec 15, 2022