Deep Reinforcement Learning for Multiplayer Online Battle Arena
- Prerequisite
- Reference
- Derk Environment
- Dota2 Environment
- Detailed Information
- Acknowledgements
- License
- Python 3
- tmux
- gym-derk
- Dota2 Client 5110
- Tensorflow 2.4.1
- TensorFlow Probability 0.11.0
- Dotaservice of TimZaman
- Google Protobuf 3.19.1
- Pygame 1.9.6
- OpenCV-Python 4.5.4.60
- Six 1.15.0
- Snappy 1.1.2
- Seed RL of Google
- Ubuntu 20.04
- No GPU, 30GB RAM Desktop mini Desktop is used to make multiple Dokcer container of Dotaservice
- GPU, 46GB RAM Desktop is used to make the Seed RL agent
- Seed RL: https://github.com/google-research/seed_rl
- Derk's Gym: https://gym.derkgame.com/
- Dotaservice: https://github.com/TimZaman/dotaservice
- Dotaclient: https://github.com/TimZaman/dotaclient
- LastOrder-Dota2: https://github.com/bilibili/LastOrder-Dota2
- ReDota: https://github.com/timkurvers/redota
- Manta: https://github.com/dotabuff/manta
- Clarity: https://github.com/skadistats/clarity
- Dota2py: https://github.com/andrewsnowden/dota2py
We are going to train small MOBA environment called Derk.

First, move to dr-derks-mutant-battlegrounds folder.

Run below command to run the 50 parallel environment. I modified Seel_RL of Google for my MOBA case.
$ python learner_1.py --workspace_path [your path]/dr-derks-mutant-battlegrounds/
$ python learner_2.py --workspace_path [your path]/dr-derks-mutant-battlegrounds/
$ python run.py -p1 bot -p2 oldbot -n 50
You can check the training progress using Tensorboard log under tboard path of workspace.

After training, one team choose to attack the opponent and the other team choose to defend.

In the case of Derk environment, you can render game and train agent at the same time on one PC. However, in the case of dota2, PC for rendering and a PC for training are required separately because of large size of network and game, and multiple docker containers. Additionally, I use the same user name for the rendering pc and the training pc for the convenience of path setting.
Unlike network for Derk game, which consists of one for observation processing and one for action selecting network, Dota2 agent needs a 6 observation processing networks and 5 action processing networks due to the large size of the game.

Furthermore, each hero has different kind of ability. Some abilities need to be activated by user or other abilities are just passive. That means action part of network structure also should be different from hero to here.

In the case of Shadowfiend which has 4 non passive abilities, ability action network has 4 output. For Omniknight case, network output is three.

In Dota2, unlike Derk, agent need to obtain items and abilities during the game. I save the names of item and ability in the list and use them in order when the gold and level of hero meet certain conditions because this part is a little difficult to implement using the DRL.


Reward for Reinforcement Learning is basically aimed at acquiring XP. Additionally, agents for giving a damage to enemy unit and recovery to home units have different weights for Last Hit.

Finally, huge reward is given according to result of the game to set the long term strategy during the whole game.
You first need to install Dota 2 from Steam. After installation, please check there is Dota2 folder under /home/[your account]/.steam/steam/steamapps/common/dota 2 beta'. We are going to run Dota2 from terminal command.
Occasionally, update Dota2 from Steam launcher will cause problem such as game stops just right after resetting of Dotaservice at rendering case, not dedicated server. I assume client version of Dota2 client is reason of that problem. At this situation, you can download the Dota2 Client 5110 version from my Google Drive. It is downloades as divided Zip file. After extract them, you need to merge them as one filder and put it under the same folder of the existing Dota2 folder. You need to set game path manually at Dotaservice.
Next, you need to download and install dotaservice. In my case, I should modity the _run_dota function of dotaservice.py like below.
async def _run_dota(self):
script_path = os.path.join(self.dota_path, self.DOTA_SCRIPT_FILENAME)
script_path = '/home/[your user name]/.local/share/Steam/ubuntu12_32/steam-runtime/run.sh'
# TODO(tzaman): all these options should be put in a proto and parsed with gRPC Config.
args = [
script_path,
'/home/[your user name]/.local/share/Steam/steamapps/common/dota 2 beta/game/dota.sh',
'-botworldstatesocket_threaded',
'-botworldstatetosocket_frames', '{}'.format(self.ticks_per_observation),
'-botworldstatetosocket_radiant', '{}'.format(self.PORT_WORLDSTATES[TEAM_RADIANT]),
'-botworldstatetosocket_dire', '{}'.format(self.PORT_WORLDSTATES[TEAM_DIRE]),
'-con_logfile', 'scripts/vscripts/bots/{}'.format(self.CONSOLE_LOG_FILENAME),
'-con_timestamp',
'-console',
'-dev',
'-insecure',
'-noip',
'-nowatchdog', # WatchDog will quit the game if e.g. the lua api takes a few seconds.
'+clientport', '27006', # Relates to steam client.
'+dota_1v1_skip_strategy', '1',
'+dota_surrender_on_disconnect', '0',
'+host_timescale', '{}'.format(self.host_timescale),
'+hostname dotaservice',
'+sv_cheats', '1',
'+sv_hibernate_when_empty', '0',
'+tv_delay', '0',
'+tv_enable', '1',
'+tv_title', '{}'.format(self.game_id),
'+tv_autorecord', '1',
'+tv_transmitall', '1', # TODO(tzaman): what does this do exactly?
]
If you enter the following command after modification, the Dota2 game will be launched.
$ python -m dotaservice
$ python env_test.py --render True
Dota 2 should be successfully launched and the hero selection screen should appear. When entering the main game, you can then use \ key to pop up the console. Then, try use the 'jointeam spec' command to see the hero, tower of entire map.

Now, you are ready to train Dota2 with Seed RL just as we did in the Derk game. Try to run Seed RL and Dota2 together on the rendering PC with the following command. The heros act randomly because model does not be trained yet.
$ ./run_impala_test.sh
It will take few minute to load Tensorflow model.
Unlike Derk game, each Dotaservice occupies more than 1GB of memory. Therefore, it is good to run them separately on a mini PC without a GPU. Then, Learner and Actor of IMPALA RL need to be ran on a PC with a GPU.
You need to build the Docker image of Dotaservice mentioned in README.

First, you need to run the Docker containers of Dotaservice using below command on no GPU pc.
$ ./run_dotaservice.sh [number of actors]
$ ./run_dotaservice.sh 20
Next, you need to run the IMPALA RL at GPU PC using below command.
$ ./run_impala_train.sh [number of actors] [DotaService PC IP]
$ ./run_impala_train.sh 20 192.168.1.150
Addidinally, you can terminate both process using below command.
$ ./stop.sh
If you search through the tmux, you can see that 16 dotaservices is ran in one terminal and the other terminal runs 1 learner and 16 actors.

Run below command to see Tensorboard log of training PC from rendeirng PC remotely.
tensorboard --host 0.0.0.0 --logdir=./tensorboard
You can check the training result by using below command.
$ ./run_impala_test.sh
In the case of 1V1MID game mode, which is the most basic type, you can confirm that training was done properly based on the reward graph.

On the rendering PC, you can check the training result better than the graph as shown in the video below. The heros learns how to move to battle point and attack enermy.
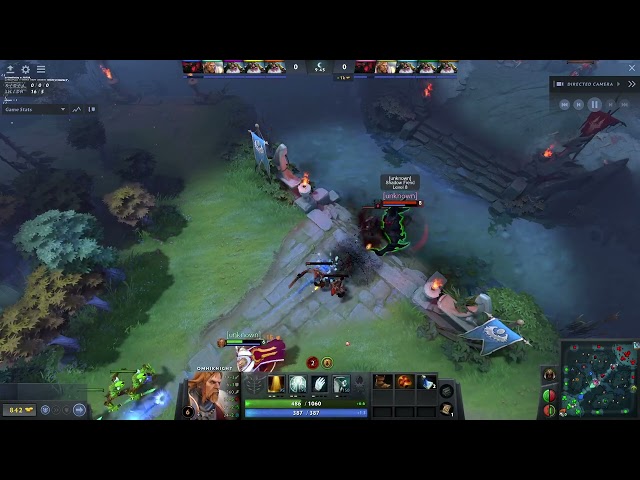
When you run the Dota2 client using below command, it automatically saves the replay files. The path can be different based on your Steam setting.

I collect the replay data of ShadowFiend playing of mine at 5:5 game mode with medium level bots.
$ [your run.sh file path]/run.sh [your dota.sh file path]/run.sh +tv_enable 1 +tv_title test +tv_autorecord 1 +tv_transmitall 1
$ /home/kimbring2/.steam/debian-installation/ubuntu12_32/steam-runtime/run.sh /home/kimbring2/.steam/debian-installation/steamapps/common/dota_old/game/dota.sh +tv_enable 1 +tv_title test +tv_autorecord 1 +tv_transmitall 1
We can parse the information about Hero, NPC, Building from that replay file using the Google Protobuf protocol.
For that, move to folder of this repository. Run below command to start the replay parsing.
$ python parser.py [Dota2 Dem file Path]
$ python parser.py replay/auto-20220409-1106-start-kimbring2.dem
That code only work with Dota2 client that is uploaded to my Google Drive now.
Program will show the replay information screen where you can select each hero and check the ability and item of them. Additionall, you can move the screen by clicking the minimap or pushing the directional keys of keyboard.
This infomation will be used to train the Agent by Supervised Learning method.
I am writing explanation for code at Medium as series.
- Training simple MOBA using DRL: https://medium.com/codex/playing-moba-game-using-deep-reinforcement-learning-part-1-106e60aa4110
- Using detailed function of Dota2: https://dohyeongkim.medium.com/playing-moba-game-using-deep-reinforcement-learning-part-2-a31573b0a48d
- Training complex MOBA using DRL: https://dohyeongkim.medium.com/playing-moba-game-using-deep-reinforcement-learning-part-3-f5b19b2f984f
- Parsing and watching the replay file of Dota2: https://medium.com/mlearning-ai/playing-moba-game-using-deep-reinforcement-learning-part-4-5fdfbff753df
Thank you for my first sponsor "@erlend-sh".
MIT License