Filter By
387 Repositories
Python
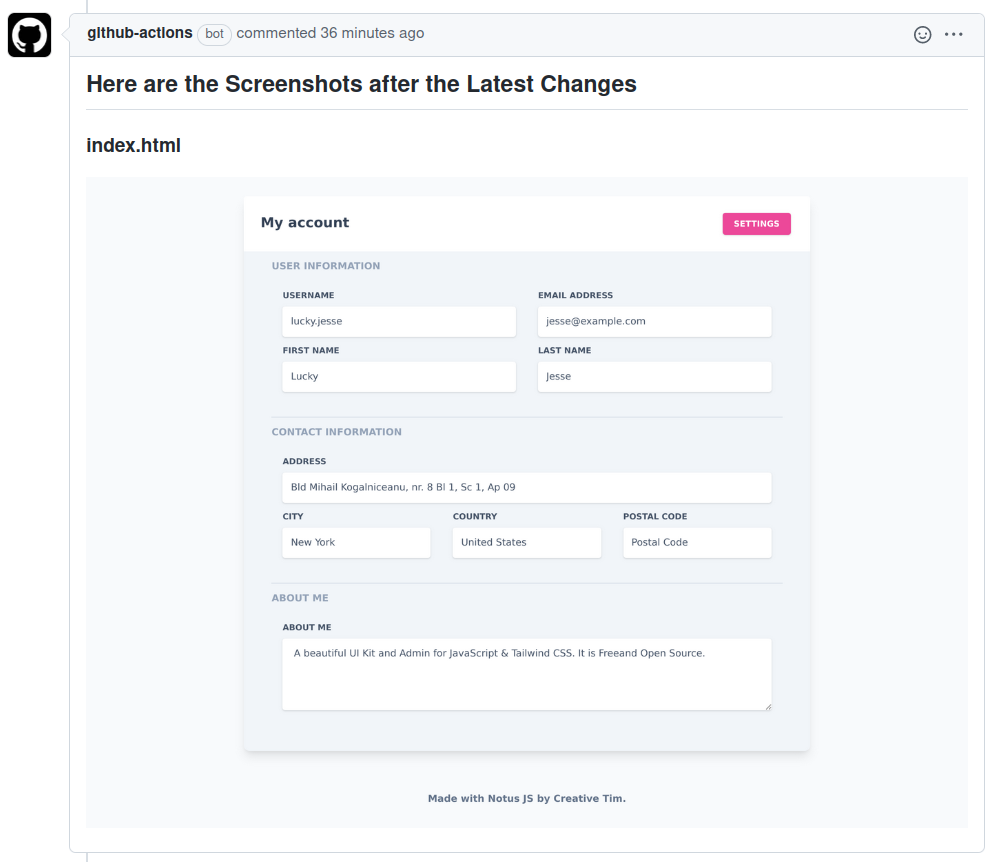
Comment Webpage Screenshot is a GitHub Action that captures screenshots of web pages and HTML files located in the repository
Comment Webpage Screenshot is a GitHub Action that helps maintainers visually review HTML file changes introduced on a Pull Request by adding comments with the screenshots of the latest HTML file cha
 21 Sep 29, 2022
21 Sep 29, 2022

Web Scraping OLX with Python and Bsoup.
webScrap WebScraping first step. Authors: Paulo, Claudio M. First steps in Web Scraping. Project carried out for training in Web Scrapping. The export
 5 Sep 25, 2022
5 Sep 25, 2022
New World Market Scraper
Bean Seller A New Worlds market scraper. Deployment This must be installed on Windows as it uses the Windows api to do its stuff Install Prerequisites
 4 Sep 21, 2022
4 Sep 21, 2022
Python scraper to check for earlier appointments in Clalit Health Services
clalit-appt-checker Python scraper to check for earlier appointments in Clalit Health Services Some background If you ever needed to schedule a doctor
 16 Sep 17, 2022
16 Sep 17, 2022

自动完成每日体温上报(Github Actions)
体温上报助手 简介 每天 10:30 GMT+8 自动完成体温上报,如想修改定时运行的时间,可修改 .github/workflows/SduHealthReport.yml 中 schedule 属性。 如果当日有异常,请手动在小程序端/PC 端填写!
 23 Sep 15, 2022
23 Sep 15, 2022
Introduction to WebScraping Workshop - Semcomp 24 Beta
Extrair informações da internet de forma automatizada. Existem diversas maneiras de fazer isso, nesse tutorial vamos ver algumas delas, por meio de bibliotecas de python.
 19 Sep 11, 2022
19 Sep 11, 2022
An arxiv spider
An Arxiv Spider 做为一个cser,杰出男孩深知内核对连接到计算机上的硬件设备进行管理的高效方式是中断而不是轮询。每当小伙伴发来一篇刚挂在arxiv上的”热乎“好文章时,杰出男孩都会感叹道:”师兄这是每天都挂在arxiv上呀,跑的好快~“。于是杰出男孩找了找 github,借鉴了一下其
 11 Sep 09, 2022
11 Sep 09, 2022

Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data.
Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data. Then used Yahoo Finance to get the related stock data and displayed them in the form of chart
 3 Sep 09, 2022
3 Sep 09, 2022

A module for CME that spiders hashes across the domain with a given hash.
hash_spider A module for CME that spiders hashes across the domain with a given hash. Installation Simply copy hash_spider.py to your CME module folde
 37 Sep 08, 2022
37 Sep 08, 2022
茅台抢购最新优化版本,茅台秒杀,优化了抢购协程队列
茅台抢购最新优化版本,茅台秒杀,优化了抢购协程队列
 33 Sep 03, 2022
33 Sep 03, 2022

crypto currency scraping
SCRYPTO What ? Crypto currencies scraping (At the moment, only bitcoin and ethereum crypto currencies are supported) How ? A python script is running
 15 Sep 01, 2022
15 Sep 01, 2022
Python script for crawling ResearchGate.net papers✨⭐️📎
ResearchGate Crawler Python script for crawling ResearchGate.net papers About the script This code start crawling process by urls in start.txt and giv
 4 Aug 30, 2022
4 Aug 30, 2022
让中国用户使用git从github下载的速度提高1000倍!
序言 github上有很多好项目,但是国内用户连github却非常的慢.每次都要用插件或者其他工具来解决. 这次自己做一个小工具,输入github原地址后,就可以自动替换为代理地址,方便大家更快速的下载. 安装 pip install cit 主要功能与用法 主要功能 change 将目标地址转换为
 35 Aug 29, 2022
35 Aug 29, 2022
Divar.ir Ads scrapper
Divar.ir Ads Scrapper Introduction This project first asynchronously grab Divar.ir Ads and then save to .csv and .xlsx files named data.csv and data.x
 4 Aug 29, 2022
4 Aug 29, 2022

python+selenium实现的web端自动打卡 + 每日邮件发送 + 金山词霸 每日一句 + 毒鸡汤(从2月份稳定运行至今)
python+selenium实现的web端自动打卡 说明 本打卡脚本适用于郑州大学健康打卡,其他web端打卡也可借鉴学习。(自己用的,从2月分稳定运行至今) 仅供学习交流使用,请勿依赖。开发者对使用本脚本造成的问题不负任何责任,不对脚本执行效果做出任何担保,原则上不提供任何形式的技术支持。 为防止
 1 Aug 27, 2022
1 Aug 27, 2022
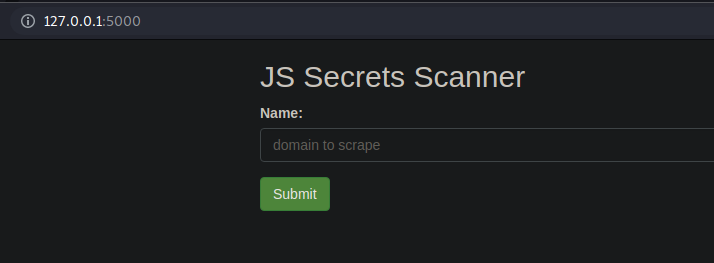
Python based Web Scraper which can discover javascript files and parse them for juicy information (API keys, IP's, Hidden Paths etc)
Python based Web Scraper which can discover javascript files and parse them for juicy information (API keys, IP's, Hidden Paths etc).
 6 Aug 26, 2022
6 Aug 26, 2022
Scraping weather data using Python to receive umbrella reminders
A Python package which scrapes weather data from google and sends umbrella reminders to specified email at specified time daily.
 1 Aug 23, 2022
1 Aug 23, 2022
A web crawler for recording posts in "sina weibo"
Web Crawler for "sina weibo" A web crawler for recording posts in "sina weibo" Introduction This script helps collect attributes of posts in "sina wei
 4 Aug 20, 2022
4 Aug 20, 2022
A python script to extract answers to any question on Quora (Quora+ included)
quora-plus-bypass A python script to extract answers to any question on Quora (Quora+ included) Requirements Python 3.x
 10 Aug 18, 2022
10 Aug 18, 2022
Facebook Group Scraping Using Beautiful Soup & Selenium
Extract Facebook group posts that are related to a specific topic and write them to a .json file.
 14 Aug 12, 2022
14 Aug 12, 2022
A Python package that scrapes Google News article data while remaining undetected by Google.
A Python package that scrapes Google News article data while remaining undetected by Google. Our scraper can scrape page data up until the last page and never trigger a CAPTCHA (download stats: https
 6 Aug 10, 2022
6 Aug 10, 2022

A database scraper created with mechanical soup and sqlite
WebscrapingDatabases a database scraper created with mechanical soup and sqlite author: Mariya Sha Watch on YouTube: This repository was created to su
 30 Aug 08, 2022
30 Aug 08, 2022
tweet random sand cat pictures
sandcatbot setup pip3 install --user -r requirements.txt cp sandcatbot.example.conf sandcatbot.conf vim sandcatbot.conf running the first parameter i
 8 Aug 07, 2022
8 Aug 07, 2022
Unja is a fast & light tool for fetching known URLs from Wayback Machine
Unja Fetch Known Urls What's Unja? Unja is a fast & light tool for fetching known URLs from Wayback Machine, Common Crawl, Virus Total & AlienVault's
 10 Aug 07, 2022
10 Aug 07, 2022
An utility library to scrape data from TikTok, Instagram, Twitch, Youtube, Twitter or Reddit in one line!
Social Media Scraper An utility library to scrape data from TikTok, Instagram, Twitch, Youtube, Twitter or Reddit in one line! Go to the website » Vie
 2 Aug 03, 2022
2 Aug 03, 2022

Scrape data on SpaceX: Capsules, Rockets, Cores, Roadsters, SpaceX Info
SpaceX Sofware I developed software to scrape data on SpaceX: Capsules, Rockets, Cores, Roadsters, SpaceX Info to use the software you need Python a
 16 Aug 02, 2022
16 Aug 02, 2022

Automatically download and crop key information from the arxiv daily paper.
Arxiv daily 速览 功能:按关键词筛选arxiv每日最新paper,自动获取摘要,自动截取文中表格和图片。 1 测试环境 Ubuntu 16+ Python3.7 torch 1.9 Colab GPU 2 使用演示 首先下载权重baiduyun 提取码:il87,放置于code/Pars
 20 Jul 30, 2022
20 Jul 30, 2022
一款利用Python来自动获取QQ音乐上某个歌手所有歌曲歌词的爬虫软件
QQ音乐歌词爬虫 一款利用Python来自动获取QQ音乐上某个歌手所有歌曲歌词的爬虫软件,默认去除了所有演唱会(Live)版本的歌曲。 使用方法 直接运行python run.py即可,然后输入你想获取的歌手名字,然后静静等待片刻。 output目录下保存生成的歌词和歌名文件。以周杰伦为例,会生成两
 11 Jul 27, 2022
11 Jul 27, 2022