{kind=link}
{kind=link}
{kind=link}
中文生成式预训练模型,以mT5为基础架构和初始权重,通过类似PEGASUS的方式进行预训练。
详情可见:https://kexue.fm/archives/8209
我们将T5 PEGASUS的Tokenizer换成了BERT的Tokenizer,它对中文更加友好。同时,我们重新整理了一版词表,使得里边的字、词都更加完善,目前的vocab.txt共包含5万个token,真正覆盖了中文的常用字、词。
预训练任务模仿了PEGASUS的摘要式预训练。具体来说,假设一个文档有n个句子,我们从中挑出大约n/4个句子(可以不连续),使得这n/4个句子拼起来的文本,跟剩下的3n/4个句子拼起来的文本,最长公共子序列尽可能长,然后我们将3n/4个句子拼起来的文本视为原文,n/4个句子拼起来的文本视为摘要,通过这样的方式构成一个“(原文, 摘要)”的伪摘要数据对。

目前开源的T5 PEGASUS是base版,总参数量为2.75亿,训练时最大长度为512,batch_size为96,学习率为10-4,使用6张3090训练了100万步,训练时间约13天,数据是30多G的精处理通用语料,训练acc约47%,训练loss约2.97。模型使用bert4keras进行编写、训练和测试。
运行环境:tensorflow 1.15 + keras 2.3.1 + bert4keras 0.10.0
链接: chinese_t5_pegasus_base.zip
2021年03月16日: 新增T5 PEGASUS的small版,参数量为0.95亿,对显存更友好,训练参数与base版一致(最大长度为512,batch_size为96,学习率为10-4,使用3张TITAN训练了100万步,训练时间约12天,数据是30多G的精处理通用语料,训练acc约42.3%,训练loss约3.40。),中文效果相比base版略降,比mT5 small版要好。
链接: chinese_t5_pegasus_small.zip
网友renmada转的pytorch版:https://github.com/renmada/t5-pegasus-pytorch
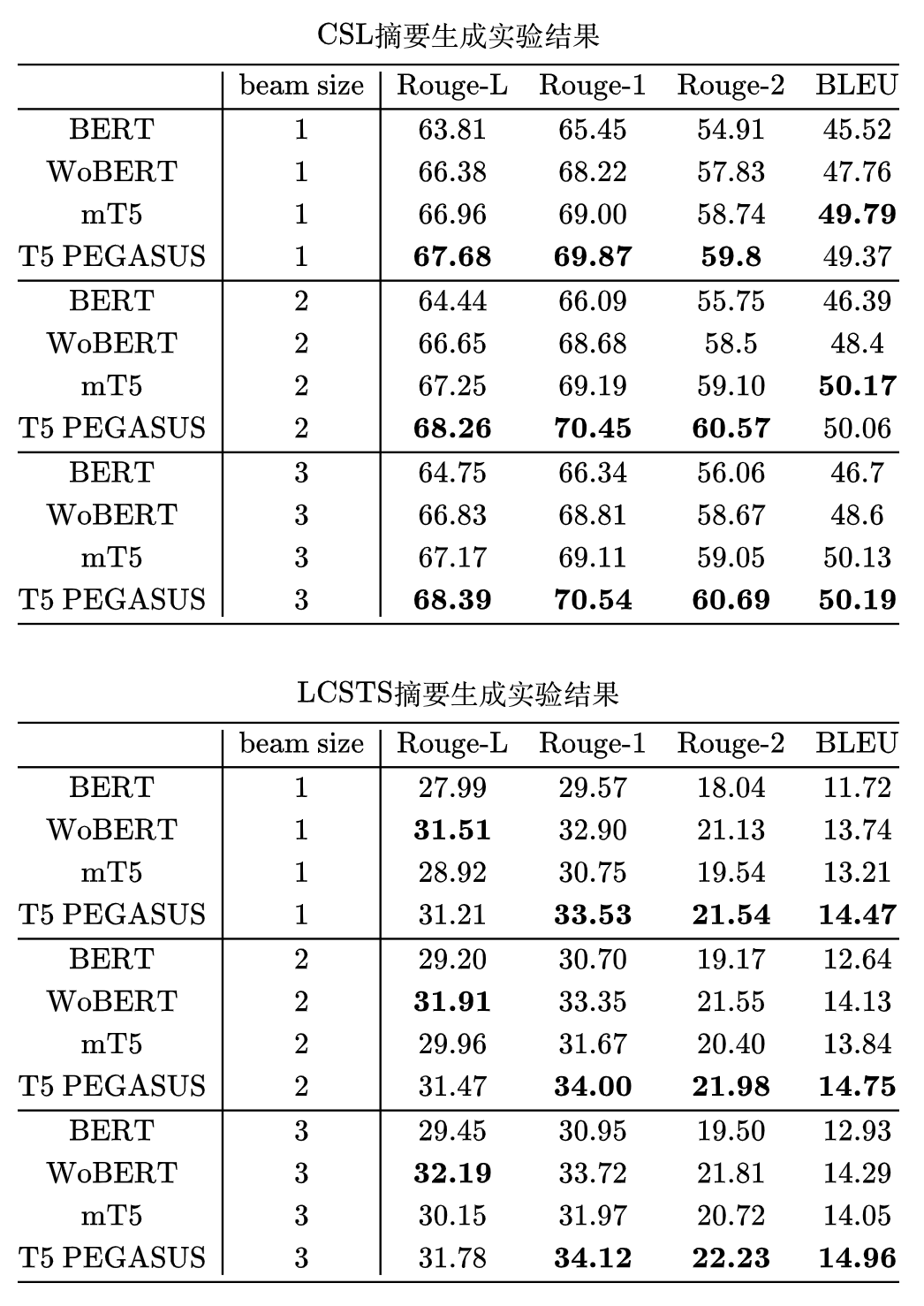
摘要生成效果:
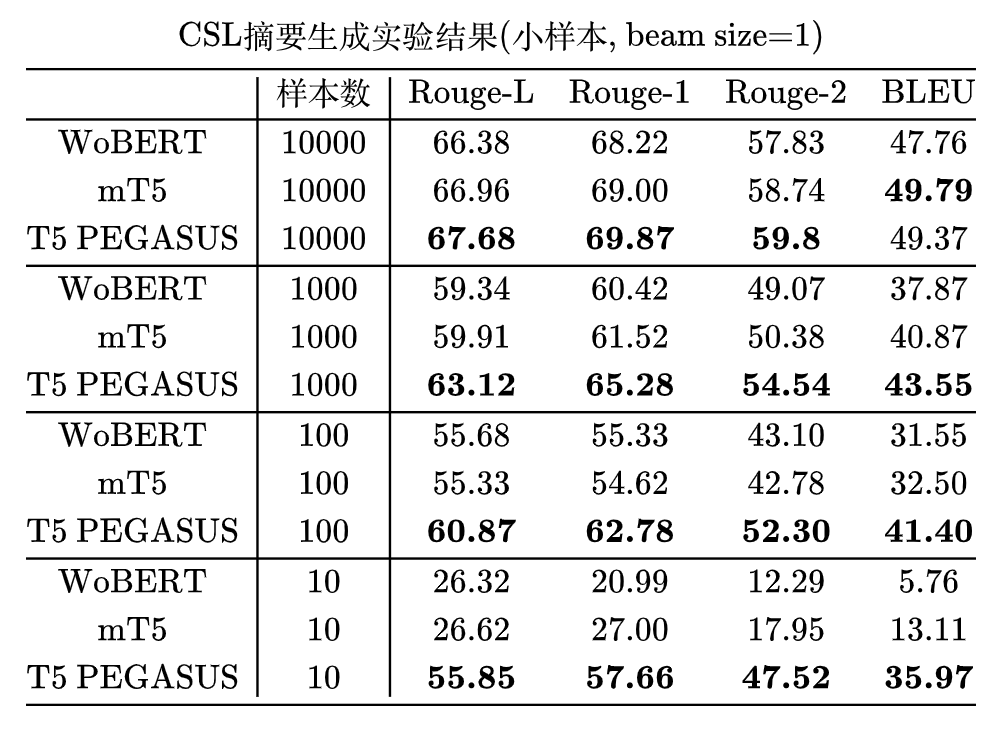
小样本学习:
Bibtex:
@techreport{zhuiyit5pegasus,
title={T5 PEGASUS - ZhuiyiAI},
author={Jianlin Su},
year={2021},
url="https://github.com/ZhuiyiTechnology/t5-pegasus",
}邮箱:ai@wezhuiyi.com 追一科技:https://zhuiyi.ai