{kind=link}
{kind=link}
{kind=link}
{kind=link}

- in scope parsing
- file extensions to ignore
- files exclusion based on regexp
- multi tabs for multiple purpose
- data extraction based on regexp
- results exclusion based on regexp
- data export
First of all, ensure you have Jython installed and loaded and setup before the next step.
- clone this repository
- in the Extender tab, click the button
Add - set
Extension typetoPython - browse to the cloned folder and select
DataExtractor.pyas theExtension file
The extension should load and is now ready to perform a passive scan.
-
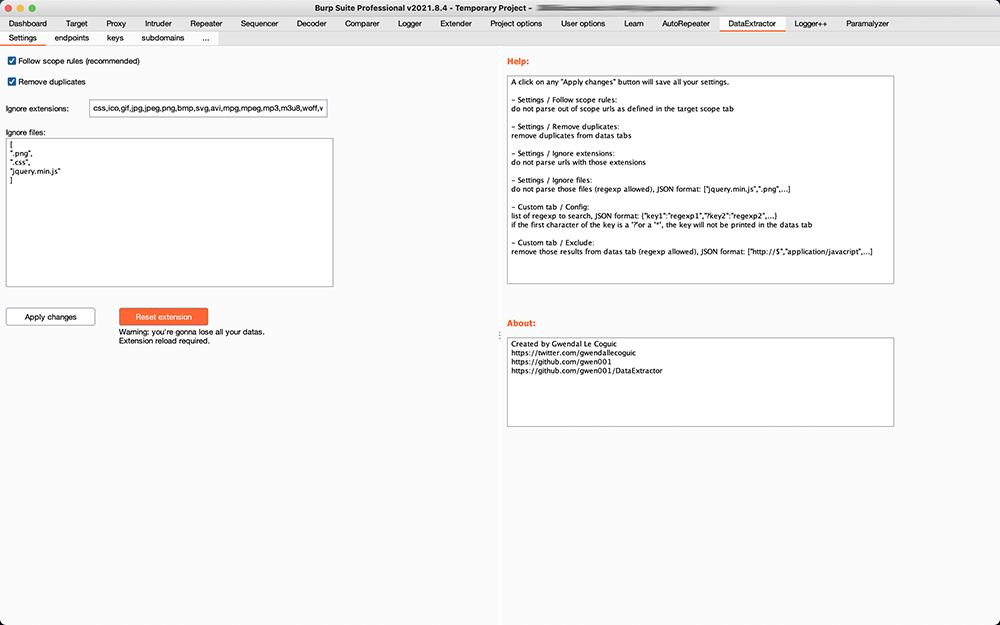
A single click on any
Apply changesbutton will save all your settings -
Settings / Follow scope rules: do not parse out of scope urls as defined in the target scope tab
-
Settings / Remove duplicates: remove duplicates from data tabs
-
Settings / Ignore extensions: do not parse urls with those extensions
-
Settings / Ignore files: do not parse those files (regexps allowed), JSON format:
["jquery.min.js",".png",...]
important: regexps here are case insentitive by design -
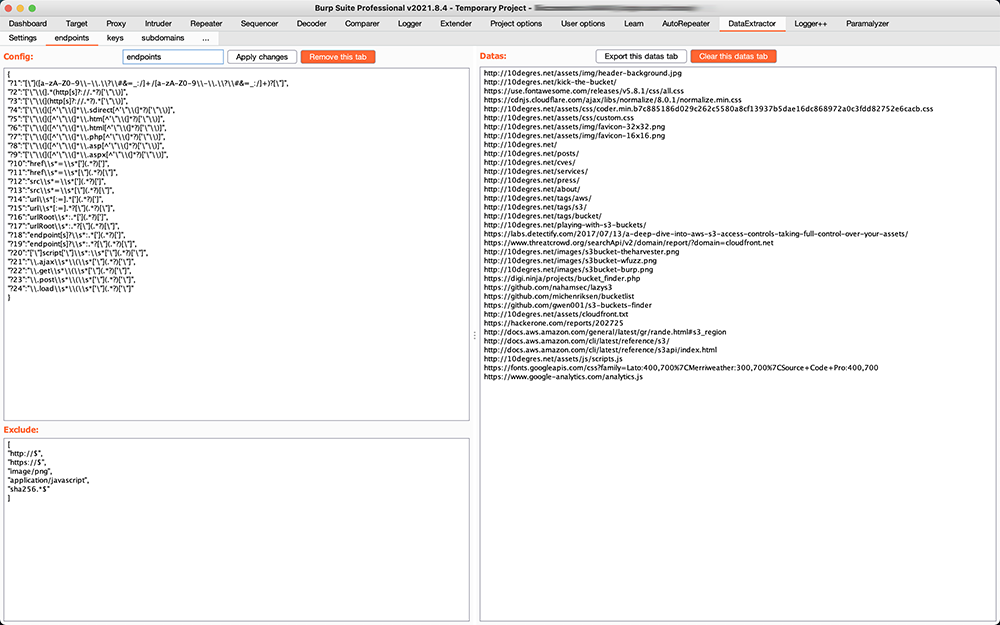
Custom tab / Config: list of regexps to search, JSON format:
{"key1":"regexp1","?key2":"regexp2",...}
if the first character of the key is a?or a*, the key will not be printed in the data tab
important: regexps here are NOT case sentitive, use(?i)as a prefix of the whole regexp to make it insentitive
important: you should have at least 1 group configured using parenthesis()to be able to catch something,group(1)is used as a result so to ignore a group, please use?:as a prefix of the group itself -
Custom tab / Remove from results: remove those results from data tab (regexps allowed), JSON format:
["http://$","application/javacript",...]
important: regexps here are case insentitive by design
All config textareas should be valid JSON format associative arrays (key/value), so take care of every single comma and quote.
As soon as you save your settings, a check is performed so you can ensure that everything is fine in the output/errors tab of the exender tab.
Note that all keys should be different.
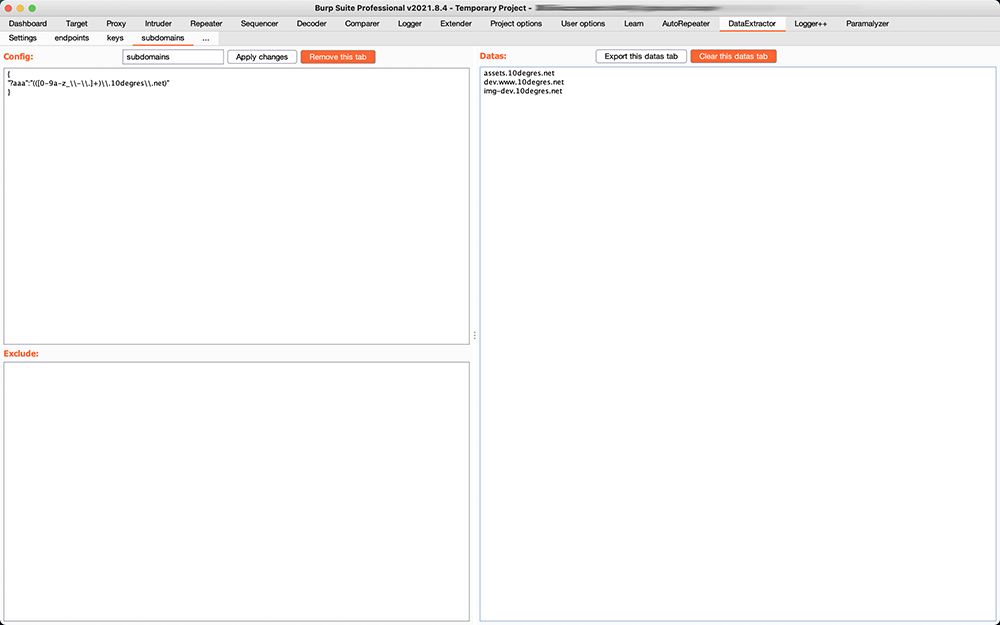
Subdomains (case insensitive):
{
"*dummykey1":"(?i)(([0-9a-z_\\-\\.]+)\\.github\\.com)"
}
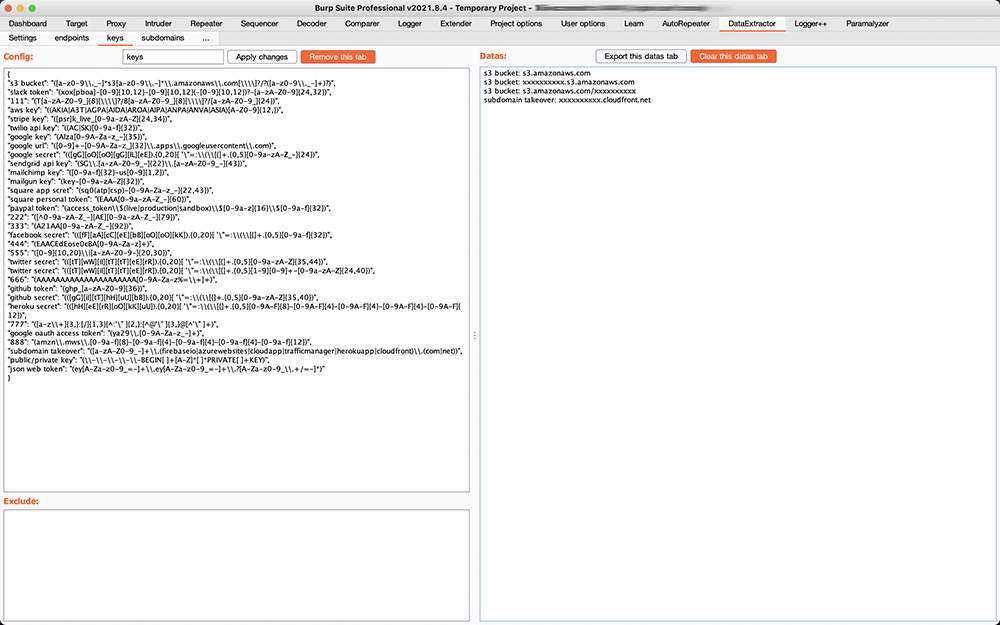
AWS keys ans Slack tokens (case sensitive):
{
"slack token": "(xox[pboa]-[0-9]{10,12}-[0-9]{10,12}(-[0-9]{10,12})?-[a-zA-Z0-9]{24,32})",
"aws key": "((AKIA|A3T|AGPA|AIDA|AROA|AIPA|ANPA|ANVA|ASIA)[A-Z0-9]{12,})"
}
See the file myregexp to get all my regexps.
All ignore/remove textareas should be valid JSON format arrays, so take care of every single comma and quote. As soon as you save your settings, a check is performed so you can ensure that everything is fine in the output/errors tab of the exender tab.
[
".png$",
"application/javascript",
"googleapis.com",
"sha256.*$"
]
Feel free to open an issue if you have any problem with the script.