Hossein Adeli and Seoyoung Ahn
Please cite this article if you find this repository useful:
Adeli, H., Ahn, S., & Zelinsky, G. J. (2023). A brain-inspired object-based attention network for multiobject recognition and visual reasoning. Journal of Vision, 23(5), 16-16. [link] [google scholar]
@article{adeli2023brain,
title={A brain-inspired object-based attention network for multiobject recognition and visual reasoning},
author={Adeli, Hossein and Ahn, Seoyoung and Zelinsky, Gregory J},
journal={Journal of Vision},
volume={23},
number={5},
pages={16--16},
year={2023},
publisher={The Association for Research in Vision and Ophthalmology}
}Short presentation of the work:

-
For data generation and loading
- stimuli_util.ipynb includes all the codes and the instructions for how to generate the datasets for the three tasks; MultiMNIST, MultiMNIST Cluttered and MultiSVHN.
- loaddata.py should be updated with the location of the data files for the tasks if not the default used.
-
For training and testing the model:
-
OCRA_demo.ipynb includes the code for building and training the model. In the first notebook cell, a hyperparameter file should be specified. Parameter files are provided here (different settings are discussed in the supplementary file)
-
multimnist_params_10glimpse.txt and multimnist_params_3glimpse.txt set all the hyperparameters for MultiMNIST task with 10 and 3 glimpses, respectively.
OCRA_demo-MultiMNIST_3glimpse_training.ipynb shows how to load a parameter file and train the model.
-
multimnist_cluttered_params_7glimpse.txt and multimnist_cluttered_params_5glimpse.txt set all the hyperparameters for MultiMNIST Cluttered task with 7 and 5 glimpses, respectively.
-
multisvhn_params.txt sets all the hyperparameters for the MultiSVHN task with 12 glimpses.
-
This notebook also includes code for testing a trained model and also for plotting the attention windows for sample images.
OCRA_demo-cluttered_5steps_loadtrained.ipynb shows how to load a trained model and test it on the test dataset. Example pretrained models are included in the repository under pretrained folder. Download all the pretrained models.
-
From MultiMNIST OCRA-10glimpse:

From Cluttered MultiMNIST OCRA-7glimpse

The opportunity to observe the object-centric behavior is bigger in the cluttered task. Since the ratio of the glimpse size to the image size is small (covering less than 4 percent of the image), the model needs to optimally move and select the objects to accurately recognize them. Also reducing the number of glimpses has a similar effect, (we experimented with 3 and 5) forcing the model to leverage its object-centric representation to find the objects without being distracted by the noise segments. We include many more examples of the model behavior with both 3 and 5 glimpses to show this behavior.








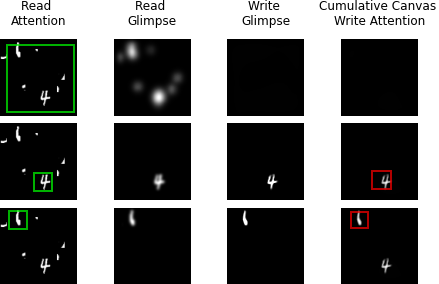





We train the model to "read" the digits from left to right by having the order of the predicted sequence match the ground truth from left to right. We allow the model to make 12 glimpses, with the first two not being constrained and the capsule length from every following two glimpses will be read out for the output digit (e.g. the capsule lengths from the 3rd and 4th glimpses are read out to predict digit number 1; the left-most digit and so on). Below are sample behaviors from our model.
The top five rows show the original images, and the bottom five rows show the reconstructions

The generation of sample images across 12 glimpses

The generatin in a gif fromat

The model learns to detect and reconstruct objects. The model achieved ~2.5 percent error rate on recognizing individual digits and ~10 percent error in recognizing whole sequences still lagging SOTA performance on this measure. We believe this to be strongly related to our small two-layer convolutional backbone and we expect to get better results with a deeper one, which we plan to explore next. However, the model shows reasonable attention behavior in performing this task.
Below shows the model's read and write attention behavior as it reads and reconstructs one image.

Herea are a few sample mistakes from our model:

ground truth [ 1, 10, 10, 10, 10]
prediction [ 0, 10, 10, 10, 10]
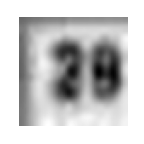
ground truth [ 2, 8, 10, 10, 10]
prediction [ 2, 9, 10, 10, 10]

ground truth [ 1, 2, 9, 10, 10]
prediction [ 1, 10, 10, 10, 10]

ground truth [ 5, 1, 10, 10, 10]
prediction [ 5, 7, 10, 10, 10]
Some MNIST cluttered results
Testing the model on MNIST cluttered dataset with three time steps




Code references: