Paradigm Shift in NLP
Welcome to the webpage for "Paradigm Shift in Natural Language Processing". Some resources of the paper are constantly maintained here, such as a full list of papers of paradigm shift, an interactive Sankey diagram to depict the trend of paradigm shift, etc.
What is paradigm shift?
First of all, what is paradigm, and what is paradigm shift?
Paradigm is the general framework to model a class of tasks. For example, sequence labeling (SeqLab) is a popular paradigm to solve named entity recognition (NER). We summarize the mainstream paradigms that are widely used for common NLP tasks as: Class, Matching, SeqLab, MRC, Seq2Seq, Seq2ASeq, (M)LM.
Paradigm shift is a phenomena of solving a task that is usually solved with some paradigm with another paradigm. For example, Li et al. (2020) uses the MRC paradigm to solve NER, which is previously solved with SeqLab, then we can say that the paradigm of NER shifted from SeqLab to MRC.
The figure below shows the observed shift (or transfer) of the seven paradigms in recent years.
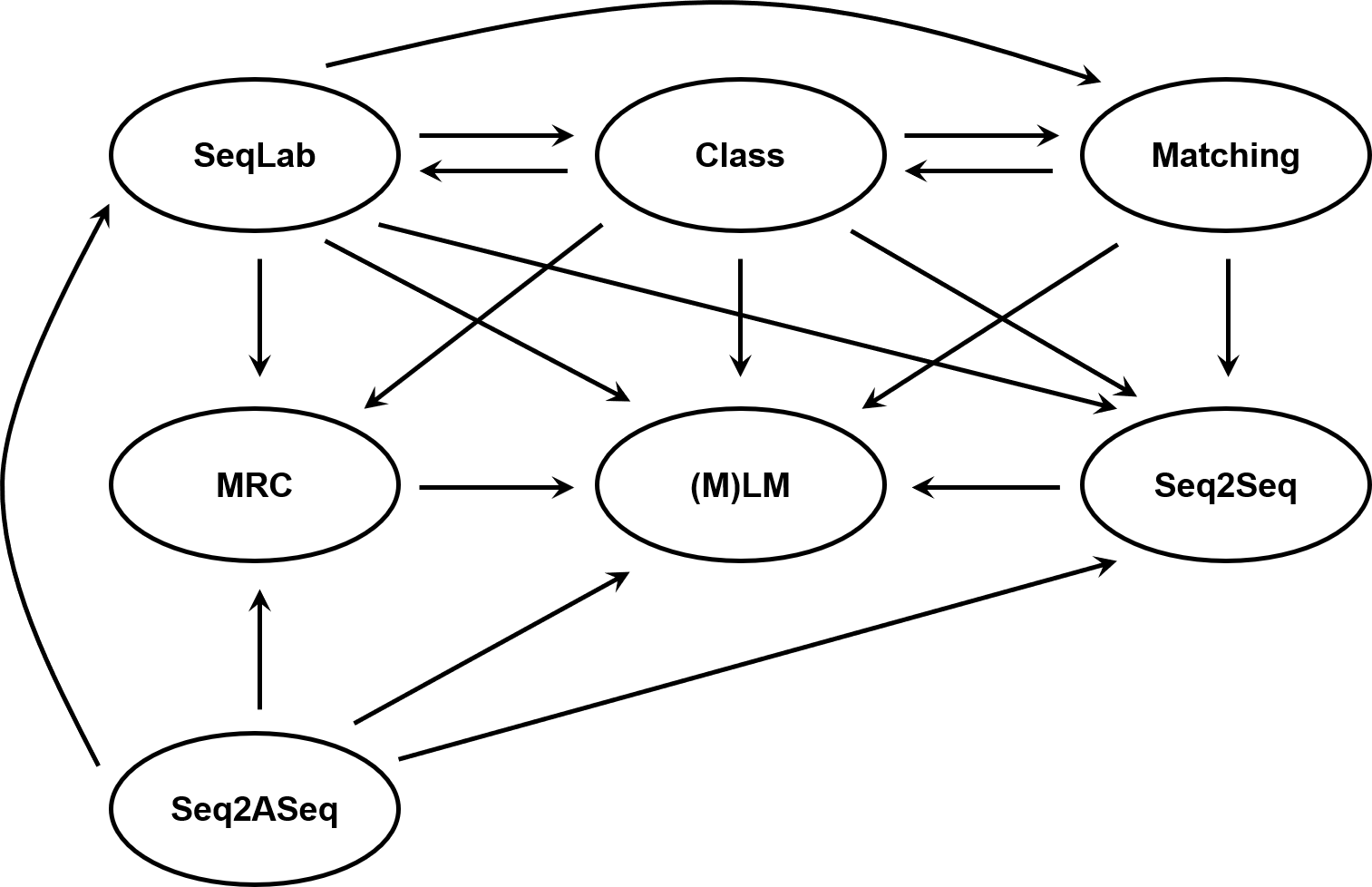
Paradigm shift in NLP tasks
We collect the papers of paradigm shift in the table below, which is an extension of the Table 1 in our original paper. This table will be constantly updated.
Trends
To intuitively depict the trend of paradigm shift in NLP, we also draw an interactive Sankey diagram, which is an extension of the Figure 2 in our original paper. Also, this diagram is constantly updated as the table above changed.
Contributing
This line of research is difficult to be comprehensively surveyed, so welcome any additions, modifications, and suggestions! Please feel free to submit pull request or directly contact me.
Citation
If you find this webpage or the paper helpful to your research, please cite our paper:
@article{sun2021paradigmshift,
title={Paradigm Shift in Natural Language Processing},
author={Tianxiang Sun and Xiangyang Liu and Xipeng Qiu and Xuanjing Huang},
journal={arXiv preprint arXiv:2109.12575},
year={2021}
}

 110 Dec 03, 2022
110 Dec 03, 2022
 0 Nov 29, 2022
0 Nov 29, 2022
 186 Dec 24, 2022
186 Dec 24, 2022
 223 Jan 02, 2023
223 Jan 02, 2023
 0 Feb 26, 2022
0 Feb 26, 2022
 564 Jan 08, 2023
564 Jan 08, 2023
 8 Aug 11, 2022
8 Aug 11, 2022
 8 Nov 30, 2022
8 Nov 30, 2022
 4 Oct 07, 2022
4 Oct 07, 2022
 75 Dec 05, 2022
75 Dec 05, 2022
 26 Dec 05, 2022
26 Dec 05, 2022
 305 Dec 22, 2022
305 Dec 22, 2022
 26 Dec 25, 2022
26 Dec 25, 2022
 77 Dec 27, 2022
77 Dec 27, 2022
 0 Aug 13, 2022
0 Aug 13, 2022
 26 May 27, 2022
26 May 27, 2022
 183 Dec 14, 2022
183 Dec 14, 2022
 798 Dec 30, 2022
798 Dec 30, 2022
 7 Sep 17, 2022
7 Sep 17, 2022
 847 Dec 19, 2022
847 Dec 19, 2022