Label-Efficient Semantic Segmentation with Diffusion Models
Official implementation of the paper Label-Efficient Semantic Segmentation with Diffusion Models
This code is based on datasetGAN and guided-diffusion.
Note: use --recurse-submodules when clone.
Overview
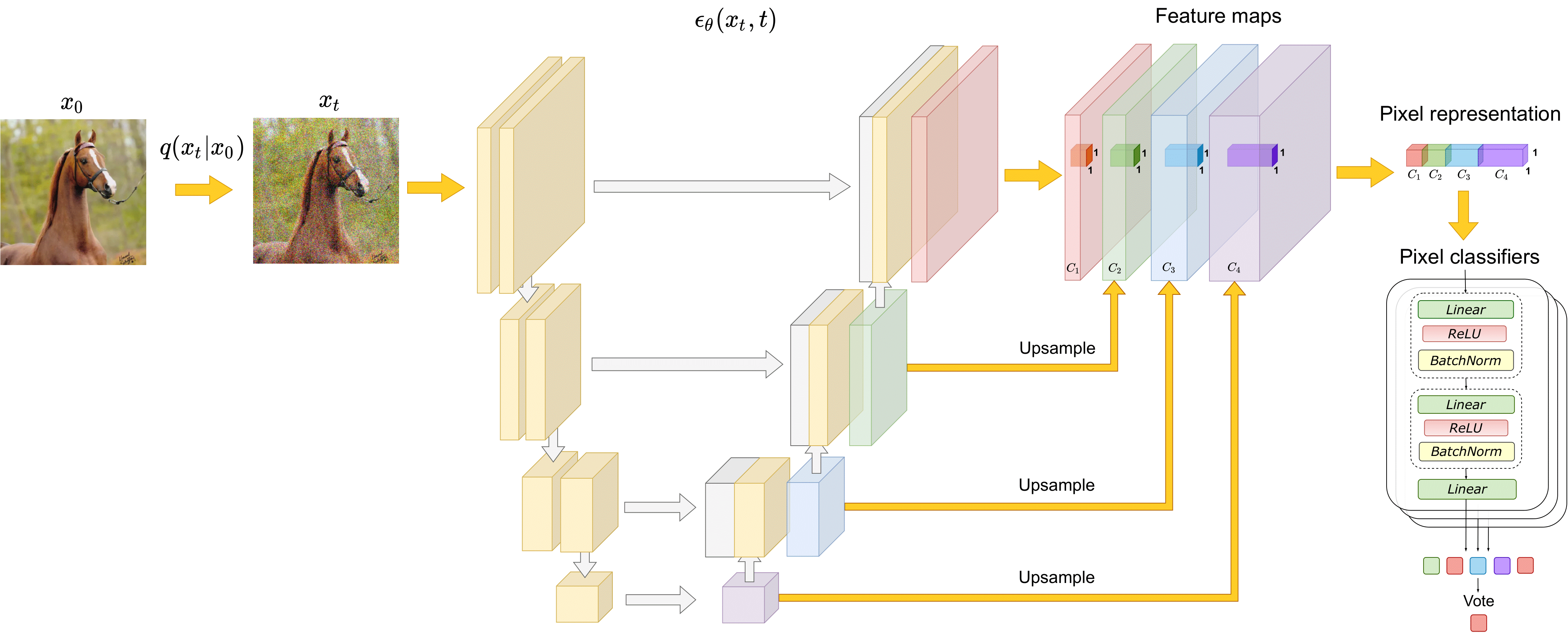
The paper investigates the representations learned by the state-of-the-art DDPMs and shows that they capture high-level semantic information valuable for downstream vision tasks. We design a simple segmentation approach that exploits these representations and outperforms the alternatives in the few-shot operating point in the context of semantic segmentation.
Dependencies
- Python >= 3.7
- Packages: see
requirements.txt
Datasets
The evaluation is performed on 6 collected datasets with a few annotated images in the training set: Bedroom-18, FFHQ-34, Cat-15, Horse-21, CelebA-19 and ADE-Bedroom-30. The number corresponds to the number of semantic classes.
datasets.tar.gz (~47Mb)
DDPM
Pretrained DDPMs
The models trained on LSUN are adopted from guided-diffusion. FFHQ-256 is trained by ourselves using the same model parameters as for the LSUN models.
LSUN-Bedroom: lsun_bedroom.pt
FFHQ-256: ffhq.pt
LSUN-Cat: lsun_cat.pt
LSUN-Horse: lsun_horse.pt
Run
- Download the datasets:
bash datasets/download_datasets.sh - Download the DDPM checkpoint:
bash checkpoints/ddpm/download_checkpoint.sh - Check paths in
experiments//ddpm.json - Run:
bash scripts/ddpm/train_interpreter.sh
Available checkpoint names: lsun_bedroom, ffhq, lsun_cat, lsun_horse
Available dataset names: bedroom_28, ffhq_34, cat_15, horse_21, celeba_19, ade_bedroom_30
How to improve the performance
- Set input_activations=true in
experiments/./ddpm.json
In this case, the feature dimension is 18432. - Tune for a particular task what diffusion steps and UNet blocks to use.
DatasetDDPM
Synthetic datasets
To download DDPM-produced synthetic datasets (50000 samples, ~7Gb):
bash synthetic-datasets/gan/download_synthetic_dataset.sh
Run | Option #1
- Download the synthetic dataset:
bash synthetic-datasets/ddpm/download_synthetic_dataset.sh - Check paths in
experiments//datasetDDPM.json - Run:
bash scripts/datasetDDPM/train_deeplab.sh
Run | Option #2
-
Download the datasets:
bash datasets/download_datasets.sh -
Download the DDPM checkpoint:
bash checkpoints/ddpm/download_checkpoint.sh -
Check paths in
experiments//datasetDDPM.json -
Train an interpreter on a few DDPM-produced annotated samples:
bash scripts/datasetDDPM/train_interpreter.sh -
Generate a synthetic dataset:
bash scripts/datasetDDPM/generate_dataset.sh
Please specify the hyperparameters in this script for the available resources.
On 8xA100 80Gb, it takes about 12 hours to generate 10000 samples. -
Run:
bash scripts/datasetDDPM/train_deeplab.sh
One needs to specify the path to the generated data. See comments in the script.
Available checkpoint names: lsun_bedroom, ffhq, lsun_cat, lsun_horse
Available dataset names: bedroom_28, ffhq_34, cat_15, horse_21
SwAV
Pretrained SwAVs
We pretrain SwAV models using the official implementation on the LSUN and FFHQ-256 datasets:
LSUN-Bedroom: lsun_bedroom.pth
FFHQ-256: ffhq.pth
LSUN-Cat: lsun_cat.pth
LSUN-Horse: lsun_horse.pth
Training setup:
| Dataset | epochs | batch-size | multi-crop | num-prototypes |
|---|---|---|---|---|
| LSUN | 200 | 1792 | 2x256 + 6x108 | 1000 |
| FFHQ-256 | 400 | 2048 | 2x224 + 6x96 | 200 |
Run
- Download the datasets:
bash datasets/download_datasets.sh - Download the SwAV checkpoint:
bash checkpoints/swav/download_checkpoint.sh - Check paths in
experiments//swav.json - Run:
bash scripts/swav/train_interpreter.sh
Available checkpoint names: lsun_bedroom, ffhq, lsun_cat, lsun_horse
Available dataset names: bedroom_28, ffhq_34, cat_15, horse_21, celeba_19, ade_bedroom_30
DatasetGAN
Opposed to the official implementation, more recent StyleGAN2(-ADA) models are used.
Synthetic datasets
To download GAN-produced synthetic datasets (50000 samples):
bash synthetic-datasets/gan/download_synthetic_dataset.sh
Run
Since we almost fully adopt the official implementation, we don't provide our reimplementation here. However, one can still reproduce our results:
- Download the synthetic dataset:
bash synthetic-datasets/gan/download_synthetic_dataset.sh - Change paths in
experiments//datasetDDPM.json - Change paths and run:
bash scripts/datasetDDPM/train_deeplab.sh
Available dataset names: bedroom_28, ffhq_34, cat_15, horse_21
Results
- Performance in terms of mean IoU:
| Method | Bedroom-28 | FFHQ-34 | Cat-15 | Horse-21 | CelebA-19 | ADE-Bedroom-30 |
|---|---|---|---|---|---|---|
| ALAE | 20.0 ± 1.0 | 48.1 ± 1.3 | -- | -- | 49.7 ± 0.7 | 15.0 ± 0.5 |
| VDVAE | -- | 57.3 ± 1.1 | -- | -- | 54.1 ± 1.0 | -- |
| GAN Inversion | 13.9 ± 0.6 | 51.7 ± 0.8 | 21.4 ± 1.7 | 17.7 ± 0.4 | 51.5 ± 2.3 | 11.1 ± 0.2 |
| GAN Encoder | 22.4 ± 1.6 | 53.9 ± 1.3 | 32.0 ± 1.8 | 26.7 ± 0.7 | 53.9 ± 0.8 | 15.7 ± 0.3 |
| SwAV | 41.0 ± 2.3 | 54.7 ± 1.4 | 44.1 ± 2.1 | 51.7 ± 0.5 | 53.2 ± 1.0 | 30.3 ± 1.5 |
| DatasetGAN | 31.3 ± 2.7 | 57.0 ± 1.0 | 36.5 ± 2.3 | 45.4 ± 1.4 | -- | -- |
| DatasetDDPM | 46.9 ± 2.8 | 56.0 ± 0.9 | 45.4 ± 2.8 | 60.4 ± 1.2 | -- | -- |
| DDPM | 46.1 ± 1.9 | 57.0 ± 1.4 | 52.3 ± 3.0 | 63.1 ± 0.9 | 57.0 ± 1.0 | 32.3 ± 1.5 |
- Examples of segmentation masks predicted by the DDPM-based method:

Cite
@misc{baranchuk2021labelefficient,
title={Label-Efficient Semantic Segmentation with Diffusion Models},
author={Dmitry Baranchuk and Ivan Rubachev and Andrey Voynov and Valentin Khrulkov and Artem Babenko},
year={2021},
eprint={2112.03126},
archivePrefix={arXiv},
primaryClass={cs.CV}
}

 10 Oct 11, 2022
10 Oct 11, 2022
 473 Jan 09, 2023
473 Jan 09, 2023
 11 Nov 30, 2022
11 Nov 30, 2022
 186 Nov 24, 2022
186 Nov 24, 2022
 0 Dec 27, 2021
0 Dec 27, 2021
 1 Nov 23, 2021
1 Nov 23, 2021
 9 Jun 20, 2022
9 Jun 20, 2022
 94 Dec 12, 2022
94 Dec 12, 2022
 152 Oct 27, 2022
152 Oct 27, 2022
 281 Dec 22, 2022
281 Dec 22, 2022
 132 Dec 18, 2022
132 Dec 18, 2022
 169 Dec 22, 2022
169 Dec 22, 2022
 52 Nov 21, 2022
52 Nov 21, 2022
 11 Sep 10, 2022
11 Sep 10, 2022
 151 Dec 14, 2022
151 Dec 14, 2022
 13 May 11, 2022
13 May 11, 2022
 1 Mar 09, 2022
1 Mar 09, 2022
 58 Dec 21, 2022
58 Dec 21, 2022
 85 Dec 22, 2022
85 Dec 22, 2022
 11 Dec 22, 2022
11 Dec 22, 2022