BMS-Molecular-Translation
Introduction
This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got bronze medals in this competition. Significant part of code was originated from Y.Nakama's notebook
This competition was about image-to-text translation of images with molecular skeletal strucutures to InChI chemical formula identifiers.

InChI=1S/C16H13Cl2NO3/c1-10-2-4-11(5-3-10)16(21)22-9-15(20)19-14-8-12(17)6-7-13(14)18/h2-8H,9H2,1H3,(H,19,20)
Solution
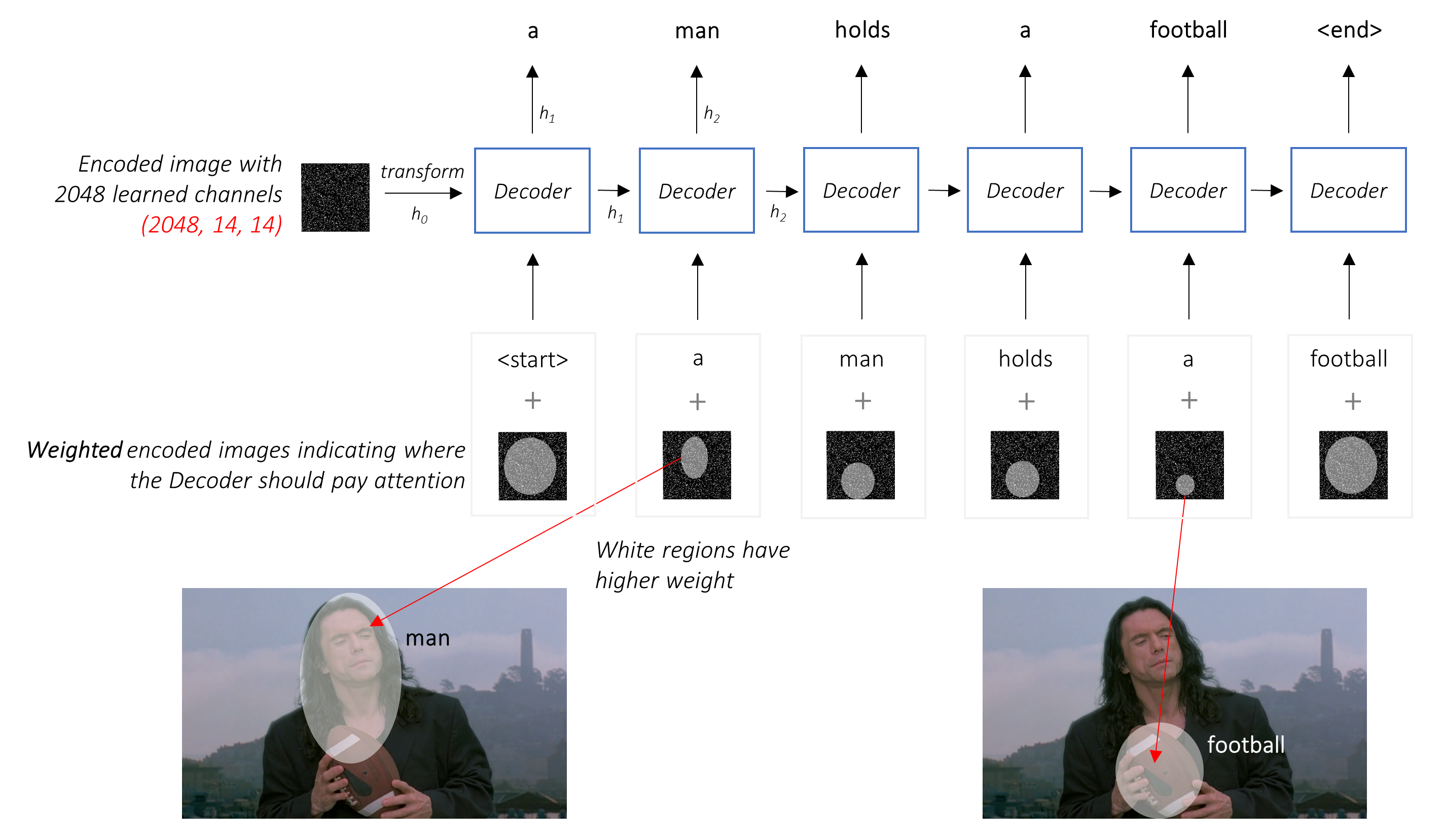
General Encoder-Decoder concept
Most participants used CNN encoder to acquire features with decoder (LSTM/GRU/Transformer) to get text sequences. That's a casual approach to image captioning problem.
Pseudo-labelling with InChI validation using RDKit
RDKit is an open source toolkit for cheminformatics and it was quite useful while solving the problem. When we trained our first model, it scored around 7-8 on public leaderboard and we decided to make pseudo-labelling on test data. However, in common scenario you get a significant amount of wrong predictions in your extended training set from pseudo-labelling. With RDKit we validated all of our predicted formulas and select around 800k correct samples. Lack of wrong labels in pseudo labels improved the score.
Predictions normalization
This notebook tells about InChI normalization
Blending
Finally, we blended ~20 predictions from 2 models (mostly from different epochs) using RDKit validation to choose only formulas which have possible InChI structure.

 113 Dec 15, 2022
113 Dec 15, 2022
 1.5k Jan 02, 2023
1.5k Jan 02, 2023
 24 Sep 11, 2022
24 Sep 11, 2022
 94 Dec 08, 2022
94 Dec 08, 2022
 748 Jan 06, 2023
748 Jan 06, 2023
 3.7k Jan 02, 2023
3.7k Jan 02, 2023
 287 Dec 14, 2022
287 Dec 14, 2022
 613 Jan 07, 2023
613 Jan 07, 2023
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
 214 Nov 24, 2022
214 Nov 24, 2022
 1 Mar 14, 2022
1 Mar 14, 2022
 1.6k Dec 29, 2022
1.6k Dec 29, 2022
 29.8k Jan 02, 2023
29.8k Jan 02, 2023
 61 Dec 10, 2022
61 Dec 10, 2022
 10.4k Jan 09, 2023
10.4k Jan 09, 2023
 610 Sep 07, 2022
610 Sep 07, 2022
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
 50 Nov 08, 2022
50 Nov 08, 2022
 26 Oct 17, 2022
26 Oct 17, 2022
 7 Sep 22, 2022
7 Sep 22, 2022