MPViT : Multi-Path Vision Transformer for Dense Prediction
This repository inlcudes official implementations and model weights for MPViT.
MPViT : Multi-Path Vision Transformer for Dense Prediction
🏛️ ️️🏫 Youngwan Lee,🏛️ ️️Jonghee Kim,🏫 Jeff Willette,🏫 Sung Ju Hwang
ETRI🏛️ ️, KAIST🏫
Abstract
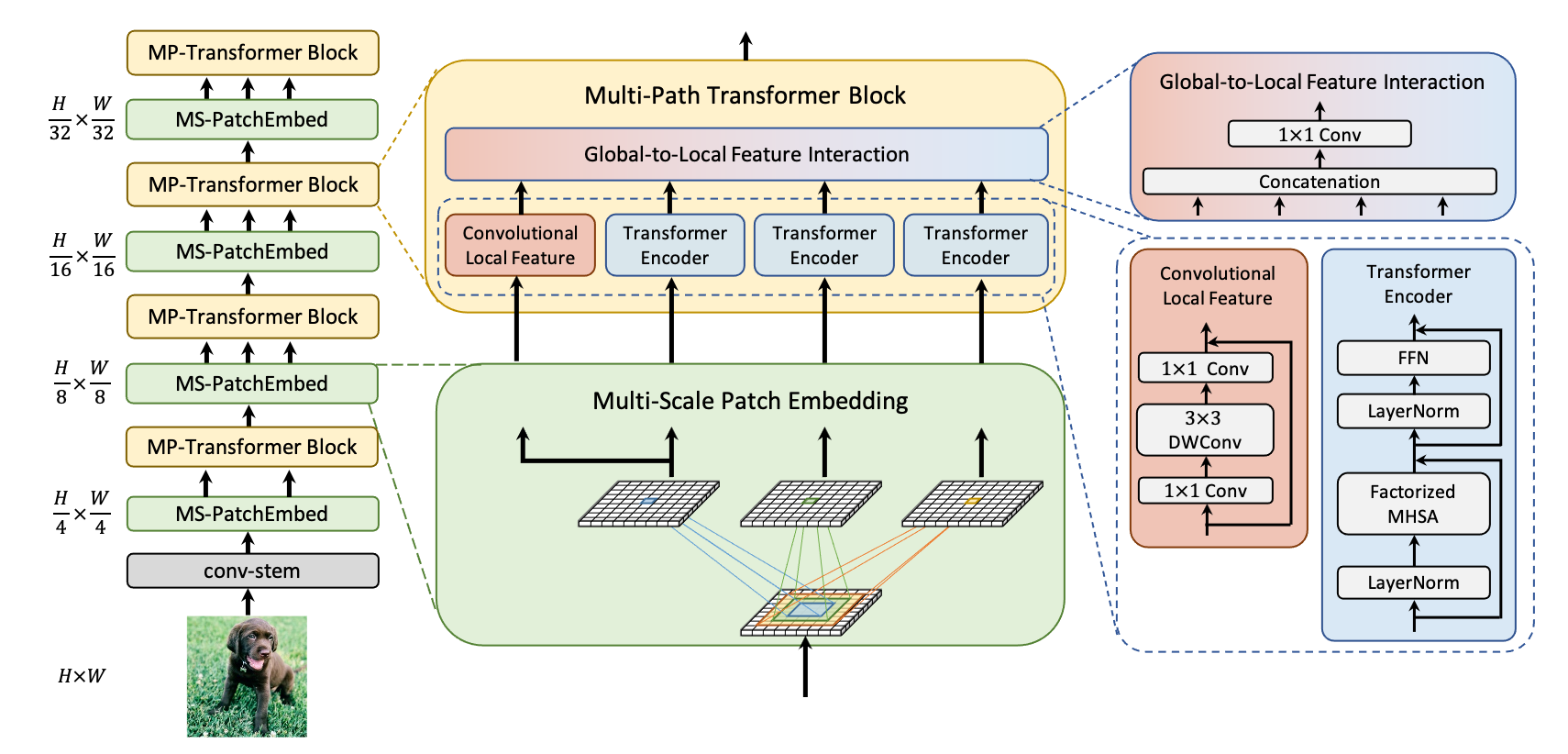
We explore multi-scale patch embedding and multi-path structure, constructing the Multi-Path Vision Transformer (MPViT). MPViT embeds features of the same size (i.e., sequence length) with patches of different scales simultaneously by using overlapping convolutional patch embedding. Tokens of different scales are then independently fed into the Transformer encoders via multiple paths and the resulting features are aggregated, enabling both fine and coarse feature representations at the same feature level. Thanks to the diverse and multi-scale feature representations, our MPViTs scaling from Tiny(5M) to Base(73M) consistently achieve superior performance over state-of-the-art Vision Transformers on ImageNet classification, object detection, instance segmentation, and semantic segmentation. These extensive results demonstrate that MPViT can serve as a versatile backbone network for various vision tasks.
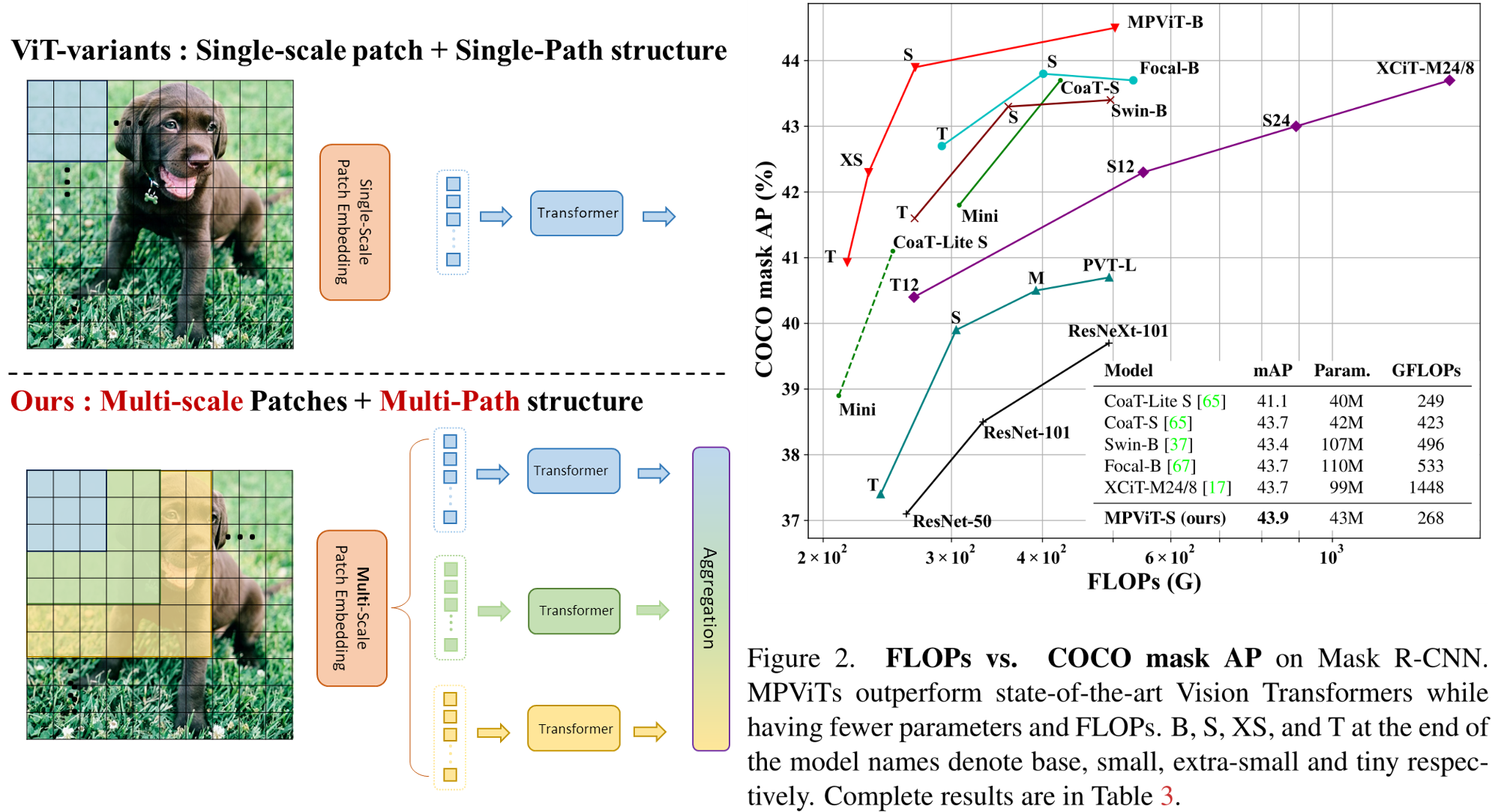
Main results on ImageNet-1K
| model | resolution | [email protected] | #params | FLOPs | weight |
|---|---|---|---|---|---|
| MPViT-T | 224x224 | 78.2 | 5.8M | 1.6G | weight |
| MPViT-XS | 224x224 | 80.9 | 10.5M | 2.9G | weight |
| MPViT-S | 224x224 | 83.0 | 22.8M | 4.7G | weight |
| MPViT-B | 224x224 | 84.3 | 74.8M | 16.4G | weight |
Main results on COCO object detection
Please refer to detectron2/ for the details.
| Backbone | Method | lr Schd | box mAP | mask mAP | #params | FLOPS | weight |
|---|---|---|---|---|---|---|---|
| MPViT-T | RetinaNet | 1x | 41.8 | - | 17M | 196G | model | metrics |
| MPViT-XS | RetinaNet | 1x | 43.8 | - | 20M | 211G | model | metrics |
| MPViT-S | RetinaNet | 1x | 45.7 | - | 32M | 248G | model | metrics |
| MPViT-B | RetinaNet | 1x | 47.0 | - | 85M | 482G | model | metrics |
| MPViT-T | RetinaNet | MS+3x | 44.4 | - | 17M | 196G | model | metrics |
| MPViT-XS | RetinaNet | MS+3x | 46.1 | - | 20M | 211G | model | metrics |
| MPViT-S | RetinaNet | MS+3x | 47.6 | - | 32M | 248G | model | metrics |
| MPViT-B | RetinaNet | MS+3x | 48.3 | - | 85M | 482G | model | metrics |
| MPViT-T | Mask R-CNN | 1x | 42.2 | 39.0 | 28M | 216G | model | metrics |
| MPViT-XS | Mask R-CNN | 1x | 44.2 | 40.4 | 30M | 231G | model | metrics |
| MPViT-S | Mask R-CNN | 1x | 46.4 | 42.4 | 43M | 268G | model | metrics |
| MPViT-B | Mask R-CNN | 1x | 48.2 | 43.5 | 95M | 503G | model | metrics |
| MPViT-T | Mask R-CNN | MS+3x | 44.8 | 41.0 | 28M | 216G | model | metrics |
| MPViT-XS | Mask R-CNN | MS+3x | 46.6 | 42.3 | 30M | 231G | model | metrics |
| MPViT-S | Mask R-CNN | MS+3x | 48.4 | 43.9 | 43M | 268G | model | metrics |
| MPViT-B | Mask R-CNN | MS+3x | 49.5 | 44.5 | 95M | 503G | model | metrics |
Deformable-DETR
All models are trained using the same training recipe.
Please refer to deformable_detr/ for the details.
| backbone | box mAP | epochs | link |
|---|---|---|---|
| ResNet-50 | 44.5 | 50 | - |
| CoaT-lite S | 47.0 | 50 | link |
| CoaT-S | 48.4 | 50 | link |
| MPViT-S | 49.0 | 50 | link |
Main results on ADE20K Semantic segmentation
All model are trained using ImageNet-1K pretrained weight.
Please refer to semantic_segmentation/ for the details.
| Backbone | Method | Crop Size | Lr Schd | mIoU | #params | FLOPs | weight |
|---|---|---|---|---|---|---|---|
| MPViT-S | UperNet | 512x512 | 160K | 48.3 | 52M | 943G | weight |
| MPViT-B | UperNet | 512x512 | 160K | 50.3 | 105M | 1185G | weight |
Getting Started
pytorch==1.7.0 torchvision==0.8.1 cuda==10.1 libraries on NVIDIA V100 GPUs. If you use different versions of cuda, you may obtain different accuracies, but the differences are negligible.
- For Image Classification, please see GET_STARTED.md.
- For Object Detection and Instance Segmentation, please see OBJECT_DETECTION.md.
- For Semantic Segmentation, please see semantic_segmentation/README.md.
Acknowledgement
This repository is built using the Timm library, DeiT, CoaT, Detectron2, mmsegmentation repositories.
This work was supported by Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (No. 2020-0-00004, Development of Previsional Intelligence based on Long-term Visual Memory Network and No. 2014-3-00123, Development of High Performance Visual BigData Discovery Platform for Large-Scale Realtime Data Analysis).
License
Please refer to MPViT LSA.
Citing MPViT
@article{lee2021mpvit,
title={MPViT: Multi-Path Vision Transformer for Dense Prediction},
author={Youngwan Lee and Jonghee Kim and Jeff Willette and Sung Ju Hwang},
year={2021},
journal={arXiv preprint arXiv:2112.11010}
}

 6 Oct 28, 2022
6 Oct 28, 2022
 21 Nov 25, 2022
21 Nov 25, 2022
 18 Aug 11, 2022
18 Aug 11, 2022
 246 Dec 19, 2022
246 Dec 19, 2022
 16 Dec 22, 2022
16 Dec 22, 2022
 30 Dec 16, 2022
30 Dec 16, 2022
 1 Jun 02, 2022
1 Jun 02, 2022
 0 Jan 02, 2022
0 Jan 02, 2022
 34 Jul 22, 2022
34 Jul 22, 2022
 779 Jan 02, 2023
779 Jan 02, 2023
 0 Oct 21, 2022
0 Oct 21, 2022
 1 Jan 16, 2022
1 Jan 16, 2022
 12 Dec 29, 2022
12 Dec 29, 2022
 1 Jan 16, 2022
1 Jan 16, 2022
 2 Dec 19, 2022
2 Dec 19, 2022
 3 Mar 01, 2022
3 Mar 01, 2022
 0 Sep 06, 2022
0 Sep 06, 2022
 267 Dec 17, 2022
267 Dec 17, 2022
 1 Nov 19, 2021
1 Nov 19, 2021
 3 May 08, 2022
3 May 08, 2022