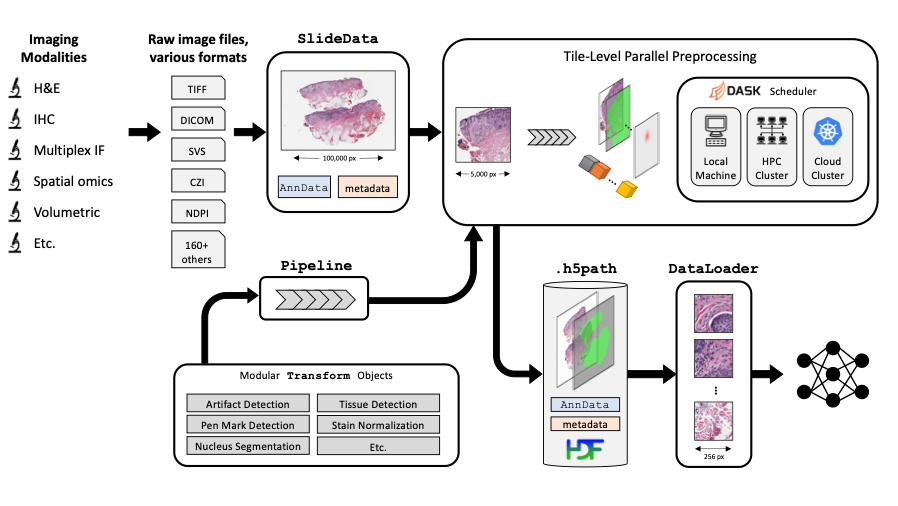
If one tries to install pathml after a previously failed installation attempt, one runs into the following error, which I think is due to using cached files. One suggested solution (for just torch) is to do pip --no-cache-dir install torchvision, but i dont know if this is going to solve the issue and how to integrate this into intalling pathml as a whole, without installing each dependency one by one.
(pathml) [email protected]:~$ pip install pathml
Collecting pathml
Using cached pathml-2.0.4-py3-none-any.whl (83 kB)
Collecting scipy
Using cached scipy-1.8.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (41.6 MB)
Collecting python-bioformats>=4.0.0
Using cached python_bioformats-4.0.5-py3-none-any.whl (41.4 MB)
Collecting scikit-image
Using cached scikit_image-0.19.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (13.8 MB)
Collecting scikit-learn
Using cached scikit_learn-1.0.2-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (26.7 MB)
Requirement already satisfied: pip in /opt/conda/envs/pathml/lib/python3.8/site-packages (from pathml) (22.0.3)
Collecting openslide-python
Using cached openslide-python-1.1.2.tar.gz (316 kB)
Preparing metadata (setup.py) ... done
Collecting dask[distributed]
Using cached dask-2022.1.1-py3-none-any.whl (1.1 MB)
Collecting pandas
Using cached pandas-1.4.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (11.7 MB)
Collecting matplotlib
Using cached matplotlib-3.5.1-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.whl (11.3 MB)
Collecting anndata>=0.7.6
Using cached anndata-0.7.8-py3-none-any.whl (91 kB)
Requirement already satisfied: numpy>=1.16.4 in /opt/conda/envs/pathml/lib/python3.8/site-packages (from pathml) (1.22.2)
Collecting h5py
Using cached h5py-3.6.0-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (4.5 MB)
Collecting opencv-contrib-python
Using cached opencv_contrib_python-4.5.5.62-cp36-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (66.6 MB)
Collecting pydicom
Using cached pydicom-2.2.2-py3-none-any.whl (2.0 MB)
Collecting torch
SystemError: deallocated bytearray object has exported buffers
ERROR: Exception:
Traceback (most recent call last):
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/cli/base_command.py", line 167, in exc_logging_wrapper
status = run_func(*args)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/cli/req_command.py", line 205, in wrapper
return func(self, options, args)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/commands/install.py", line 339, in run
requirement_set = resolver.resolve(
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/resolution/resolvelib/resolver.py", line 94, in resolve
result = self._result = resolver.resolve(
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/resolvelib/resolvers.py", line 481, in resolve
state = resolution.resolve(requirements, max_rounds=max_rounds)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/resolvelib/resolvers.py", line 373, in resolve
failure_causes = self._attempt_to_pin_criterion(name)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/resolvelib/resolvers.py", line 213, in _attempt_to_pin_criterion
criteria = self._get_updated_criteria(candidate)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/resolvelib/resolvers.py", line 204, in _get_updated_criteria
self._add_to_criteria(criteria, requirement, parent=candidate)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/resolvelib/resolvers.py", line 172, in _add_to_criteria
if not criterion.candidates:
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/resolvelib/structs.py", line 151, in __bool__
return bool(self._sequence)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/resolution/resolvelib/found_candidates.py", line 155, in __bool__
return any(self)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/resolution/resolvelib/found_candidates.py", line 143, in <genexpr>
return (c for c in iterator if id(c) not in self._incompatible_ids)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/resolution/resolvelib/found_candidates.py", line 47, in _iter_built
candidate = func()
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/resolution/resolvelib/factory.py", line 215, in _make_candidate_from_link
self._link_candidate_cache[link] = LinkCandidate(
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/resolution/resolvelib/candidates.py", line 288, in __init__
super().__init__(
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/resolution/resolvelib/candidates.py", line 158, in __init__
self.dist = self._prepare()
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/resolution/resolvelib/candidates.py", line 227, in _prepare
dist = self._prepare_distribution()
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/resolution/resolvelib/candidates.py", line 299, in _prepare_distribution
return preparer.prepare_linked_requirement(self._ireq, parallel_builds=True)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/operations/prepare.py", line 487, in prepare_linked_requirement
return self._prepare_linked_requirement(req, parallel_builds)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/operations/prepare.py", line 532, in _prepare_linked_requirement
local_file = unpack_url(
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/operations/prepare.py", line 214, in unpack_url
file = get_http_url(
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/operations/prepare.py", line 94, in get_http_url
from_path, content_type = download(link, temp_dir.path)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/network/download.py", line 133, in __call__
resp = _http_get_download(self._session, link)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/network/download.py", line 116, in _http_get_download
resp = session.get(target_url, headers=HEADERS, stream=True)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/requests/sessions.py", line 542, in get
return self.request('GET', url, **kwargs)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_internal/network/session.py", line 454, in request
return super().request(method, url, *args, **kwargs)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/requests/sessions.py", line 529, in request
resp = self.send(prep, **send_kwargs)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/requests/sessions.py", line 645, in send
r = adapter.send(request, **kwargs)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/cachecontrol/adapter.py", line 48, in send
cached_response = self.controller.cached_request(request)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/cachecontrol/controller.py", line 151, in cached_request
resp = self.serializer.loads(request, cache_data)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/cachecontrol/serialize.py", line 95, in loads
return getattr(self, "_loads_v{}".format(ver))(request, data)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/cachecontrol/serialize.py", line 182, in _loads_v4
cached = msgpack.loads(data, raw=False)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/msgpack/fallback.py", line 128, in unpackb
ret = unpacker._unpack()
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/msgpack/fallback.py", line 592, in _unpack
ret[key] = self._unpack(EX_CONSTRUCT)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/msgpack/fallback.py", line 592, in _unpack
ret[key] = self._unpack(EX_CONSTRUCT)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/msgpack/fallback.py", line 546, in _unpack
typ, n, obj = self._read_header()
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/msgpack/fallback.py", line 488, in _read_header
obj = self._read(n)
File "/opt/conda/envs/pathml/lib/python3.8/site-packages/pip/_vendor/msgpack/fallback.py", line 407, in _read
ret = self._buffer[i : i + n]
MemoryError
bug















 18 Nov 21, 2022
18 Nov 21, 2022
 553 Dec 27, 2022
553 Dec 27, 2022
 2 Jan 15, 2022
2 Jan 15, 2022
 569 Dec 29, 2022
569 Dec 29, 2022
 266 Nov 24, 2022
266 Nov 24, 2022
 13 Jan 07, 2023
13 Jan 07, 2023
 800 Dec 05, 2022
800 Dec 05, 2022
 15 Dec 09, 2022
15 Dec 09, 2022
 2.5k Jan 06, 2023
2.5k Jan 06, 2023
 7 Oct 20, 2022
7 Oct 20, 2022
 23 Dec 16, 2022
23 Dec 16, 2022
 125 Dec 26, 2022
125 Dec 26, 2022
 189 Jan 04, 2023
189 Jan 04, 2023
 182 Dec 27, 2022
182 Dec 27, 2022
 62 Dec 21, 2022
62 Dec 21, 2022
 2.7k Jan 01, 2023
2.7k Jan 01, 2023
 2 Aug 21, 2022
2 Aug 21, 2022
 64 Dec 16, 2022
64 Dec 16, 2022
 2 May 14, 2022
2 May 14, 2022
 33 Jan 03, 2023
33 Jan 03, 2023