
About
The ROOT system provides a set of OO frameworks with all the functionality needed to handle and analyze large amounts of data in a very efficient way. Having the data defined as a set of objects, specialized storage methods are used to get direct access to the separate attributes of the selected objects, without having to touch the bulk of the data. Included are histograming methods in an arbitrary number of dimensions, curve fitting, function evaluation, minimization, graphics and visualization classes to allow the easy setup of an analysis system that can query and process the data interactively or in batch mode, as well as a general parallel processing framework, PROOF, that can considerably speed up an analysis.
Thanks to the built-in C++ interpreter cling, the command, the scripting and the programming language are all C++. The interpreter allows for fast prototyping of the macros since it removes the time consuming compile/link cycle. It also provides a good environment to learn C++. If more performance is needed the interactively developed macros can be compiled using a C++ compiler via a machine independent transparent compiler interface called ACliC.
The system has been designed in such a way that it can query its databases in parallel on clusters of workstations or many-core machines. ROOT is an open system that can be dynamically extended by linking external libraries. This makes ROOT a premier platform on which to build data acquisition, simulation and data analysis systems.
Cite
When citing ROOT, please use both the reference reported below and the DOI specific to your ROOT version available on Zenodo . For example, you can copy-paste and fill in the following citation:
Rene Brun and Fons Rademakers, ROOT - An Object Oriented Data Analysis Framework,
Proceedings AIHENP'96 Workshop, Lausanne, Sep. 1996,
Nucl. Inst. & Meth. in Phys. Res. A 389 (1997) 81-86.
See also "ROOT" [software], Release vX.YY/ZZ, dd/mm/yyyy,
(Select the right link for your release here: https://zenodo.org/search?page=1&size=20&q=conceptrecid:848818&all_versions&sort=-version).
Live Demo for CERN Users
Screenshots
These screenshots shows some of the plots (produced using ROOT) presented when the Higgs boson discovery was announced at CERN:
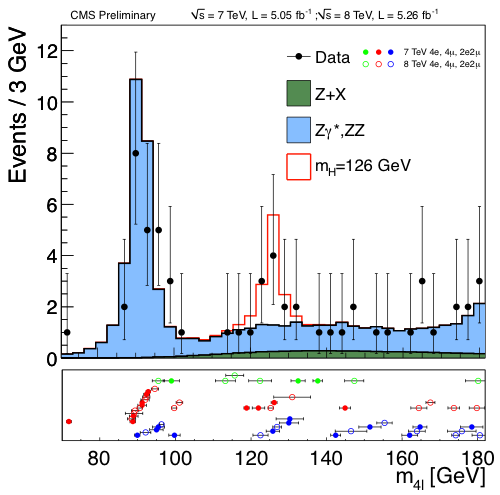
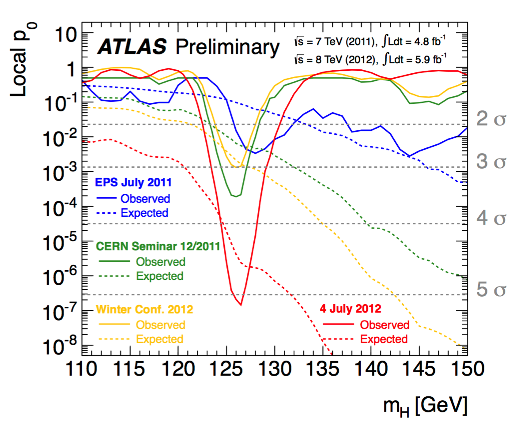
See more screenshots on our gallery.
Installation and Getting Started
See https://root.cern/install for installation instructions. For instructions on how to build ROOT from these source files, see https://root.cern/install/build_from_source.
Our "Getting started with ROOT" page is then the perfect place to get familiar with ROOT.

![[Exp PyROOT] Build PyROOT with multiple Python versions](https://avatars.githubusercontent.com/u/26309531?v=4)

![[cxxmodules] Fix failing runtime_cxxmodules tests by preloading modules](https://avatars.githubusercontent.com/u/12247908?v=4)
![[cmake] use only source dirs as include paths when building ROOT](https://avatars.githubusercontent.com/u/4936580?v=4)
![[VecOps] RVec 2.0: small buffer optimization based on LLVM SmallVector](https://avatars.githubusercontent.com/u/10999034?v=4)
![[CMake] Add automatic FAILREGEX for gtests](https://avatars.githubusercontent.com/u/16205615?v=4)


![[RF] Fix and improvements in `testSumW2Error`](https://avatars.githubusercontent.com/u/6578603?v=4)

 1.5k Dec 27, 2022
1.5k Dec 27, 2022
 4 Dec 28, 2021
4 Dec 28, 2021
 6 Jun 07, 2022
6 Jun 07, 2022
 21 Aug 30, 2022
21 Aug 30, 2022
 1 Dec 03, 2021
1 Dec 03, 2021
 367 Dec 25, 2022
367 Dec 25, 2022
 1 Dec 29, 2021
1 Dec 29, 2021
 2 Mar 22, 2022
2 Mar 22, 2022
 1 Jan 02, 2022
1 Jan 02, 2022
 3 Feb 12, 2022
3 Feb 12, 2022
 1.4k Dec 31, 2022
1.4k Dec 31, 2022
 1.2k Dec 27, 2022
1.2k Dec 27, 2022
 2 Feb 13, 2022
2 Feb 13, 2022
 1 Jan 25, 2022
1 Jan 25, 2022
 2 Feb 16, 2022
2 Feb 16, 2022
 5 Mar 19, 2022
5 Mar 19, 2022
 1.6k Jan 07, 2023
1.6k Jan 07, 2023
 25 Dec 14, 2022
25 Dec 14, 2022
 1 Jan 06, 2022
1 Jan 06, 2022
 23 Dec 16, 2022
23 Dec 16, 2022