PyTorch SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
Blog post with full documentation: Exploring SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
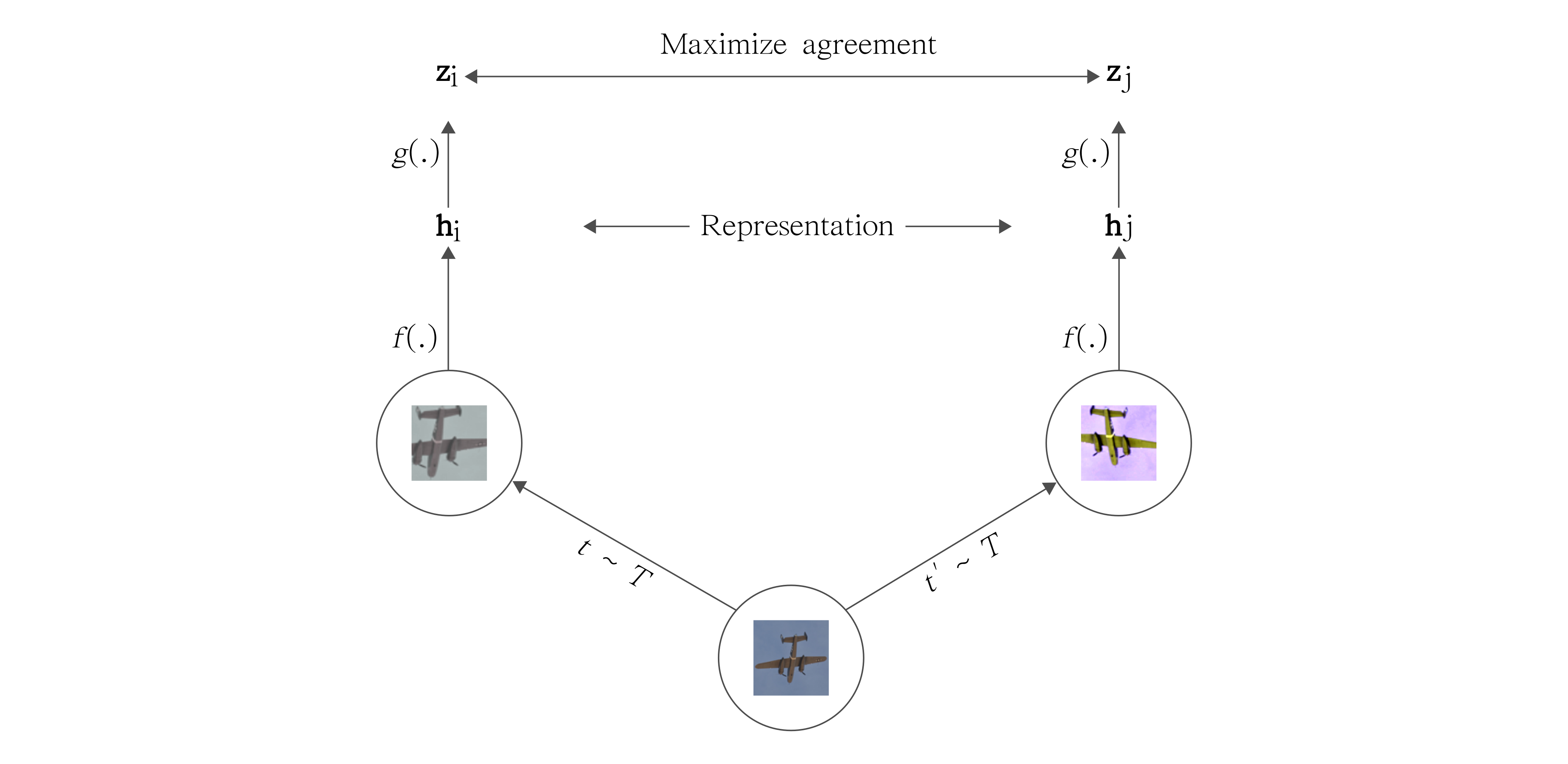
See also PyTorch Implementation for BYOL - Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning.
Installation
$ conda env create --name simclr --file env.yml
$ conda activate simclr
$ python run.py
Config file
Before running SimCLR, make sure you choose the correct running configurations. You can change the running configurations by passing keyword arguments to the run.py file.
$ python run.py -data ./datasets --dataset-name stl10 --log-every-n-steps 100 --epochs 100
If you want to run it on CPU (for debugging purposes) use the --disable-cuda option.
For 16-bit precision GPU training, there NO need to to install NVIDIA apex. Just use the --fp16_precision flag and this implementation will use Pytorch built in AMP training.
Feature Evaluation
Feature evaluation is done using a linear model protocol.
First, we learned features using SimCLR on the STL10 unsupervised set. Then, we train a linear classifier on top of the frozen features from SimCLR. The linear model is trained on features extracted from the STL10 train set and evaluated on the STL10 test set.
Check the notebook for reproducibility.
Note that SimCLR benefits from longer training.
| Linear Classification | Dataset | Feature Extractor | Architecture | Feature dimensionality | Projection Head dimensionality | Epochs | Top1 % |
|---|---|---|---|---|---|---|---|
| Logistic Regression (Adam) | STL10 | SimCLR | ResNet-18 | 512 | 128 | 100 | 74.45 |
| Logistic Regression (Adam) | CIFAR10 | SimCLR | ResNet-18 | 512 | 128 | 100 | 69.82 |
| Logistic Regression (Adam) | STL10 | SimCLR | ResNet-50 | 2048 | 128 | 50 | 70.075 |


















 170 Dec 28, 2022
170 Dec 28, 2022
 2 Dec 27, 2021
2 Dec 27, 2021
 22 Dec 11, 2022
22 Dec 11, 2022
 5 Oct 20, 2022
5 Oct 20, 2022
 1 Nov 17, 2022
1 Nov 17, 2022
 1 Oct 27, 2022
1 Oct 27, 2022
 145 Jan 06, 2023
145 Jan 06, 2023
 2 Dec 12, 2022
2 Dec 12, 2022
 4.6k Jan 04, 2023
4.6k Jan 04, 2023
 2.5k Jan 04, 2023
2.5k Jan 04, 2023
 64 Dec 31, 2022
64 Dec 31, 2022
 146 Dec 11, 2022
146 Dec 11, 2022
 232 Dec 24, 2022
232 Dec 24, 2022
 34 Aug 15, 2022
34 Aug 15, 2022
 4 Mar 15, 2022
4 Mar 15, 2022
 71 Nov 15, 2022
71 Nov 15, 2022
 520 Dec 30, 2022
520 Dec 30, 2022
 1 Dec 17, 2021
1 Dec 17, 2021
 20 May 28, 2022
20 May 28, 2022
 4.2k Jan 01, 2023
4.2k Jan 01, 2023