
| Package | Description | Status |
|---|---|---|
| PyNHD | Navigate and subset NHDPlus (MR and HR) using web services | |
| Py3DEP | Access topographic data through National Map's 3DEP web service | |
| PyGeoHydro | Access NWIS, NID, WQP, HCDN 2009, NLCD, and SSEBop databases | |
| PyDaymet | Access Daymet for daily climate data both single pixel and gridded | |
| AsyncRetriever | High-level API for asynchronous requests with persistent caching | |
| PyGeoOGC | Send queries to any ArcGIS RESTful-, WMS-, and WFS-based services | |
| PyGeoUtils | Convert responses from PyGeoOGC's supported web services to datasets |
PyGeoHydro: Retrieve Geospatial Hydrology Data



Features
PyGeoHydro (formerly named hydrodata) is a part of HyRiver software stack that is designed to aid in watershed analysis through web services. This package provides access to some public web services that offer geospatial hydrology data. It has three main modules: pygeohydro, plot, and helpers.
The pygeohydro module can pull data from the following web services:
- NWIS for daily mean streamflow observations (returned as a
pandas.DataFrameorxarray.Datasetwith station attributes), - Water Quality Portal for accessing current and historical water quality data from more than 1.5 million sites across the US,
- NID for accessing both versions of the National Inventory of Dams web services,
- HCDN 2009 for identifying sites where human activity affects the natural flow of the watercourse,
- NLCD 2019 for land cover/land use, imperviousness, imperviousness descriptor, and canopy data,
- SSEBop for daily actual evapotranspiration, for both single pixel and gridded data.
Also, it has two other functions:
interactive_map: Interactive map for exploring NWIS stations within a bounding box.cover_statistics: Categorical statistics of land use/land cover data.
The plot module includes two main functions:
signatures: Hydrologic signature graphs.cover_legends: Official NLCD land cover legends for plotting a land cover dataset.descriptor_legends: Color map and legends for plotting an imperviousness descriptor dataset.
The helpers module includes:
nlcd_helper: A roughness coefficients lookup table for each land cover and imperviousness descriptor type which is useful for overland flow routing among other applications.nwis_error: A dataframe for finding information about NWIS requests' errors.
Moreover, requests for additional databases and functionalities can be submitted via issue tracker.
You can find some example notebooks here.
You can also try using PyGeoHydro without installing it on your system by clicking on the binder badge. A Jupyter Lab instance with the HyRiver stack pre-installed will be launched in your web browser, and you can start coding!
Please note that since this project is in early development stages, while the provided functionalities should be stable, changes in APIs are possible in new releases. But we appreciate it if you give this project a try and provide feedback. Contributions are most welcome.
Moreover, requests for additional functionalities can be submitted via issue tracker.
Installation
You can install PyGeoHydro using pip after installing libgdal on your system (for example, in Ubuntu run sudo apt install libgdal-dev). Moreover, PyGeoHydro has an optional dependency for using persistent caching, requests-cache. We highly recommend installing this package as it can significantly speed up send/receive queries. You don't have to change anything in your code, since PyGeoHydro under-the-hood looks for requests-cache and if available, it will automatically use persistent caching:
$ pip install pygeohydro
Alternatively, PyGeoHydro can be installed from the conda-forge repository using Conda:
$ conda install -c conda-forge pygeohydro
Quick start
We can explore the available NWIS stations within a bounding box using interactive_map function. It returns an interactive map and by clicking on a station some of the most important properties of stations are shown.
import pygeohydro as gh
bbox = (-69.5, 45, -69, 45.5)
gh.interactive_map(bbox)
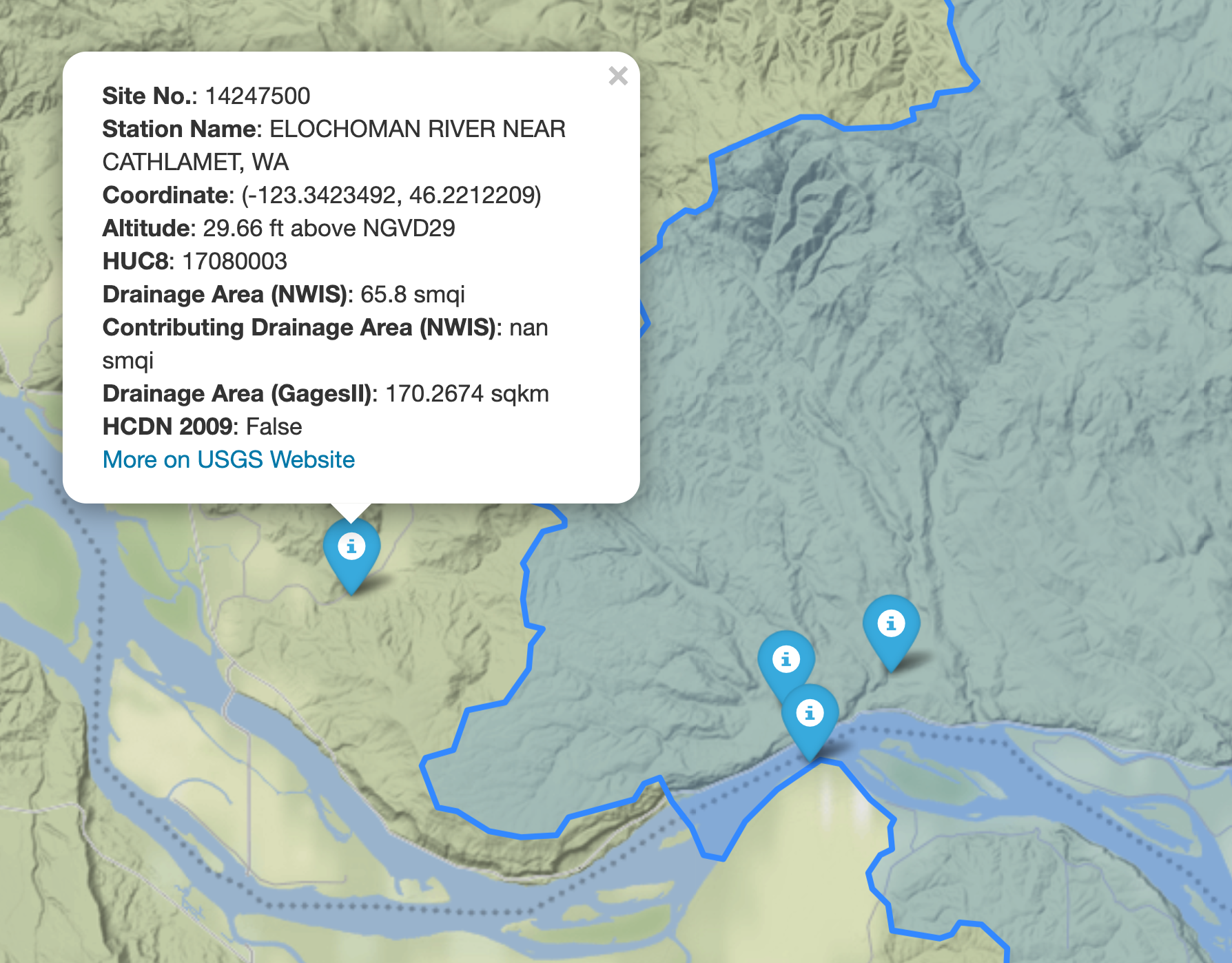
We can select all the stations within this boundary box that have daily mean streamflow data from 2000-01-01 to 2010-12-31:
from pygeohydro import NWIS
nwis = NWIS()
query = {
**nwis.query_bybox(bbox),
"hasDataTypeCd": "dv",
"outputDataTypeCd": "dv",
}
info_box = nwis.get_info(query)
dates = ("2000-01-01", "2010-12-31")
stations = info_box[
(info_box.begin_date <= dates[0]) & (info_box.end_date >= dates[1])
].site_no.tolist()
Then, we can get the daily streamflow data in mm/day (by default the values are in cms) and plot them:
from pygeohydro import plot
qobs = nwis.get_streamflow(stations, dates, mmd=True)
plot.signatures(qobs)
By default, get_streamflow returns a pandas.DataFrame that has a attrs method containing metadata for all the stations. You can access it like so qobs.attrs. Moreover, we can get the same data as xarray.Dataset as follows:
qobs_ds = nwis.get_streamflow(stations, dates, to_xarray=True)
This xarray.Dataset has two dimensions: time and station_id. It has 10 variables including discharge with two dimensions while other variables that are station attitudes are one dimensional.
We can also get instantaneous streamflow data using get_streamflow. This method assumes that the input dates are in UTC time zone and returns the data in UTC time zone as well.
date = ("2005-01-01 12:00", "2005-01-12 15:00")
qobs = nwis.get_streamflow("01646500", date, freq="iv")
The WaterQuality has a number of convenience methods to retrieve data from the web service. Since there are many parameter combinations that can be used to retrieve data, a general method is also provided to retrieve data from any of the valid endpoints. You can use get_json to retrieve stations info as a geopandas.GeoDataFrame or get_csv to retrieve stations data as a pandas.DataFrame. You can construct a dictionary of the parameters and pass it to one of these functions. For more information on the parameters, please consult the Water Quality Data documentation. For example, let's find all the stations within a bounding box that have Caffeine data:
from pynhd import WaterQuality
bbox = (-92.8, 44.2, -88.9, 46.0)
kwds = {"characteristicName": "Caffeine"}
wq = WaterQuality()
stations = wq.station_bybbox(bbox, kwds)
Or the same criterion but within a 30-mile radius of a point:
stations = wq.station_bydistance(-92.8, 44.2, 30, kwds)
Then we can get the data for all these stations the data like this:
sids = stations.MonitoringLocationIdentifier.tolist()
caff = wq.data_bystation(sids, kwds)
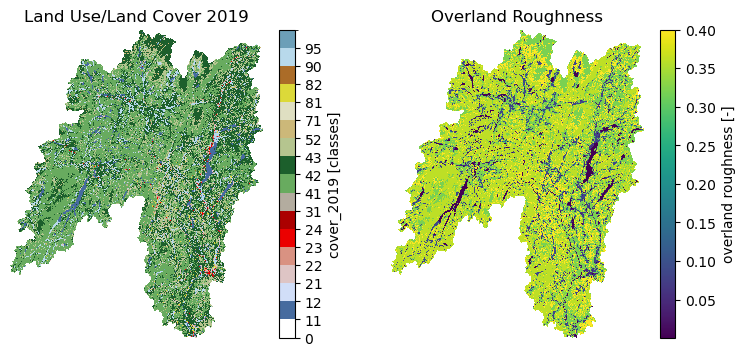
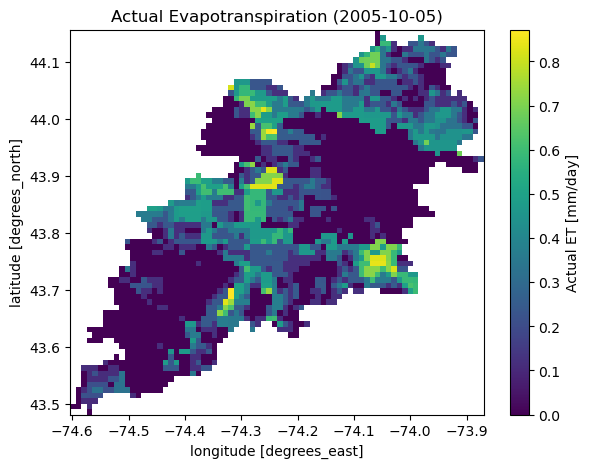
Moreover, we can get land use/land cove data using nlcd function, percentages of land cover types using cover_statistics, and actual ET with ssebopeta_bygeom:
from pynhd import NLDI
geometry = NLDI().get_basins("01031500").geometry[0]
lulc = gh.nlcd(geometry, 100, years={"cover": [2016, 2019]})
stats = gh.cover_statistics(lulc.cover_2016)
eta = gh.ssebopeta_bygeom(geometry, dates=("2005-10-01", "2005-10-05"))
Additionally, we can pull all the US dams data using NID. Let's get dams that are within this bounding box and have a maximum storage larger than 200 acre-feet.
nid = NID()
dams = nid.bygeom(bbox, "epsg:4326", sql_clause="MAX_STORAGE > 200")
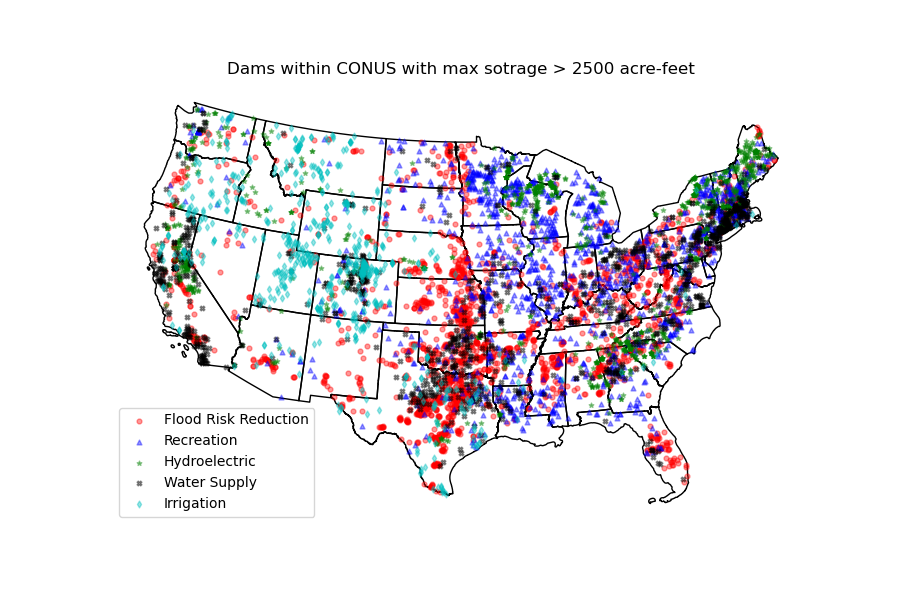
We can get all the dams within CONUS using NID and plot them:
import geopandas as gpd
world = gpd.read_file(gpd.datasets.get_path("naturalearth_lowres"))
conus = world[world.name == "United States of America"].geometry.iloc[0][0]
conus_dams = nid.bygeom(conus, "epsg:4326")
Contributing
Contributions are very welcomed. Please read CONTRIBUTING.rst file for instructions.
Credits
This package was created based on the audreyr/cookiecutter-pypackage project template.








 2 Feb 27, 2022
2 Feb 27, 2022
 7 Dec 02, 2021
7 Dec 02, 2021
 3 Nov 29, 2022
3 Nov 29, 2022
 1 Jan 24, 2022
1 Jan 24, 2022
 1 Dec 19, 2021
1 Dec 19, 2021
 162 Jan 08, 2023
162 Jan 08, 2023
 1 Feb 08, 2022
1 Feb 08, 2022
 17 Oct 22, 2022
17 Oct 22, 2022
 6 Feb 02, 2022
6 Feb 02, 2022
 115 Dec 30, 2022
115 Dec 30, 2022
 8 Aug 17, 2022
8 Aug 17, 2022
 4 Apr 30, 2022
4 Apr 30, 2022
 170 Dec 14, 2022
170 Dec 14, 2022
 17 Dec 23, 2022
17 Dec 23, 2022
 6 Sep 16, 2022
6 Sep 16, 2022
 7 Sep 05, 2021
7 Sep 05, 2021
 150 Jan 04, 2023
150 Jan 04, 2023
 2 Nov 17, 2021
2 Nov 17, 2021
 25 Aug 14, 2022
25 Aug 14, 2022
 14 Oct 25, 2021
14 Oct 25, 2021