Filter By
387 Repositories
Python

Web mining module for Python, with tools for scraping, natural language processing, machine learning, network analysis and visualization.
Pattern Pattern is a web mining module for Python. It has tools for: Data Mining: web services (Google, Twitter, Wikipedia), web crawler, HTML DOM par
 8.4k Jan 08, 2023
8.4k Jan 08, 2023
An helper library to scrape data from TikTok in one line, using the Influencer Hunters APIs.
TikTok Scraper An utility library to scrape data from TikTok hassle-free Go to the website » View Demo · Report Bug · Request Feature About The Projec
 6 Jan 08, 2023
6 Jan 08, 2023
A Python library for automating interaction with websites.
Home page https://mechanicalsoup.readthedocs.io/ Overview A Python library for automating interaction with websites. MechanicalSoup automatically stor
 4.3k Jan 07, 2023
4.3k Jan 07, 2023
Scrapy, a fast high-level web crawling & scraping framework for Python.
Scrapy Overview Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pag
 45.5k Jan 07, 2023
45.5k Jan 07, 2023
News, full-text, and article metadata extraction in Python 3. Advanced docs:
Newspaper3k: Article scraping & curation Inspired by requests for its simplicity and powered by lxml for its speed: "Newspaper is an amazing python li
 12.3k Jan 07, 2023
12.3k Jan 07, 2023

爬取各大SRC当日公告 | 通过微信通知的小工具 | 赏金工具
OnTimeHacker V1.0 OnTimeHacker 是一个爬取各大SRC当日公告,并通过微信通知的小工具 OnTimeHacker目前版本为1.0,已支持24家SRC,列表如下 360、爱奇艺、阿里、百度、哔哩哔哩、贝壳、Boss、58、菜鸟、滴滴、斗鱼、 饿了么、瓜子、合合、享道、京东、
 95 Jan 07, 2023
95 Jan 07, 2023
DaProfiler allows you to get emails, social medias, adresses, works and more on your target using web scraping and google dorking techniques
DaProfiler allows you to get emails, social medias, adresses, works and more on your target using web scraping and google dorking techniques, based in France Only. The particularity of this program i
 347 Jan 07, 2023
347 Jan 07, 2023

Web scraping library and command-line tool for text discovery and extraction (main content, metadata, comments)
trafilatura: Web scraping tool for text discovery and retrieval Description Trafilatura is a Python package and command-line tool which seamlessly dow
 704 Jan 06, 2023
704 Jan 06, 2023
Library to scrape and clean web pages to create massive datasets.
lazynlp A straightforward library that allows you to crawl, clean up, and deduplicate webpages to create massive monolingual datasets. Using this libr
 2.1k Jan 06, 2023
2.1k Jan 06, 2023
A web scraper that exports your entire WhatsApp chat history.
WhatSoup 🍲 A web scraper that exports your entire WhatsApp chat history. Table of Contents Overview Demo Prerequisites Instructions Frequen
 87 Jan 06, 2023
87 Jan 06, 2023
This Scrapy project uses Redis and Kafka to create a distributed on demand scraping cluster
This Scrapy project uses Redis and Kafka to create a distributed on demand scraping cluster.
 1.1k Jan 06, 2023
1.1k Jan 06, 2023
Visual scraping for Scrapy
Portia Portia is a tool that allows you to visually scrape websites without any programming knowledge required. With Portia you can annotate a web pag
 8.7k Jan 05, 2023
8.7k Jan 05, 2023
京东抢茅台,秒杀成功很多次讨论,天猫抢购,赚钱交流等。
Jd_Seckill 特别声明: 请添加个人微信:19972009719 进群交流讨论 目前群里很多人抢到【扫描微信添加群就好,满200关闭群,有喜欢薅信用卡羊毛的也可以找我交流】 本仓库发布的jd_seckill项目中涉及的任何脚本,仅用于测试和学习研究,禁止用于商业用途,不能保证其合法性,准确性
 50 Jan 05, 2023
50 Jan 05, 2023
 457 Jan 05, 2023
457 Jan 05, 2023
淘宝、天猫半价抢购,抢电视、抢茅台,干死黄牛党
taobao_seckill 淘宝、天猫半价抢购,抢电视、抢茅台,干死黄牛党 依赖 安装chrome浏览器,根据浏览器的版本找到对应的chromedriver下载安装 web版使用说明 1、抢购前需要校准本地时间,然后把需要抢购的商品加入购物车 2、如果要打包成可执行文件,可使用pyinstalle
 2k Jan 05, 2023
2k Jan 05, 2023
Web crawling framework based on asyncio.
Web crawling framework for everyone. Written with asyncio, uvloop and aiohttp. Requirements Python3.5+ Installation pip install gain pip install uvloo
 2k Jan 05, 2023
2k Jan 05, 2023
爬虫案例合集。包括但不限于《淘宝、京东、天猫、豆瓣、抖音、快手、微博、微信、阿里、头条、pdd、优酷、爱奇艺、携程、12306、58、搜狐、百度指数、维普万方、Zlibraty、Oalib、小说、招标网、采购网、小红书》
lxSpider 爬虫案例合集。包括但不限于《淘宝、京东、天猫、豆瓣、抖音、快手、微博、微信、阿里、头条、pdd、优酷、爱奇艺、携程、12306、58、搜狐、百度指数、维普万方、Zlibraty、Oalib、小说网站、招标采购网》 简介: 时光荏苒,记不清写了多少案例了。
 793 Jan 05, 2023
793 Jan 05, 2023
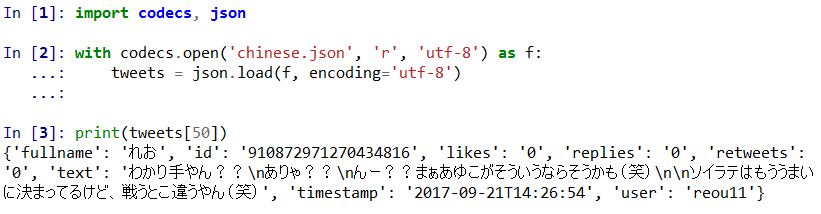
Scrape Twitter for Tweets
Backers Thank you to all our backers! 🙏 [Become a backer] Sponsors Support this project by becoming a sponsor. Your logo will show up here with a lin
 2.2k Jan 05, 2023
2.2k Jan 05, 2023
Ebay Webscraper for Getting Average Product Price
Ebay-Webscraper-for-Getting-Average-Product-Price The code in this repo is used to determine the average price of an item on Ebay given a valid search
 17 Jan 05, 2023
17 Jan 05, 2023
A high-level distributed crawling framework.
Cola: high-level distributed crawling framework Overview Cola is a high-level distributed crawling framework, used to crawl pages and extract structur
 1.5k Jan 04, 2023
1.5k Jan 04, 2023
Web Scraping Framework
Grab Framework Documentation Installation $ pip install -U grab See details about installing Grab on different platforms here http://docs.grablib.
 2.3k Jan 04, 2023
2.3k Jan 04, 2023
A Powerful Spider(Web Crawler) System in Python.
pyspider A Powerful Spider(Web Crawler) System in Python. Write script in Python Powerful WebUI with script editor, task monitor, project manager and
 15.7k Jan 04, 2023
15.7k Jan 04, 2023

A Smart, Automatic, Fast and Lightweight Web Scraper for Python
AutoScraper: A Smart, Automatic, Fast and Lightweight Web Scraper for Python This project is made for automatic web scraping to make scraping easy. It
 4.8k Jan 04, 2023
4.8k Jan 04, 2023
Minimal set of tools to conduct stealthy scraping.
Stealthy Scraping Tools Do not use puppeteer and playwright for scraping. Explanation. We only use the CDP to obtain the page source and to get the ab
 88 Jan 04, 2023
88 Jan 04, 2023
A Python module to bypass Cloudflare's anti-bot page.
cloudflare-scrape A simple Python module to bypass Cloudflare's anti-bot page (also known as "I'm Under Attack Mode", or IUAM), implemented with Reque
 3k Jan 04, 2023
3k Jan 04, 2023
京东秒杀商品抢购Python脚本
Jd_Seckill 非常感谢原作者 https://github.com/zhou-xiaojun/jd_mask 提供的代码 也非常感谢 https://github.com/wlwwu/jd_maotai 进行的优化 主要功能 登陆京东商城(www.jd.com) cookies登录 (需要自
 1.5k Jan 03, 2023
1.5k Jan 03, 2023
fork huanghyw/jd_seckill
Jd_Seckill 特别声明: 本仓库发布的jd_seckill项目中涉及的任何脚本,仅用于测试和学习研究,禁止用于商业用途,不能保证其合法性,准确性,完整性和有效性,请根据情况自行判断。 本项目内所有资源文件,禁止任何公众号、自媒体进行任何形式的转载、发布。
 512 Jan 03, 2023
512 Jan 03, 2023
:arrow_double_down: Dumb downloader that scrapes the web
You-Get NOTICE: Read this if you are looking for the conventional "Issues" tab. You-Get is a tiny command-line utility to download media contents (vid
 46.4k Jan 03, 2023
46.4k Jan 03, 2023