Python-Search-Engine-Scrapy || Python-爬虫-索引/利用爬虫获取谷歌信息**/
Searching info from Google using Python Scrapy /* 利用 PYTHON 爬虫获取天气信息,以及城市信息和资料**/
translation time comparation
+------------+----------+ | Library | Time | +------------+----------+ | polyglot | 3.67 s | +------------+----------+ | fasttext | 6.41 | +------------+----------+ | cld3 | 14 s | +------------+----------+ | langid | 1min 8s | +------------+----------+ | langdetect | 2min 53s | +------------+----------+ | chardet | 4min 36s | +------------+----------+ It would generate warning : 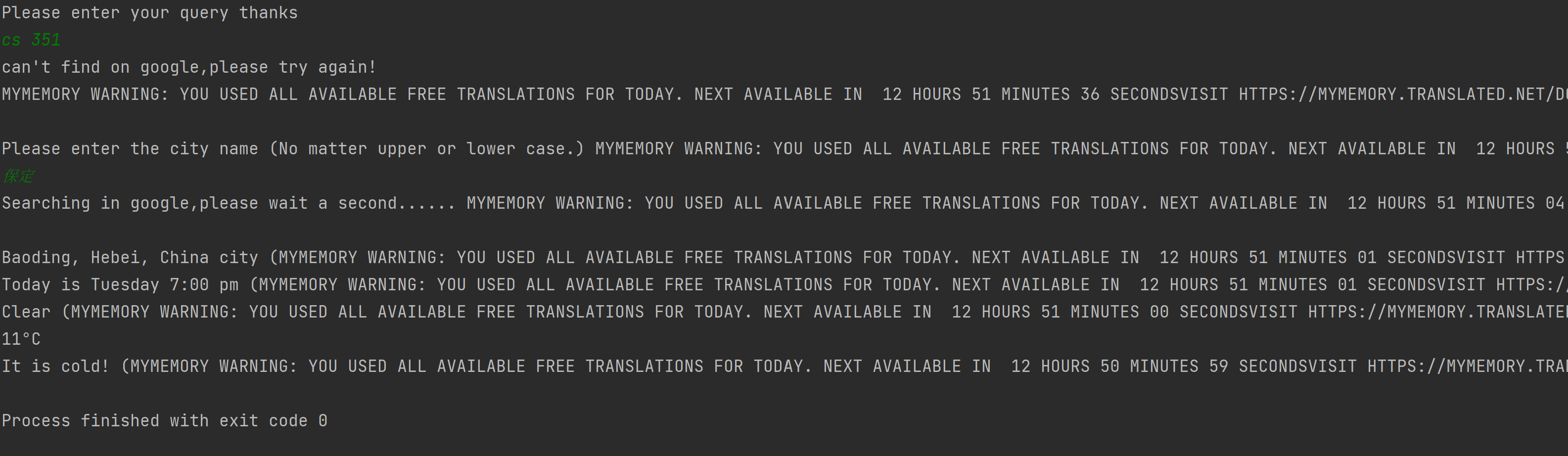



 1 Feb 11, 2022
1 Feb 11, 2022
 36 Oct 27, 2022
36 Oct 27, 2022
 6 Nov 07, 2022
6 Nov 07, 2022
 8 Oct 12, 2022
8 Oct 12, 2022
 1 Nov 17, 2022
1 Nov 17, 2022
 725 Jan 03, 2023
725 Jan 03, 2023
 10 Aug 07, 2022
10 Aug 07, 2022
 45 Dec 30, 2022
45 Dec 30, 2022
 163 Dec 30, 2022
163 Dec 30, 2022
 3 Apr 15, 2022
3 Apr 15, 2022
 793 Jan 05, 2023
793 Jan 05, 2023
 543 Jan 03, 2023
543 Jan 03, 2023
 2.4k Jan 01, 2023
2.4k Jan 01, 2023
 14 Aug 12, 2022
14 Aug 12, 2022
 1 Dec 07, 2021
1 Dec 07, 2021
 2k Dec 28, 2022
2k Dec 28, 2022
 2.2k Jan 05, 2023
2.2k Jan 05, 2023
 1 Jan 08, 2022
1 Jan 08, 2022
 1 Jul 09, 2022
1 Jul 09, 2022
 117 Dec 22, 2022
117 Dec 22, 2022