Flask-CRUD-NLP
A simple Flask site that allows users to create, update, and delete posts in a database, as well as perform basic NLP tasks on the posts. The app allows for PDF uploads, and will perform OCR on the PDFs and add the text to the database. NLP tasks include sentiment analysis (on individual posts or all posts combined as one text), returning word counts and average word lengths for posts, and generating a word cloud from the posts.
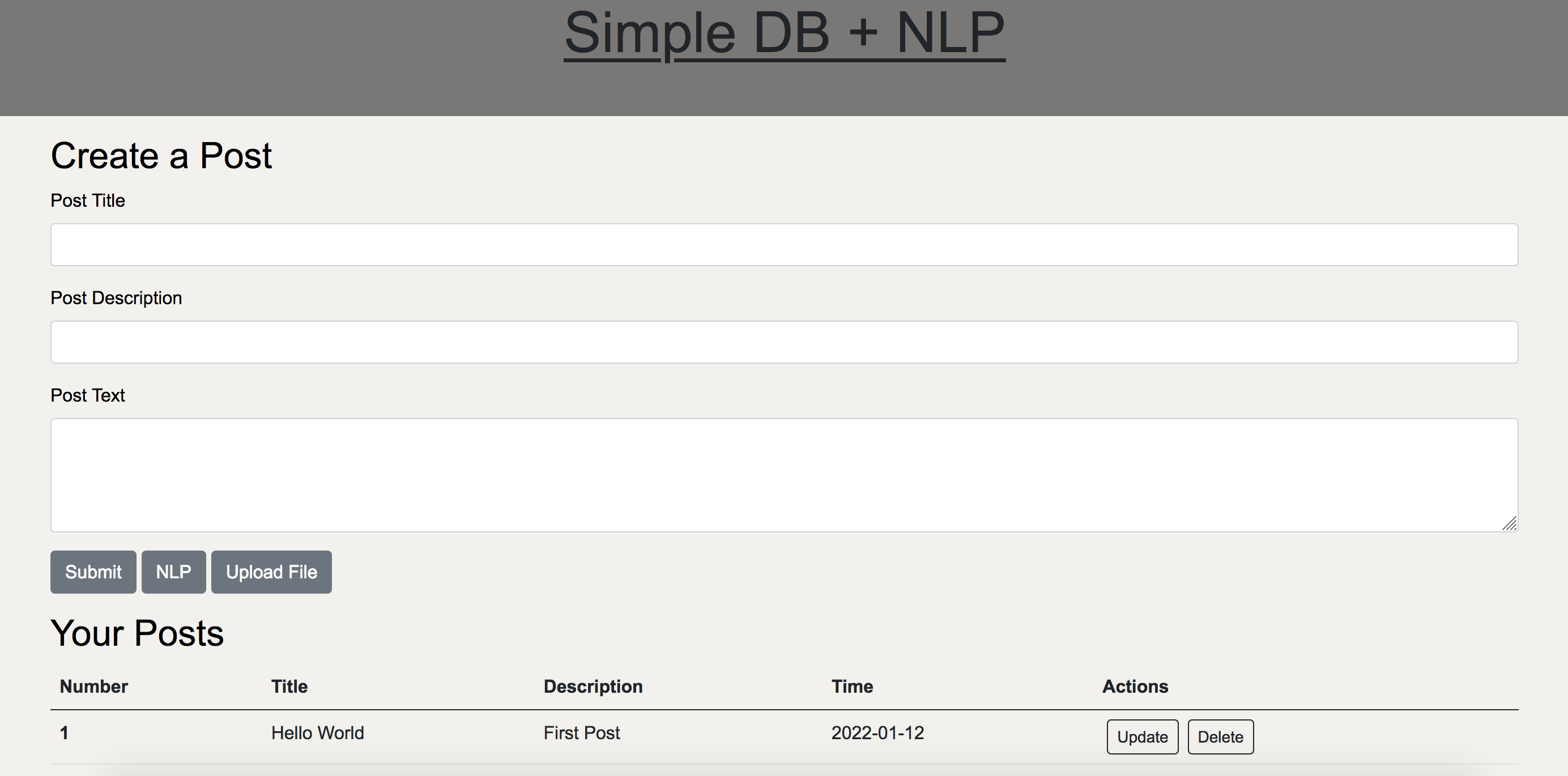
Getting Started
Install dependencies using pip:
pip install -r requirements.txt
Then run Flask:
flask run

 23 Dec 25, 2022
23 Dec 25, 2022
 8 Nov 11, 2022
8 Nov 11, 2022
 160 Dec 23, 2022
160 Dec 23, 2022
 16 Dec 12, 2022
16 Dec 12, 2022
 8 Aug 11, 2022
8 Aug 11, 2022
 1 Jan 04, 2022
1 Jan 04, 2022
 114 Dec 29, 2022
114 Dec 29, 2022
 665 Dec 17, 2022
665 Dec 17, 2022
 28 Sep 13, 2022
28 Sep 13, 2022
 364 Jan 03, 2023
364 Jan 03, 2023
 97 Dec 15, 2022
97 Dec 15, 2022
 6 Oct 22, 2022
6 Oct 22, 2022
 37 Nov 19, 2022
37 Nov 19, 2022
 68 Jan 06, 2023
68 Jan 06, 2023
 4 Apr 06, 2022
4 Apr 06, 2022
 5 Dec 28, 2021
5 Dec 28, 2021
 23 Sep 27, 2022
23 Sep 27, 2022
 0 Oct 07, 2021
0 Oct 07, 2021
 148 Dec 26, 2022
148 Dec 26, 2022