Traceback (most recent call last):
File "C:\Users\Administrator\Desktop\douyincrawler\douyincrawler.py", line 119, in
print(res.result())
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\concurrent\futures_base.py", line 438, in result
return self.__get_result()
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\concurrent\futures_base.py", line 390, in __get_result
raise self._exception
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\concurrent\futures\thread.py", line 52, in run
result = self.fn(*self.args, **self.kwargs)
File "C:\Users\Administrator\Desktop\douyincrawler\douyincrawler.py", line 49, in get_video
with open(title, 'wb') as v:
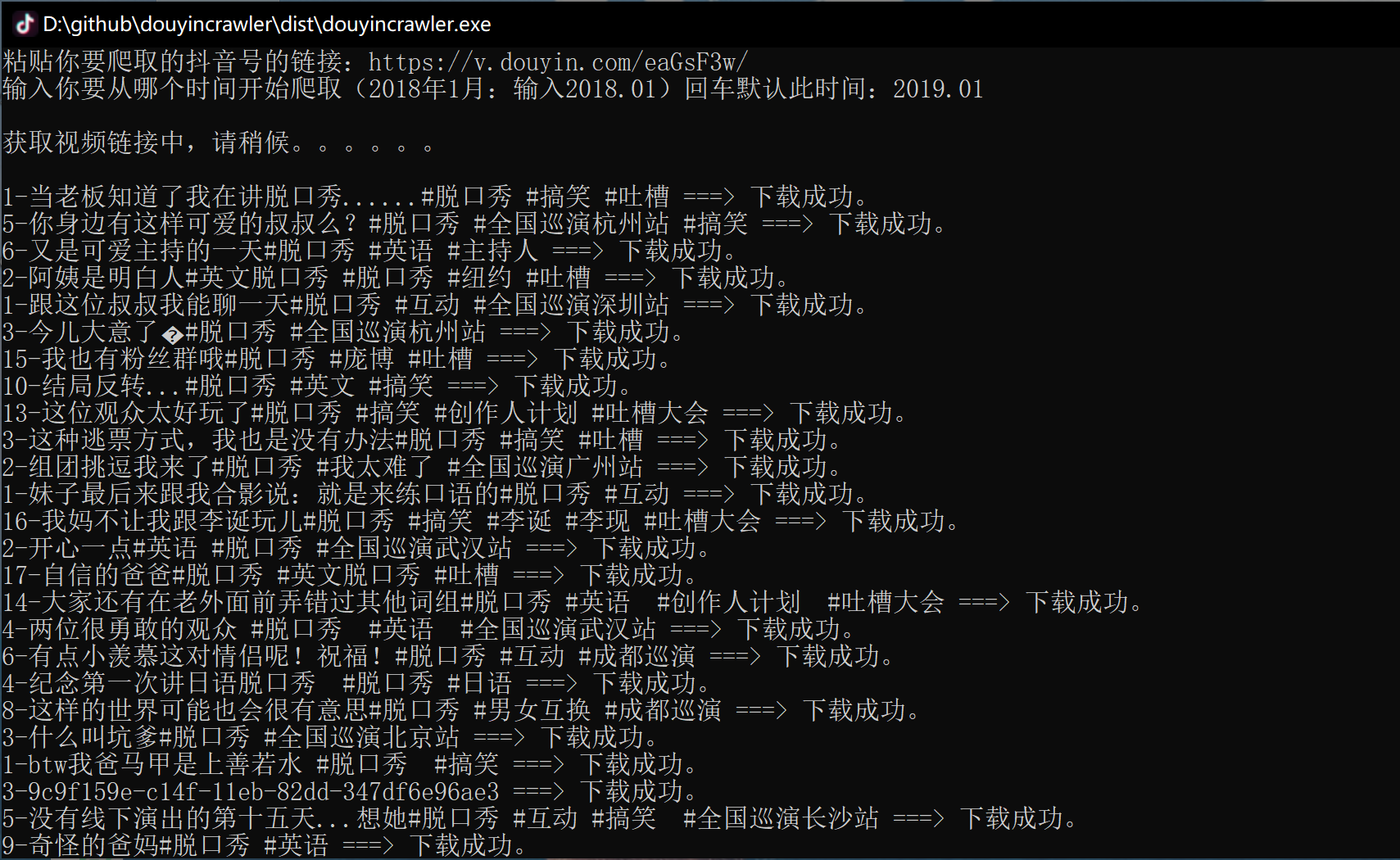
OSError: [Errno 22] Invalid argument: '打了杯咖啡就知道败家/2022.04-7/1-现在是不是已经不流行文青了\U0001f979 \n九叶重
楼二两,冬至蝉蛹一钱,煎入隔年雪,可医世人相思疾苦,可重楼七叶一枝花,冬至何来蝉蛹,雪又怎能隔年,原是 相思无解!\n殊
不知,夏枯即为九重楼,掘地三尺寒蝉现,除夕子时雪,落地已隔年。相思亦可解….mp4'
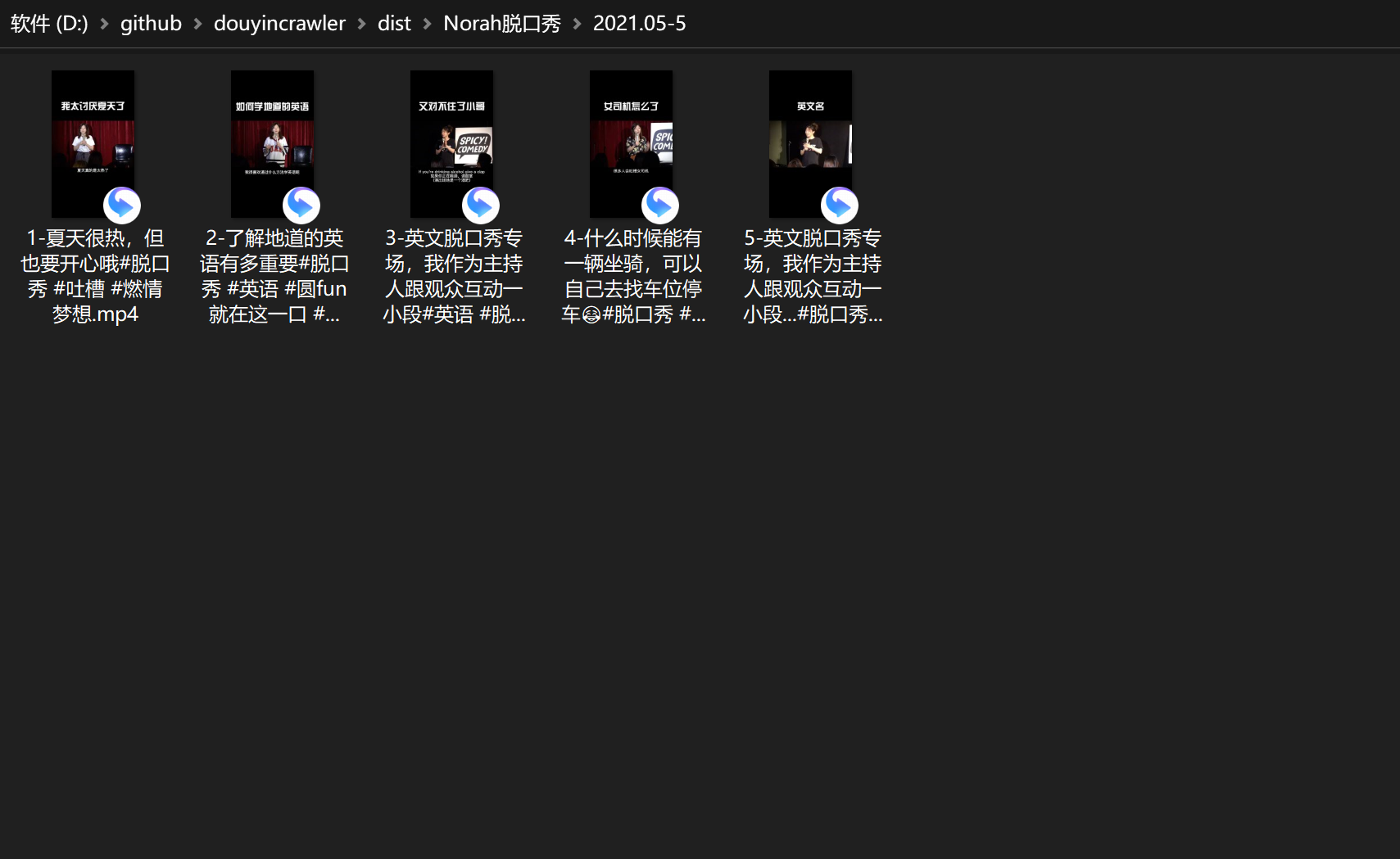



 2 Nov 22, 2021
2 Nov 22, 2021
 2 Oct 31, 2022
2 Oct 31, 2022
 4 Nov 18, 2022
4 Nov 18, 2022
 2 Jan 04, 2022
2 Jan 04, 2022
 2.1k Jan 06, 2023
2.1k Jan 06, 2023
 2 Jan 11, 2022
2 Jan 11, 2022
 5.2k Jan 03, 2023
5.2k Jan 03, 2023
 32 Dec 31, 2022
32 Dec 31, 2022
 35 Aug 29, 2022
35 Aug 29, 2022
 776 Jul 28, 2021
776 Jul 28, 2021
 10 Aug 18, 2022
10 Aug 18, 2022
 3.2k Dec 29, 2022
3.2k Dec 29, 2022
 2 Feb 17, 2022
2 Feb 17, 2022
 9 Nov 16, 2022
9 Nov 16, 2022
 0 Jan 07, 2022
0 Jan 07, 2022
 1 Nov 03, 2021
1 Nov 03, 2021
 2 Dec 22, 2021
2 Dec 22, 2021
 1 Feb 17, 2022
1 Feb 17, 2022
 3 Jan 03, 2022
3 Jan 03, 2022
 3 Feb 13, 2022
3 Feb 13, 2022