YOLOv5 in tesnorflow2.x-keras
- yolov5数据增强jupyter示例
- Bilibili视频讲解地址: 《yolov5 解读,训练,复现》
- Bilibili视频讲解PPT文件: yolov5_bilibili_talk_ppt.pdf
- Bilibili视频讲解PPT文件: yolov5_bilibili_talk_ppt.pdf (gitee链接)
模型测试
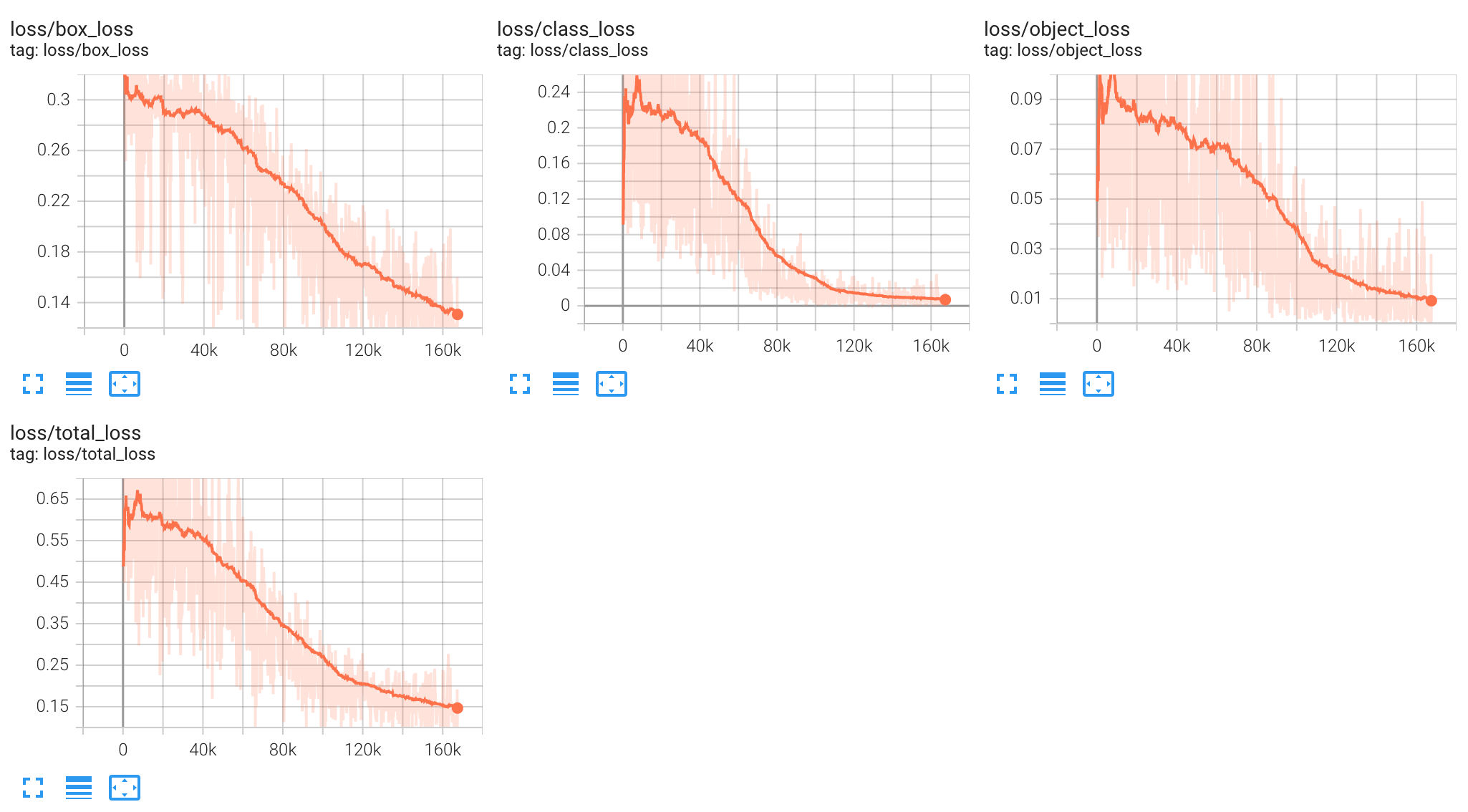
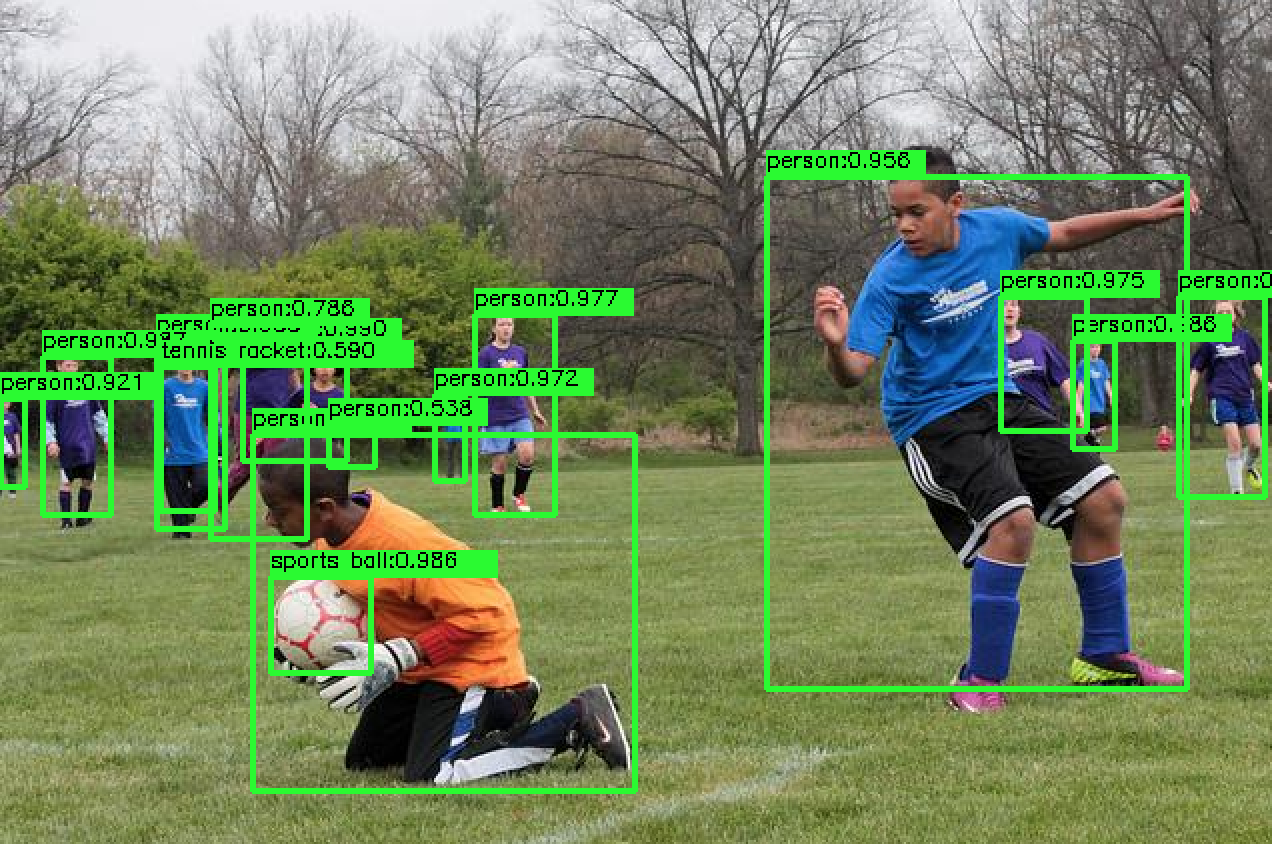
- 训练 COCO2017(val 5k)
- 检测效果



- 精度/召回率
Requirements
pip3 install -r requirements.txt
Get start
- 训练
python3 train.py
- tensorboard
tensorboard --host 0.0.0.0 --logdir ./logs/ --port 8053 --samples_per_plugin=images=40
- 查看
http://127.0.0.1:8053
- 测试, 修改
detect.py里面input_image和model_path
python3 detect.py
训练自己的数据
- labelme打标自己的数据
- 打开
data/labelme2coco.py脚本, 修改如下地方
input_dir = '这里写labelme打标时保存json标记文件的目录'
output_dir = '这里写要转CoCo格式的目录,建议建一个空目录'
labels = "这里是你打标时所有的类别名, txt文本即可, 每行一个类, 类名无需加引号"
- 执行
data/labelme2coco.py脚本会在output_dir生成对应的json文件和图片 - 修改
train.py文件中coco_annotation_file以及num_class, 注意classes通过CoCoDataGenrator(*).coco.cats[label_id]['name']可获得,由于coco中类别不连续,所以通过coco.cats拿到的数组下标拿到的类别可能不准. - 开始训练,
python3 train.py









 144 Jan 08, 2023
144 Jan 08, 2023
 820 Dec 17, 2022
820 Dec 17, 2022
 2 Jun 18, 2022
2 Jun 18, 2022
 133 Jan 02, 2023
133 Jan 02, 2023
 2 Dec 16, 2022
2 Dec 16, 2022
 242 Dec 30, 2022
242 Dec 30, 2022
 41 May 18, 2022
41 May 18, 2022
 75 Dec 13, 2022
75 Dec 13, 2022
 85 Dec 29, 2022
85 Dec 29, 2022
 264 Jan 02, 2023
264 Jan 02, 2023
 20 Jan 05, 2023
20 Jan 05, 2023
 322 Dec 31, 2022
322 Dec 31, 2022
 4 Apr 14, 2022
4 Apr 14, 2022
 17 Dec 06, 2022
17 Dec 06, 2022
 42 Nov 24, 2022
42 Nov 24, 2022
 21 Jan 03, 2023
21 Jan 03, 2023
 27 Dec 16, 2022
27 Dec 16, 2022
 102 Dec 25, 2022
102 Dec 25, 2022
 1 Dec 28, 2021
1 Dec 28, 2021
 42 Nov 26, 2022
42 Nov 26, 2022