Laporan Proyek Machine Learning - Azhar Rizki Zulma
Domain Proyek
Domain proyek yang dipilih dalam proyek machine learning ini adalah mengenai keuangan dan cryptocurrency dengan judul proyek "Bitcoin Price Predictive Analytics".
Latar Belakang
Cryptocurrency saat ini berada di era kejayaannya, Di mana banyak investor mulai tertarik untuk berinvestasi pada mata uang digital tersebut. Belum lagi kemunculan aset NFT atau Non Fungible Token yang semakin menarik minat masyarakat. Sayangnya untuk membeli aset NFT ini, hanya bisa di lakukan dengan transaksi menggunakan mata uang digital, seperti salah satu contohnya ialah Bitcoin. Dengan semakin populernya penggunaan cryptocurrency dan mata uang digital di era industri 4.0 ini. Dibutuhkan keputusan yang matang dan memerlukan analisis lanjutan, agar tidak salah dalam mengambil keputusan dan mengakibatkan kerugian dalam melakukan transaksi aset digital tersebut di masa mendatang. Khususnya pada transaksi Bitcoin yang akan kita bahas dalam laporan ini.
Berdasarkan permasalahan di atas, maka pada proyek ini akan dibangun suatu model machine learning untuk memprediksi harga pasar Bitcoin di masa depan. Dengan adanya model machine learning ini, di harapkan dapat membantu dan memudahkan analisa serta dapat mengambil keputusan yang tepat tentang strategi berinvestasi dalam dunia cryptocurrency. Sehingga dapat meminimalisir kesalahan investasi dan kerugian di masa mendatang. Kemudian untuk tahap pengembangan selanjutnya, di harapkan implementasi dari model ini dapat dijalankan pada sebuah aplikasi berbasis web ataupun android nantinya.
Business Understanding
Problem Statements
Berdasarkan pada latar belakang di atas, permasalahan yang dapat diselesaikan pada proyek ini adalah sebagai berikut:
- Bagaimana cara melakukan pra-pemrosesan data harga Bitcoin sehingga dapat digunakan untuk membuat model yang baik?
- Bagaimana cara membangun model machine learning untuk memprediksi data harga Bitcoin di masa mendatang?
Goals
Tujuan dibuatnya proyek ini adalah sebagai berikut:
- Melakukan pra-pemrosesan data harga Bitcoin agar dapat digunakan dalam membangun model.
- Membangun model machine learning untuk memprediksi data harga di masa mendatang dengan tingkat akurasi > 80%.
Solution statements
Solusi yang dapat dilakukan untuk memenuhi tujuan dari proyek ini di antaranya:
-
Pra-pemrosesan Data. Pada pra-pemrosesan data dapat dilakukan beberapa tahapan, antara lain:
- Melakukan perhitungan rerata berdasarkan data Open, Close, High dan Low.
- Melakukan pembagian dataset.
- Mengatasi data pencilan (outliers) dengan Metode IQR.
- Standardisasi data fitur numerik pada dataset.
-
Pembangunan Model. Pada pembangunan model terdapat beberapa algoritma yang digunakan, antara lain:
- K-Nearest Neighbor
- Random Forest
- Boosting Algorithm
Data Understanding
-
Informasi Dataset
Dataset yang digunakan pada proyek ini yaitu dataset lengkap dengan riwayat harga Bitcoin, informasi lebih lanjut mengenai dataset tersebut dapat lihat pada tabel berikut:Jenis Keterangan Sumber Dataset: Kaggle Dataset Owner sudalairajkumar Lisensi CC0: Public Domain Kategori Cryptorrency, Finance Usability 9.7 Jenis dan Ukuran Berkas CSV (382.27 kB) Setelah melakukan observasi pada dataset yang diunduh melalui link Kaggle yaitu
coin_Bitcoin.csv, didapatkan informasi sebagai berikut :- Terdapat 2991 baris (records atau jumlah pengamatan) yang berisi informasi mengenai data riwayat harga Bitcoin.
- Terdapat 10 kolom yaitu
SNo, Name, Symbol, Date, High, Low, Open, Close, Volume, Marketcapyang merupakan variabel - variabel pada data - Dari kolom-kolom tersebut terdapat 6 kolom numerik dengan tipe data float64, yaitu
High, Low, Open, Close, Volume, Marketcapdan terdapat 1 kolom numerik dengan tipe data int64 yaituSNoyang merupakan fitur numerik. - Terdapat 2 kolom dengan tipe object yaitu
Name, Symbol - Tidak terdapat missing value pada dataset.
Untuk penjelasan mengenai variabel-variabel pada dataset dapat dilihat pada poin-poin berikut ini:
- Date : Tanggal pencatatan data
- Open : harga ketika dibuka yang dihitung perhari
- Close : harga ketika ditutup yang dihitung perhari
- Low : harga terendah perhari
- High : harga tertinggi perhari
- Volume : volume transaksi perhari
- Market Cap : Kapitalisasi Pasar berdasarkan USD
-
Sebaran atau Distribusi Data pada Setiap Fitur
sebelum masuk ke tahap distribusi data, persiapan yang dilakukan yaitu perlu membuat dua variabel baru yaitu variabel OHLC_Average untuk menampung rata-rata harga dan Price_After_Month untuk harga setelah sebulan.
Berikut merupakan visualisasi data yang menunjukkan sebaran/distribusi data pada setiap fitur-fitur numerik (High, Low, Open, Close, OHLC_Average, Price_After_Month) :-
Mengidentifikasi Missing Value dan Outlier
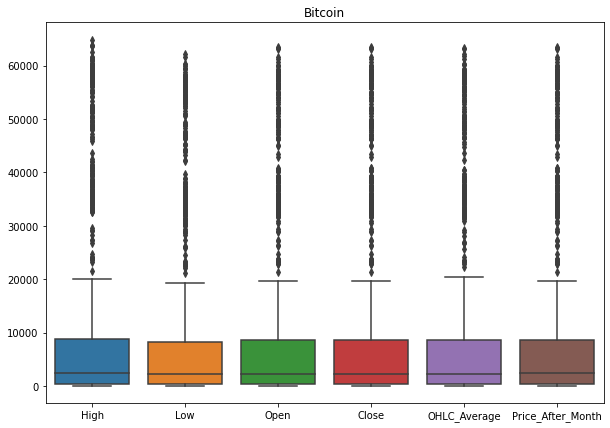
Terlihat jika di atas banyak terdapat outlier pada setiap variabel, lalu untuk mengatasinya nantinya penulis akan menerapkan batas bawah dan batas atas menggunakan metode IQR -
Univariate Analysis
.png)
Terlihat pada grafik bahwa semua data cenderung distribusi nilainya miring ke kanan (right-skewed). Hal ini akan berimplikasi pada model nantinya. -
Multivariate Analysis
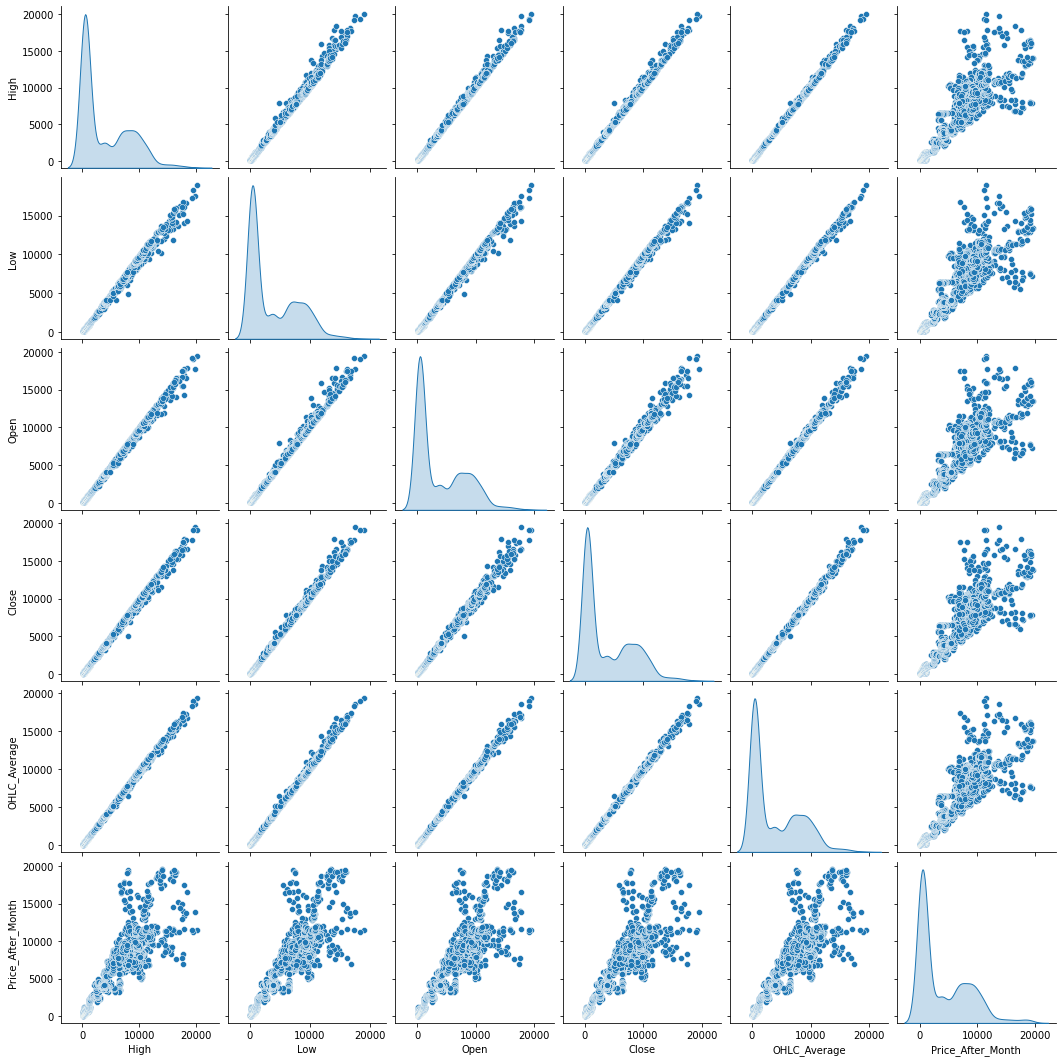
Terlihat bahwa pada grafik kebanyakan bernilai positif karena kebanyakan grafik pada sumbu y dan x mengalami peningkatan yang cukup signifikan membentuk sebuah garis lurus.
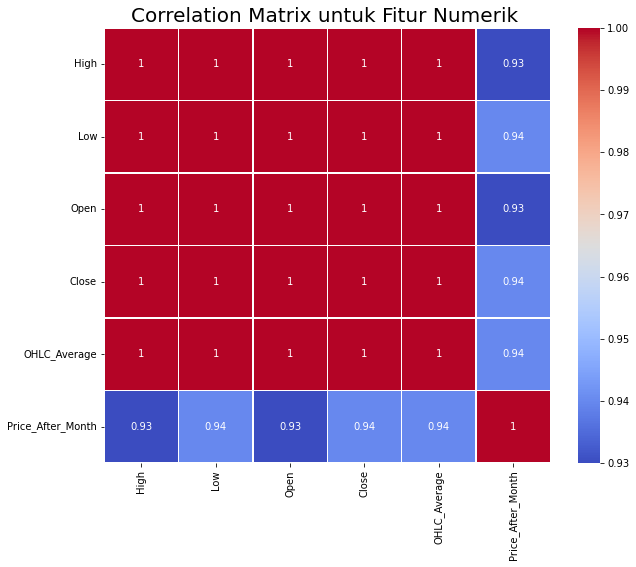
Terlihat pada matriks korelasi di atas dapat disimpulkan bahwa semua variabel memiliki keterikatan dan korelasi yang kuat antar variabel lainnya, dimana nilai korelasi antar variabel bernilai lebih dari 0.9 atau mendekati 1.
-
Data Preparation
Berikut ini merupakan tahapan-tahapan dalam melakukan pra-pemrosesan data:
-
Melakukan Penanganan Missing Value dan Outlier
Penanganan yang penulis lakukan pada Missing Value yaitu dengan melakukan drop data, tetapi karena dataset yang digunakan cukup bersih, missing value hanya terdapat pada variabel yang penulis buat pada model untuk membandingkan harga setelah perbulan (Price_After_Month) sebanyak 30 missing value. Dan untuk mengatasi outlier pada proyek, penulis menggunakan penentuan batas atas dan bawah nilai kuartil pada data dengan menggunakan metode IQR. -
Melakukan pembagian dataset
Untuk mengetahui kinerja model ketika dihadapkan pada data yang belum pernah dilihat sebelumnya, maka perlu dilakukan pembagian dataset. Pada proyek ini dataset dibagi menjadi data latih dan data uji dengan rasio 80% untuk data latih dan 20% untuk data uji. Data latih merupakan data yang akan kita latih untuk membangun model machine learning, sedangkan data uji merupakan data yang belum pernah dilihat oleh model dan digunakan untuk melihat kinerja atau performa dari model yang dilatih. Pembagian dataset dilakukan dengan modul train_test_split dari scikit-learn. Setelah melakukan pembagian dataset, didapatkan jumlah sample pada data latih yaitu 2206 sampel dan jumlah sample pada data uji yaitu 552 sampel dari total jumlah sample pada dataset yaitu 2758 sampel. -
Standardisasi data pada semua fitur numerik pada dataset
Standardisasi merupakan teknik transformasi yang paling umum digunakan dalam tahap data preparation. Standardisasi membantu untuk membuat semua fitur numerik berada dalam skala data yang sama dan membuat fitur data menjadi bentuk yang lebih mudah diolah oleh algoritma. Pada proyek ini, standardisasi data dilakukan dengan menerapkan teknik StandarScaler dari library Scikitlearn. StandardScaler melakukan proses standardisasi fitur dengan mengurangkan mean (nilai rata-rata) kemudian membaginya dengan standard deviasi untuk menggeser distribusi. StandardScaler menghasilkan distribusi dengan standard deviasi sama dengan 1 dan mean sama dengan 0. Sekitar 68% dari nilai akan berada di antara -1 dan 1.
Modeling
Pada proyek ini, Proses modeling dalam proyek ini menggunakan 3 algoritma machine learning yaitu K-Nearest Neighbor, Random Forest dan Boosting Algorithm kemudian membandingkan performanya.
-
K-Nearest Neighbor
KNN bekerja dengan membandingkan jarak satu sampel ke sampel pelatihan lain dengan memilih sejumlah k tetangga terdekat (dengan k adalah sebuah angka positif). Pada tahap ini pembuatan model dilakukan dengan menggunakan modul KNeighborsClassifier dari library Scikitlearn dengan nilai k = 10 dan metric Euclidean yang artinya, pada model ini akan membandingkan jarak satu sampel data ke 10 sampel data tetangganya yang terdekat, agar hasil persamaan regresi yang dihasilkannya nantinya akan lebih halus, tahapan itu akan dilakukan berulang-ulang hingga mendapatkan hasil persamaan regresi dengan nilai yang maksimal. Kemudian proses selanjutnya melakukan prediksi menggunakan data uji dan melakukan pengujian.- Kelebihan:
- Algoritma KNN merupakan algoritma yang sederhana dan mudah untuk diimplementasikan.
- Dapat di implementasikan pada beberapa kasus seperti klasifikasi, regresi dan pencarian.
- Kekurangan:
- Algoritma KNN menjadi lebih lambat secara signifikan seiring meningkatnya jumlah sampel dan/atau variabel independen.
- Kelebihan:
-
Random Forest
Algoritma ini disusun dari banyak algoritma pohon (decision tree) yang pembagian data dan fiturnya dipilih secara acak. Pembuatan model dilakukan dengan menggunakan modul RandomForestClassifier dari library Scikitlearn. terdapat parameter yang harus digunakan agar hasil dari pembuatan model dapat maksimal. Parameter pertama ialah parametern_estimatoryang merupakan jumlah trees (pohon) di forest. Di proyek ini penulis melakukan set nilain_estimatorsebesar 50 trees. Selanjutnya ialah parametermax_depthyang merupakan kedalaman atau panjang pohon. Itu merupakan ukuran seberapa banyak pohon dapat membelah (splitting) untuk membagi setiap node ke dalam jumlah pengamatan yang di inginkan, di proyek ini penulis melakukan set nilaimax_depthsebesar 16 split. Parameterrandom_statedigunakan untuk mengontrol random number generator yang digunakan. Di proyek ini penulis melakukan set nilai pada parameterrandom_statesebesar 55. Lalu yang terakhir ialah parametern_jobsyaitu jumlah job (pekerjaan) yang digunakan secara paralel. Itu merupakan komponen untuk mengontrol thread atau proses yang berjalan secara paralel.n_jobs = -1artinya semua proses berjalan secara paralel. Kemudian proses selanjutnya melakukan prediksi menggunakan data uji dan melakukan pengujian.- Kelebihan :
- Algoritma Random Forest merupakan algoritma dengan pembelajaran paling akurat yang tersedia. Untuk banyak kumpulan data, algoritma ini menghasilkan pengklasifikasi yang sangat akurat.
- Berjalan secara efisien pada data besar.
- Dapat menangani ribuan variabel input tanpa penghapusan variabel.
- Memberikan perkiraan variabel apa yang penting dalam klasifikasi.
- Memiliki metode yang efektif untuk memperkirakan data yang hilang dan menjaga akurasi ketika sebagian besar data hilang.
- Kekurangan :
- Algoritma Random Forest overfiting untuk beberapa kumpulan data dengan tugas klasifikasi/regresi yang bising/noise.
- Untuk data yang menyertakan variabel kategorik dengan jumlah level yang berbeda, Random Forest menjadi bias dalam mendukung atribut dengan level yang lebih banyak. Oleh karena itu, skor kepentingan variabel dari Random Forest tidak dapat diandalkan untuk jenis data ini.
- Kelebihan :
-
Boosting Algorithm
Algoritma ini bekerja dengan membangun model dari data latih. Kemudian ia membuat model kedua yang bertugas memperbaiki kesalahan dari model pertama. Model ditambahkan sampai data latih terprediksi dengan baik atau telah mencapai jumlah maksimum model untuk ditambahkan. Pada tahap ini pembuatan model dilakukan dengan menggunakan modul Boosting Alghoritm dari library Scikitlearn. Penulis meenggunakan metode adaptive boosting yaitu AdaBoost. Parameter yang penulis gunakan terdapat 2 parameter, yaitu parameterlearning_rateyang merupakan bobot yang diterapkan pada setiap regressor di masing-masing proses iterasi boosting, dan parameterrandom_stateyang digunakan untuk mengontrol random number generator yang digunakan. Kemudian proses selanjutnya melakukan prediksi menggunakan data uji dan melakukan pengujian.- Kelebihan :
- Algoritma Boosting dapat mengurangi bias pada data.
- Prosedur Boosting cukup sederhana.
- Algoritma ini sangat powerful dalam meningkatkan akurasi prediksi.
- Algoritma boosting sering mengungguli model yang lebih sederhana seperti logistic regression dan random forest.
- Kekurangan :
- AdaBoost sangat dipengaruhi oleh outlier.
Dapat disimpulkan model terbaik yang digunakan untuk dataset ini ialah model KNN di mana KNN memiliki nilai error terkecil dan nilai akurasi yang tinggi ketimbang kedua model lainnya(cek pada bagian Evaluasi)
- Kelebihan :
Evaluation
Pada proyek ini, metrik evaluasi yang digunakan untuk mengukur kinerja model yaitu menggunakan metrik akurasi dan MSE. Akurasi di sini merupakan tingkat keakuratan data prediksi yang didasarkan dari data latih pada model, tingkat akurasi tertinggi ialah pada model KNN sebesar 89.16% dan ini menunjukkan bahwasannya KNN merupakan model terbaik dari kedua model lainnya dalam memprediksi nilai Bitcoin di masa mendatang. MSE sendiri merupakan Mean Squared Error yang menghitung jumlah selisih kuadrat rata-rata nilai sebenarnya dengan nilai prediksi. MSE didefinisikan dalam persamaan berikut:
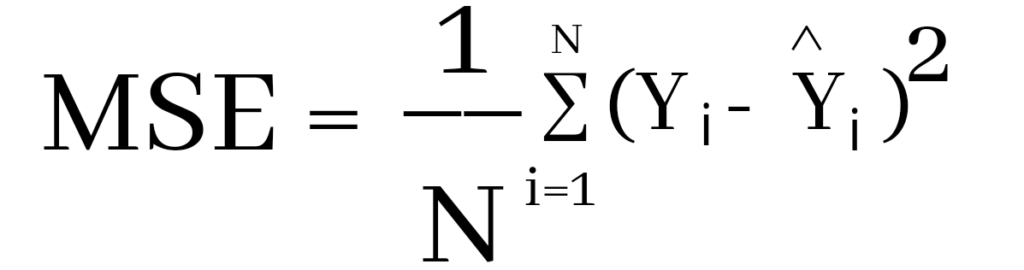
Keterangan:
- N = jumlah dataset
- yi = nilai sebenarnya
- yi^ = nilai prediksi
Sebelum menggunakan metrik MSE, harus dilakukan scaling fitur numerik terlebih dahulu pada data uji untuk menghindari kebocoran data. Setelah melakukan evaluasi berdasarkan metrik MSE dan tingkat akurasi prediksi pada model, penulis mencoba memprediksi harga untuk 30 hari ke depan dengan model KNN dan hasilnya cukup memuaskan karena nilainya tidak jauh berbeda dengan data sebelumnya.
Berikut ini perbandingan grafik metrik MSE pada ketiga model:
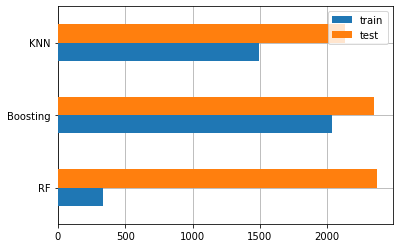
Selain akurasi untuk menentukan model terbaik dapat dilihat juga berdasarkan tingkat eror pada grafik di atas, semakin kecil tingkat eror maka semakin baik model tersebut memprediksi data. jika dilihat dari gambar di atas KNN lah model yang memiliki tingkat eror terendah dibandingkan dengan model lainnya.

 5 Oct 28, 2022
5 Oct 28, 2022
 834 Dec 30, 2022
834 Dec 30, 2022
 5 Apr 11, 2022
5 Apr 11, 2022
 1 May 13, 2022
1 May 13, 2022
 10 Jul 13, 2022
10 Jul 13, 2022
 2 Nov 21, 2021
2 Nov 21, 2021
 1 Dec 14, 2021
1 Dec 14, 2021
 1 Dec 16, 2021
1 Dec 16, 2021
 13 Dec 13, 2022
13 Dec 13, 2022
 282 Dec 11, 2022
282 Dec 11, 2022
 19 Dec 20, 2022
19 Dec 20, 2022
 5 Nov 15, 2021
5 Nov 15, 2021
 97 Dec 29, 2022
97 Dec 29, 2022
 5 Mar 09, 2022
5 Mar 09, 2022
 11 Nov 28, 2022
11 Nov 28, 2022
 2 Dec 21, 2021
2 Dec 21, 2021
 1 Jan 15, 2022
1 Jan 15, 2022
 3 Nov 10, 2021
3 Nov 10, 2021
 2 Jan 22, 2022
2 Jan 22, 2022
 2 Jan 01, 2022
2 Jan 01, 2022