[Japanese/English]
GrabCut-Annotation-Tool
GrabCut-Annotation-Tool.mp4
OpenCVのGrabCut()を利用したアノテーションツールです。
セマンティックセグメンテーション向けのデータセット作成にご使用いただけます。
※GrabCutのアルゴリズムの都合上、境界がはっきりしているデータのアノテーションに向いています。
Requirement
- opencv-python 4.5.2.54 or later
- Pillow 7.2.0 or later
- PySimpleGUI 4.32.1 or later
Directory
│ app.py
│ config.json
│
├─core
│ │ gui.py
│ └─util.py
│
├─input
│
└─output
├─image
└─annotation
app.py, core/gui.py, core/util.py
ソースコードです。
input
アノテーション対象の画像ファイルを格納するディレクトリです。
output
アノテーション結果を保存するディレクトリです。
- image:リサイズした画像が格納されます
- annotation:アノテーション結果が格納されます
※パレットモードのPNG形式で保存
Usage
次のコマンドで起動してください。
python app.py
起動時には以下オプションが指定可能です。
- --input
入力画像格納パス
デフォルト:input - --output_image
アノテーション結果(画像)の格納パス
デフォルト:output/image - --output_annotation
アノテーション結果(セグメンテーション画像)の格納パス
デフォルト:output/annotation - --config
ロードするコンフィグファイル
デフォルト:config.json
Using GrabCut-Annotation-Tool
ファイル選択
ファイル一覧をクリックすることでアノテーション対象を切り替えることが出来ます。
ショートカットキー ↑、p:上のファイルへ ↓、n:下のファイルへ

初期ROI指定
「Select ROI」と表示されている時にマウス右ドラッグで初期ROIを指定できます。

ドラッグ終了後、GrabCut処理が行われます。
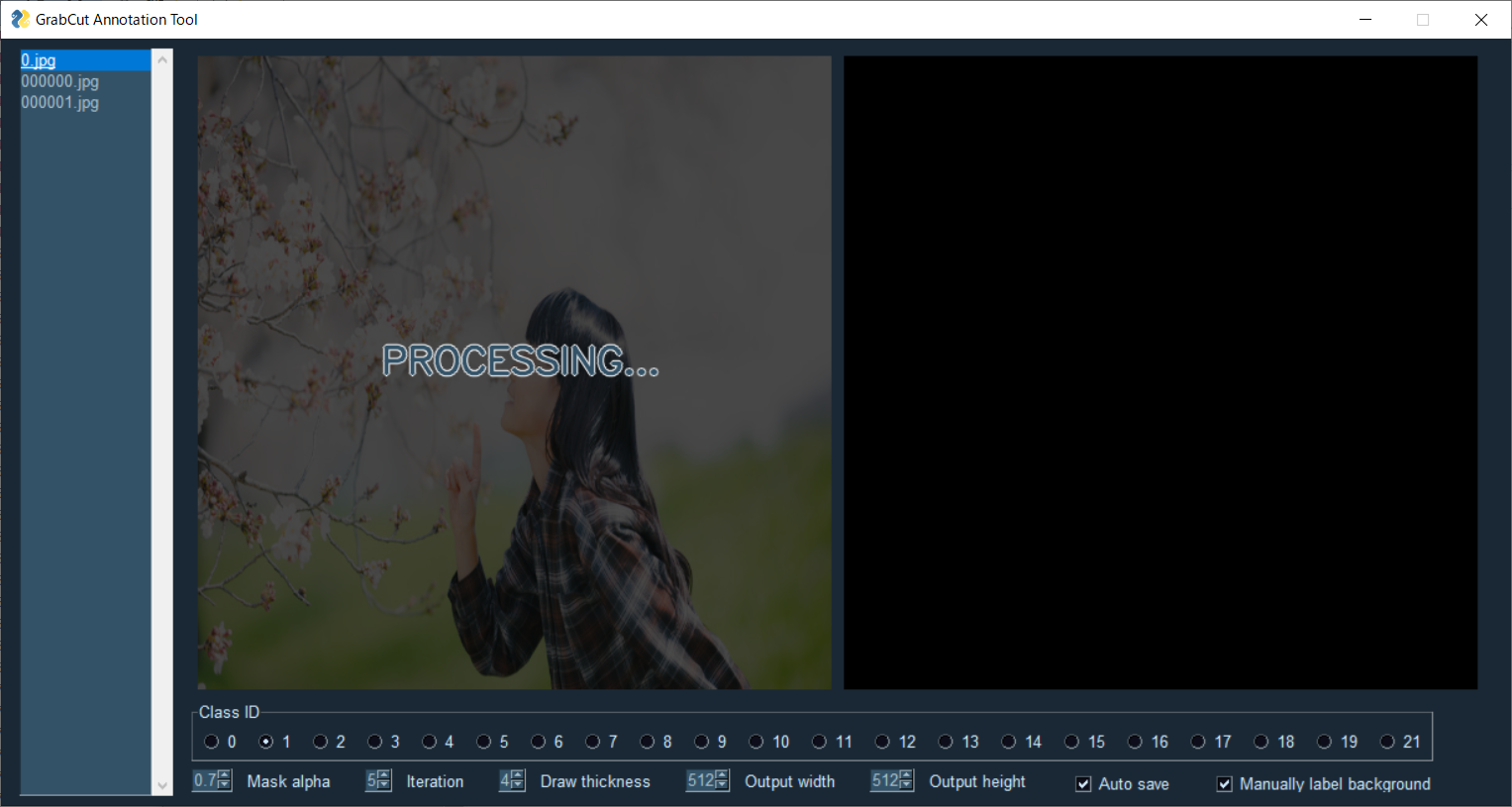
領域が選択されます。

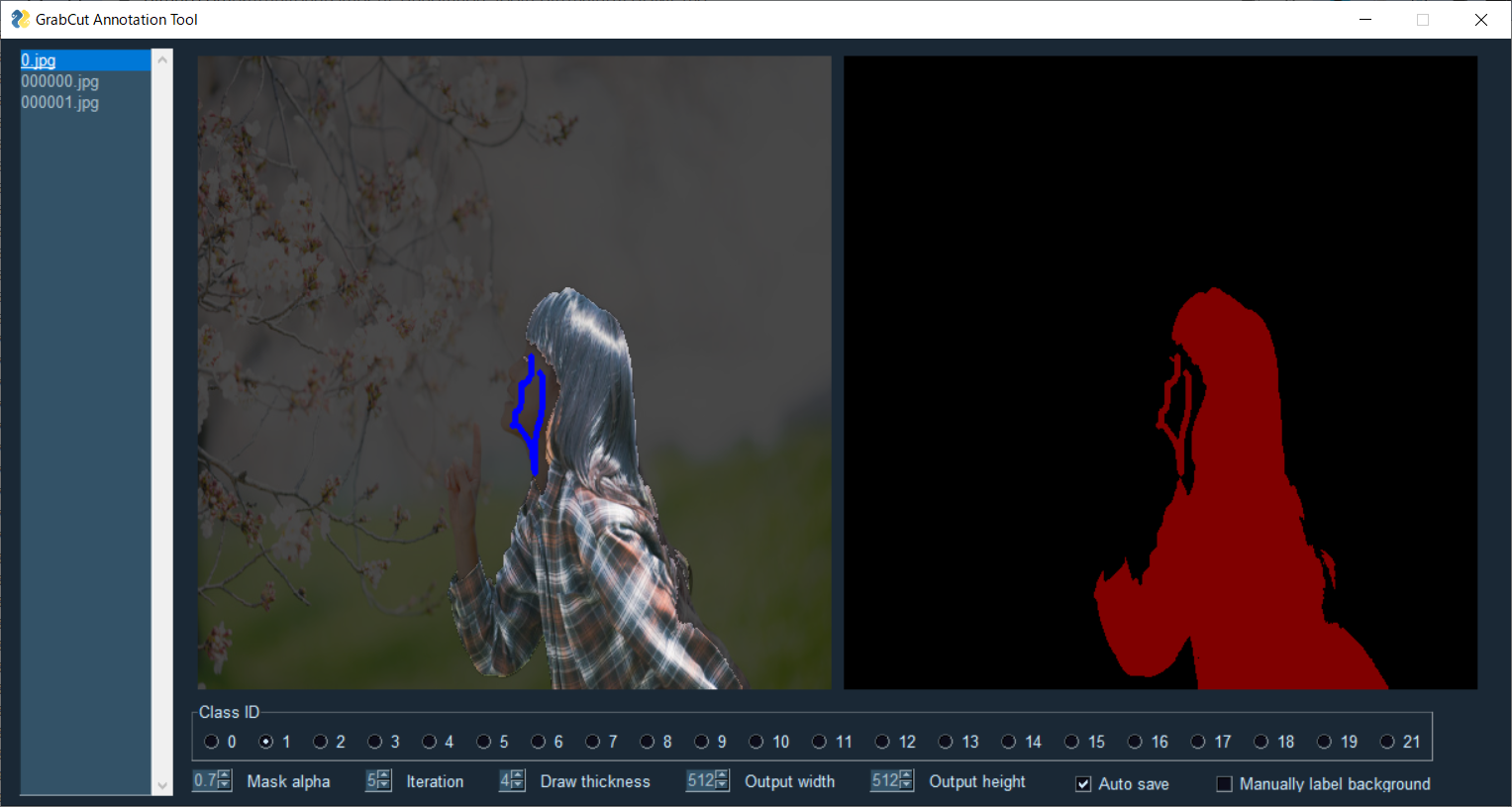
後景指定
マウス右ドラッグで後景の指定が出来ます。


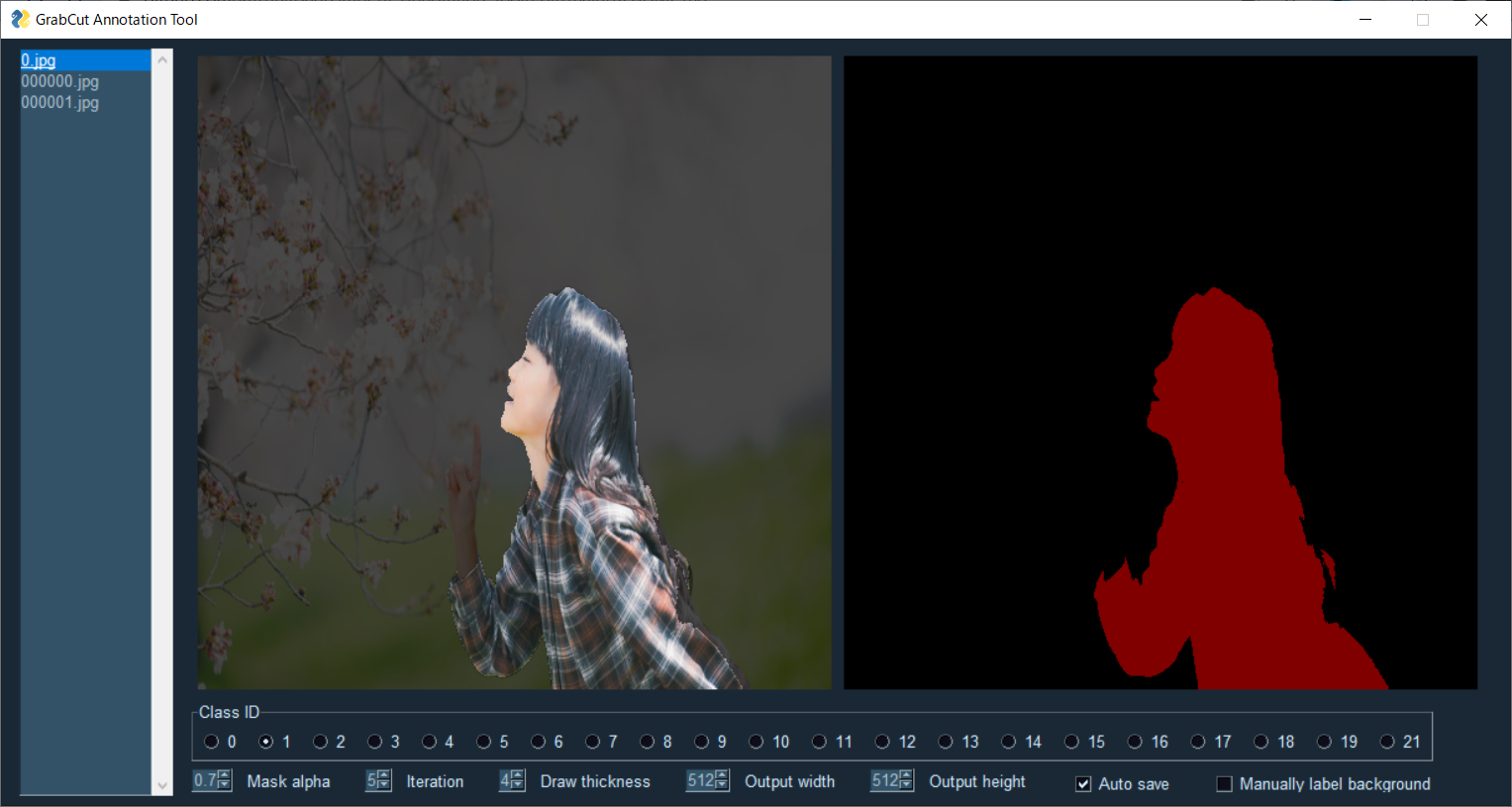
前景指定
「Manually label background」のチェックを外すことで前景指定に切り替えることが出来ます
ショートカットキー Ctrl

マウス右ドラッグで前景の指定が出来ます。
クラスID切り替え
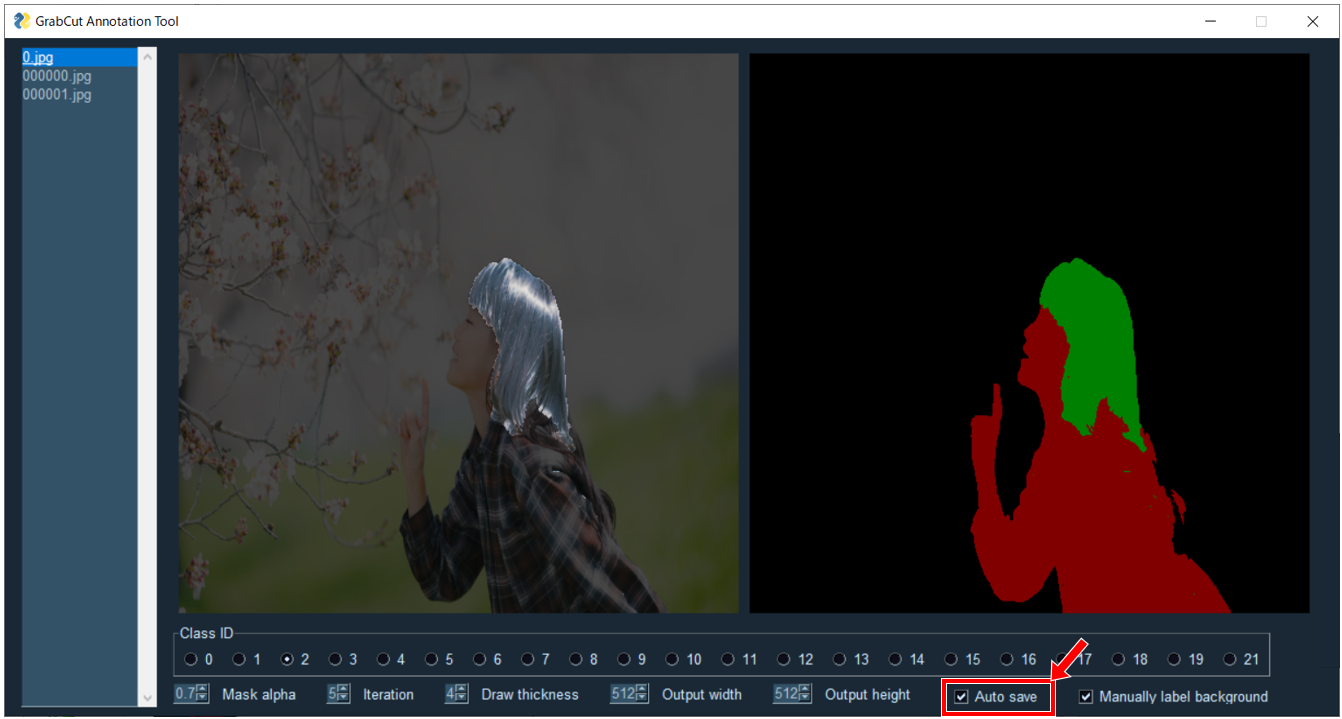
Class IDのチェックボックスを押すことでクラスIDを切り替えることが出来ます。
一桁のIDはショートカットキーでの切り替えも可能です。
ショートカットキー 0-9

クラスID切り替え後はROI指定を行う必要があります。


自動保存
リサイズ画像とアノテーション画像はGrabCut処理毎に自動保存されます。

自動保存をしたくない場合は「Auto save」のチェックを外してください。
自動保存以外で保存したい場合は、キーボード「s」を押してください。
その他設定

- Mask alpha:画像のマスク重畳表示の濃淡具合
- Iteration:GrabCutアルゴリズムのイテレーション回数
- Draw thickness:前景/後景指定時の線の太さ
- Output width:出力画像の横幅
- Output height:出力画像の縦幅
ToDo
-
メモリリーク対策 -
ROI選択時に左上→右下ドラッグ以外も可能にする -
クラスIDをショートカットキーで選択した際にROI選択表示にする
Author
高橋かずひと(https://twitter.com/KzhtTkhs)
License
GrabCut-Annotation-Tool is under Apache-2.0 License.
サンプル画像はフリー素材ぱくたそ様の写真を利用しています。

 146 Dec 16, 2022
146 Dec 16, 2022
 97 Dec 17, 2022
97 Dec 17, 2022

 2 Jul 6, 2022
2 Jul 6, 2022

 337 Dec 15, 2022
337 Dec 15, 2022
 39 Dec 12, 2022
39 Dec 12, 2022

 247 Jan 5, 2023
247 Jan 5, 2023
 7.1k Jan 1, 2023
7.1k Jan 1, 2023

 77 Jan 5, 2023
77 Jan 5, 2023

 15 Dec 12, 2022
15 Dec 12, 2022



 18 Dec 30, 2022
18 Dec 30, 2022
 2 Dec 01, 2022
2 Dec 01, 2022
 131 Jan 06, 2023
131 Jan 06, 2023
 9 Aug 13, 2022
9 Aug 13, 2022
 3 Oct 26, 2022
3 Oct 26, 2022
 2 Dec 14, 2021
2 Dec 14, 2021
 2.1k Dec 27, 2022
2.1k Dec 27, 2022
 10 Oct 16, 2022
10 Oct 16, 2022
 49 Dec 18, 2022
49 Dec 18, 2022
 2k Jan 03, 2023
2k Jan 03, 2023
 396 Dec 30, 2022
396 Dec 30, 2022
 1 Jun 03, 2022
1 Jun 03, 2022
 2.5k Dec 29, 2022
2.5k Dec 29, 2022
 292 Dec 25, 2022
292 Dec 25, 2022
 2.8k Dec 30, 2022
2.8k Dec 30, 2022
 1.9k Dec 19, 2022
1.9k Dec 19, 2022
 38 Aug 17, 2022
38 Aug 17, 2022
 190 Jan 08, 2023
190 Jan 08, 2023
 1 Nov 15, 2021
1 Nov 15, 2021
 57 Nov 28, 2022
57 Nov 28, 2022