Lightweight Hyperparameter Optimization
🚀

![]()
The mle-hyperopt package provides a simple and intuitive API for hyperparameter optimization of your Machine Learning Experiment (MLE) pipeline. It supports real, integer & categorical search variables and single- or multi-objective optimization.
Core features include the following:
- API Simplicity:
strategy.ask(),strategy.tell()interface & space definition. - Strategy Diversity: Grid, random, coordinate search, SMBO & wrapping around FAIR's
nevergrad. - Search Space Refinement based on the top performing configs via
strategy.refine(top_k=10). - Export of configurations to execute via e.g.
python train.py --config_fname config.yaml. - Storage & reload search logs via
strategy.save(,) strategy.load(.)
For a quickstart check out the notebook blog
The API
🎮
from mle_hyperopt import RandomSearch
# Instantiate random search class
strategy = RandomSearch(real={"lrate": {"begin": 0.1,
"end": 0.5,
"prior": "log-uniform"}},
integer={"batch_size": {"begin": 32,
"end": 128,
"prior": "uniform"}},
categorical={"arch": ["mlp", "cnn"]})
# Simple ask - eval - tell API
configs = strategy.ask(5)
values = [train_network(**c) for c in configs]
strategy.tell(configs, values)
Implemented Search Types
🔭
| Search Type | Description | search_config |
|
|---|---|---|---|
 |
GridSearch |
Search over list of discrete values | - |
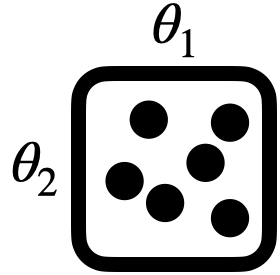 |
RandomSearch |
Random search over variable ranges | refine_after, refine_top_k |
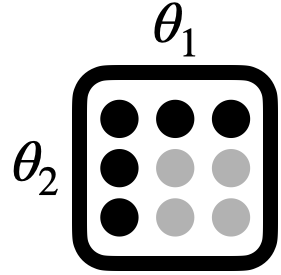 |
CoordinateSearch |
Coordinate-wise optimization with fixed defaults | order, defaults |
 |
SMBOSearch |
Sequential model-based optimization | base_estimator, acq_function, n_initial_points |
 |
NevergradSearch |
Multi-objective nevergrad wrapper | optimizer, budget_size, num_workers |
Variable Types & Hyperparameter Spaces
🌍
| Variable | Type | Space Specification | |
|---|---|---|---|
 |
real |
Real-valued | Dict: begin, end, prior/bins (grid) |
 |
integer |
Integer-valued | Dict: begin, end, prior/bins (grid) |
 |
categorical |
Categorical | List: Values to search over |
Installation
⏳
A PyPI installation is available via:
pip install mle-hyperopt
Alternatively, you can clone this repository and afterwards 'manually' install it:
git clone https://github.com/RobertTLange/mle-hyperopt.git
cd mle-hyperopt
pip install -e .
Further Options
🚴
Saving & Reloading Logs
🏪
# Storing & reloading of results from .pkl
strategy.save("search_log.json")
strategy = RandomSearch(..., reload_path="search_log.json")
# Or manually add info after class instantiation
strategy = RandomSearch(...)
strategy.load("search_log.json")
Search Decorator
🧶
from mle_hyperopt import hyperopt
@hyperopt(strategy_type="grid",
num_search_iters=25,
real={"x": {"begin": 0., "end": 0.5, "bins": 5},
"y": {"begin": 0, "end": 0.5, "bins": 5}})
def circle(config):
distance = abs((config["x"] ** 2 + config["y"] ** 2))
return distance
strategy = circle()
Storing Configuration Files
📑
# Store 2 proposed configurations - eval_0.yaml, eval_1.yaml
strategy.ask(2, store=True)
# Store with explicit configuration filenames - conf_0.yaml, conf_1.yaml
strategy.ask(2, store=True, config_fnames=["conf_0.yaml", "conf_1.yaml"])
Retrieving Top Performers & Visualizing Results
📉
# Get the top k best performing configurations
id, configs, values = strategy.get_best(top_k=4)
# Plot timeseries of best performing score over search iterations
strategy.plot_best()
# Print out ranking of best performers
strategy.print_ranking(top_k=3)
Refining the Search Space of Your Strategy
🪓
# Refine the search space after 5 & 10 iterations based on top 2 configurations
strategy = RandomSearch(real={"lrate": {"begin": 0.1,
"end": 0.5,
"prior": "log-uniform"}},
integer={"batch_size": {"begin": 1,
"end": 5,
"prior": "uniform"}},
categorical={"arch": ["mlp", "cnn"]},
search_config={"refine_after": [5, 10],
"refine_top_k": 2})
# Or do so manually using `refine` method
strategy.tell(...)
strategy.refine(top_k=2)
Note that the search space refinement is only implemented for random, SMBO and nevergrad-based search strategies.
Development & Milestones for Next Release
You can run the test suite via python -m pytest -vv tests/. If you find a bug or are missing your favourite feature, feel free to contact me @RobertTLange or create an issue
![[FEATURE] Hyperband](https://avatars.githubusercontent.com/u/40218556?v=4)
![[FEATURE] Option to pickle the whole strategy](https://avatars.githubusercontent.com/u/16543381?v=4)


 56 Dec 14, 2022
56 Dec 14, 2022
 1 Feb 04, 2022
1 Feb 04, 2022
 858 Dec 25, 2022
858 Dec 25, 2022
 1k Dec 24, 2022
1k Dec 24, 2022
 1 Nov 24, 2021
1 Nov 24, 2021
 8 Sep 19, 2022
8 Sep 19, 2022
 3 Nov 24, 2021
3 Nov 24, 2021
 7 Dec 18, 2021
7 Dec 18, 2021
 924 Jan 03, 2023
924 Jan 03, 2023
 19 Dec 13, 2022
19 Dec 13, 2022
 95 Dec 28, 2022
95 Dec 28, 2022
 38 Jul 29, 2022
38 Jul 29, 2022
 1 Nov 17, 2021
1 Nov 17, 2021
 2k Dec 28, 2022
2k Dec 28, 2022
 1 Nov 27, 2021
1 Nov 27, 2021
 604 Dec 29, 2022
604 Dec 29, 2022
 6 Dec 04, 2022
6 Dec 04, 2022
 325 Dec 23, 2022
325 Dec 23, 2022
 3 Dec 06, 2022
3 Dec 06, 2022
 2 Jul 19, 2022
2 Jul 19, 2022