Convert an image of numbers to a .csv file
This Python program aims to convert images of array numbers to corresponding .csv files. It uses OpenCV for Python to process the given image and Tesseract for number recognition.
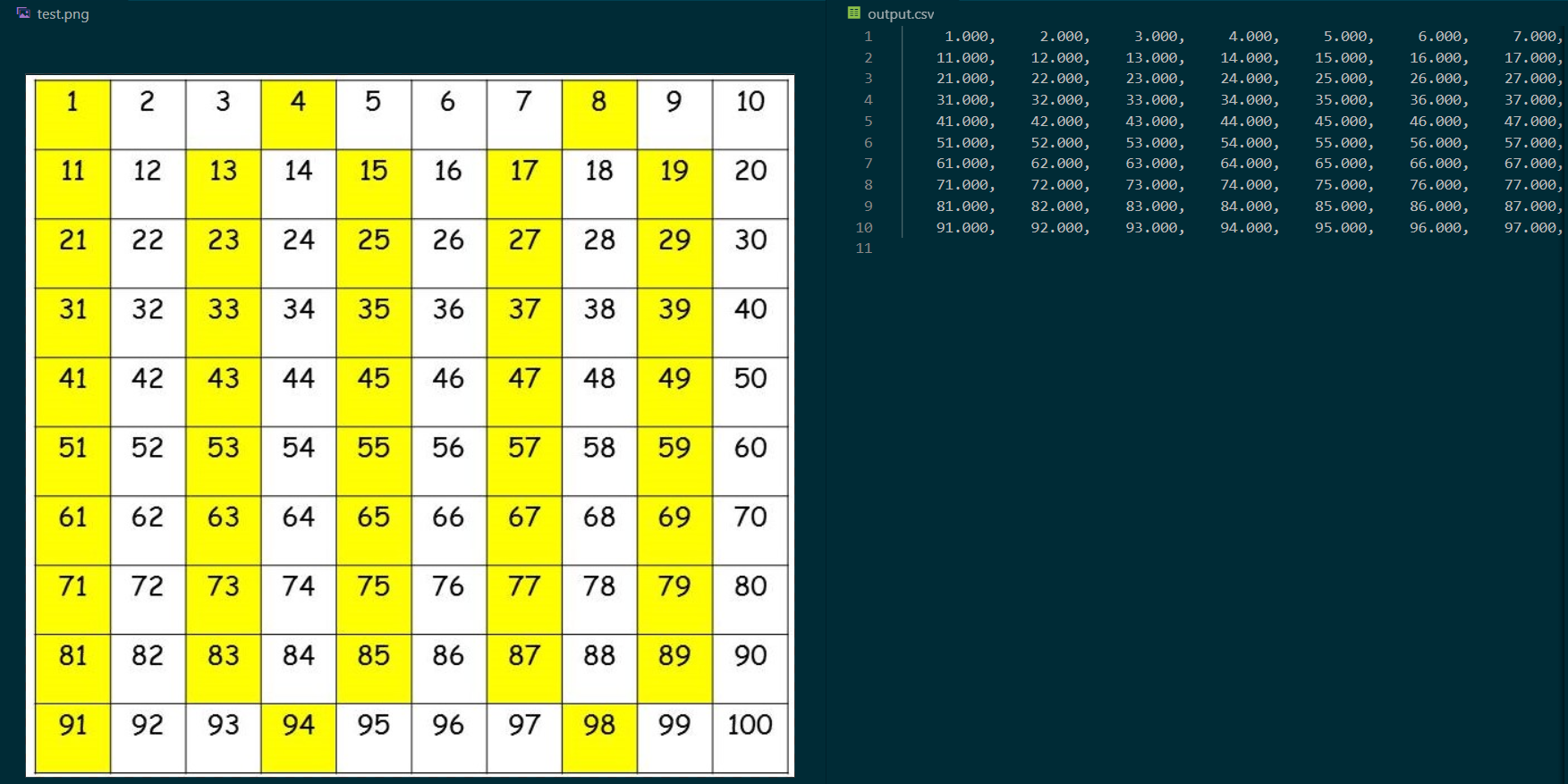
The repository includes:
- the source code of image2csv.py,
- the tools.py file where useful functions are implemented,
- the grid_detector.py file to perform automatic grid detection,
- a folder with some files used for test.
The code is not well documented nor fully efficient as I'm a beginner in programming, and this project is a way for me to improve my skills, in particular in Python programming.
How to use the program
First of all, the user must install the needed packages:
$ pip install -r requirements.txt
as well as Tesseract.
Then, in a python terminal, use the command line:
$ python image2csv.py --image path/to/image
There are a few optionnal arguments:
--path path/to/output/csv/file--grid [False]/True--visualization [y]/n--method [fast]/denoize
and one can find their usage using the command line:
$ python image2csv.py --help
By default, the program will try to detect a grid automatically. This detection uses OpenCV's Hough transformation and Canny detection, so the user can tweak a few parameters for better processing in the grid_detector.py file.
When then program is running with manual grid detection, the user has to interact with it via its mouse and the terminal :
- the image is opened in a window for the user to draw a rectangle around the first (top left) number. As this rectangle is used as a base to create a grid afterward, keep in mind that all the numbers should fit into the box.
- A new window is opened showing the image with the drawn rectangle. Press any key to close and continue.
- Based on the drawn rectangle, a grid is created to extract each number one by one. This grid is controlled by the user via two "offset" values. The user has to enter those values in the terminal, then the image is opened in a window with the created grid. Press any key to close and continue. If the numbers does not fit into the grid, the user can change the offset values and repeat this step. When the grid matches the user's expectations, he can set both of the offset values to 0 to continue.
- The numbers are extracted from the image and the results are shown in the terminal. (be carefoul though, the indicated number of errors represents the number of errors encountered by Tesseract, but Tesseract can identify a wrong number which will not be counted as an error !)
- The .csv file is created with the numbers identified by Tesseract. If Tesseract finds an error, it will show up on the .csv file as an infinite value.
Hypothesis and limits
For the program to run correctly, the input image must verify some hypothesis (just a few simple ones):
- for manual selection, the line and row width must be constants, as the build grid is just a repetition of the initial rectangle with offsets;
- to use automatic grid detection, a full and clear grid, with external borders, must be visible;
- it is recommended to have a good input image resolution, to control the offsets more easily.
At last, this program is not perfect (I know you thought so, with its smooth workflow and simple hypothesis, sorry to disappoint...) and does not work with decimal numbers... But does a great job on negatives ! Also the user must be careful with the slashed zero which seems to be identified by Tesseract as a six.
Credits
For image pre-processing in the tool.py file I used a useful function implemented by @Nitish9711 for his Automatic-Number-plate-detection (https://github.com/Nitish9711/Automatic-Number-plate-detection.git).

 1 Jan 07, 2022
1 Jan 07, 2022
 1 Nov 13, 2021
1 Nov 13, 2021
 527 Dec 04, 2022
527 Dec 04, 2022
 22 Jan 08, 2023
22 Jan 08, 2023
 447 Dec 25, 2022
447 Dec 25, 2022
 6 Nov 30, 2022
6 Nov 30, 2022
 2 Jan 04, 2022
2 Jan 04, 2022
 11 Dec 13, 2022
11 Dec 13, 2022
 3 Jun 30, 2022
3 Jun 30, 2022
 264 Dec 30, 2022
264 Dec 30, 2022
 906 Jan 01, 2023
906 Jan 01, 2023
 527 Jan 02, 2023
527 Jan 02, 2023
 14 Aug 19, 2022
14 Aug 19, 2022
 1 Nov 01, 2021
1 Nov 01, 2021
 1 Jan 01, 2022
1 Jan 01, 2022
 11 Oct 07, 2022
11 Oct 07, 2022
 1 Jun 28, 2022
1 Jun 28, 2022
 14 Jan 03, 2023
14 Jan 03, 2023
 5 Dec 22, 2021
5 Dec 22, 2021
 367 Dec 25, 2022
367 Dec 25, 2022