Dual-Level Collaborative Transformer for Image Captioning
This repository contains the reference code for the paper Dual-Level Collaborative Transformer for Image Captioning.
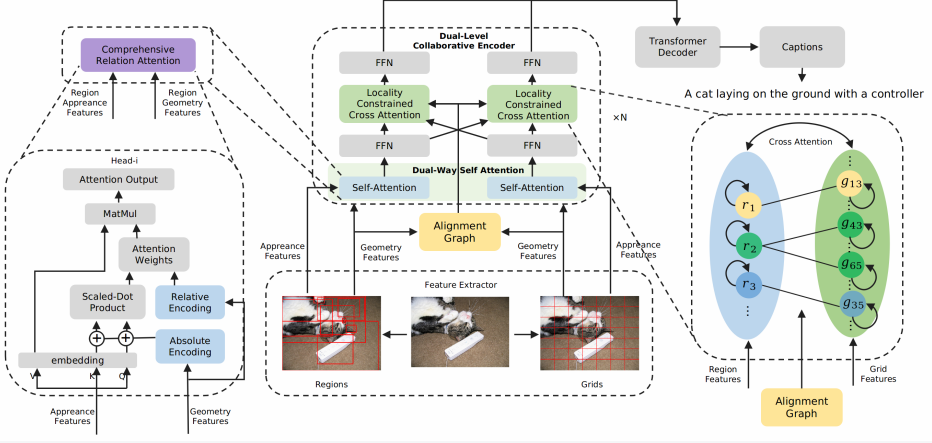
Experiment setup
please refer to m2 transformer
Data preparation
- Annotation. Download the annotation file annotation.zip. Extarct and put it in the project root directory.
- Feature. You can download our ResNeXt-101 feature (hdf5 file) here. Acess code: jcj6.
- evaluation. Download the evaluation tools here. Acess code: jcj6. Extarct and put it in the project root directory.
There are five kinds of keys in our .hdf5 file. They are
['%d_features' % image_id]: region features (N_regions, feature_dim)['%d_boxes' % image_id]: bounding box of region features (N_regions, 4)['%d_size' % image_id]: size of original image (for normalizing bounding box), (2,)['%d_grids' % image_id]: grid features (N_grids, feature_dim)['%d_mask' % image_id]: geometric alignment graph, (N_regions, N_grids)
We extract feature with the code in grid-feats-vqa.
The first three keys can be obtained when extracting region features with extract_region_feature.py. The forth key can be obtained when extracting grid features with code in grid-feats-vqa. The last key can be obtained with align.ipynb
Training
python train.py --exp_name dlct --batch_size 50 --head 8 --features_path ./data/coco_all_align.hdf5 --annotation annotation --workers 8 --rl_batch_size 100 --image_field ImageAllFieldWithMask --model DLCT --rl_at 17 --seed 118
Evaluation
python eval.py --annotation annotation --workers 4 --features_path ./data/coco_all_align.hdf5 --model_path path_of_model_to_eval --model DLCT --image_field ImageAllFieldWithMask --grid_embed --box_embed --dump_json gen_res.json --beam_size 5
Important args:
--features_pathpath to hdf5 file--model_path--dump_jsondump generated captions to
Pretrained model is available here. Acess code: jcj6. By evaluating the pretrained model, you will get
{'BLEU': [0.8136727001615207, 0.6606095421082421, 0.5167535314080227, 0.39790755018790197], 'METEOR': 0.29522868252436046, 'ROUGE': 0.5914367650104326, 'CIDEr': 1.3382047139781112, 'SPICE': 0.22953477359195887}
References
[1] M2
[2] grid-feats-vqa
[3] butd
Acknowledgements
Thanks the original m2 and amazing work of grid-feats-vqa.

 1 Jun 30, 2022
1 Jun 30, 2022
 9 Aug 30, 2022
9 Aug 30, 2022
 1 Jan 12, 2022
1 Jan 12, 2022
 2 Jun 27, 2022
2 Jun 27, 2022
 19 Jan 16, 2022
19 Jan 16, 2022
 333 Dec 29, 2022
333 Dec 29, 2022
 16 Aug 07, 2022
16 Aug 07, 2022
 65 Dec 28, 2022
65 Dec 28, 2022
 9 May 25, 2022
9 May 25, 2022
 17 Dec 14, 2021
17 Dec 14, 2021
 3 Jan 28, 2022
3 Jan 28, 2022
 22 Jul 11, 2022
22 Jul 11, 2022
 36 Nov 21, 2022
36 Nov 21, 2022
 145 Dec 01, 2022
145 Dec 01, 2022
 47 Nov 26, 2022
47 Nov 26, 2022
 49 Nov 06, 2022
49 Nov 06, 2022
 3 Mar 06, 2022
3 Mar 06, 2022
 139 Dec 21, 2022
139 Dec 21, 2022
 55 Dec 12, 2022
55 Dec 12, 2022
 59 Dec 09, 2022
59 Dec 09, 2022