![]()
RITA DSL


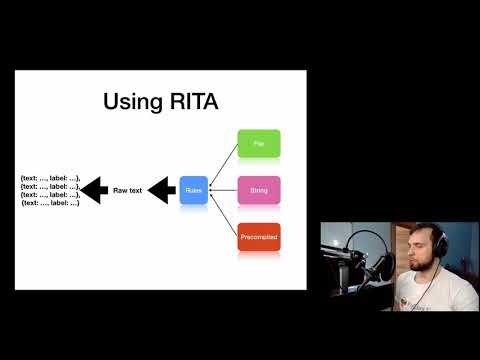
This is a language, loosely based on language Apache UIMA RUTA, focused on writing manual language rules, which compiles into either spaCy compatible patterns, or pure regex. These patterns can be used for doing manual NER as well as used in other processes, like retokenizing and pure matching
An Introduction Video
Links
- Website
- Live Demo
- Simple Chat bot example
- Documentation
- QuickStart
- Language Syntax Plugin for IntelijJ based IDEs
Support


Install
pip install rita-dsl
Simple Rules example
rules = """
cuts = {"fitted", "wide-cut"}
lengths = {"short", "long", "calf-length", "knee-length"}
fabric_types = {"soft", "airy", "crinkled"}
fabrics = {"velour", "chiffon", "knit", "woven", "stretch"}
{IN_LIST(cuts)?, IN_LIST(lengths), WORD("dress")}->MARK("DRESS_TYPE")
{IN_LIST(lengths), IN_LIST(cuts), WORD("dress")}->MARK("DRESS_TYPE")
{IN_LIST(fabric_types)?, IN_LIST(fabrics)}->MARK("DRESS_FABRIC")
"""
Loading in spaCy
import spacy
from rita.shortcuts import setup_spacy
nlp = spacy.load("en")
setup_spacy(nlp, rules_string=rules)
And using it:
>>> r = nlp("She was wearing a short wide-cut dress")
>>> [{"label": e.label_, "text": e.text} for e in r.ents]
[{'label': 'DRESS_TYPE', 'text': 'short wide-cut dress'}]
Loading using Regex (standalone)
import rita
patterns = rita.compile_string(rules, use_engine="standalone")
And using it:
>>> list(patterns.execute("She was wearing a short wide-cut dress"))
[{'end': 38, 'label': 'DRESS_TYPE', 'start': 18, 'text': 'short wide-cut dress'}]




 273 Dec 17, 2022
273 Dec 17, 2022
 53 Sep 26, 2022
53 Sep 26, 2022
 483 Jan 04, 2023
483 Jan 04, 2023
 27 Nov 28, 2022
27 Nov 28, 2022
 65 Dec 30, 2022
65 Dec 30, 2022
 2 Aug 29, 2022
2 Aug 29, 2022
 6 Dec 17, 2022
6 Dec 17, 2022
 27 Dec 12, 2022
27 Dec 12, 2022
 37 Jan 04, 2023
37 Jan 04, 2023
 647 Dec 25, 2022
647 Dec 25, 2022
 48 Nov 22, 2022
48 Nov 22, 2022
 148 Dec 26, 2022
148 Dec 26, 2022
 11 Mar 28, 2022
11 Mar 28, 2022
 11 Sep 25, 2022
11 Sep 25, 2022
 7 Dec 05, 2022
7 Dec 05, 2022
 74 Dec 05, 2022
74 Dec 05, 2022
 5.3k Jan 07, 2023
5.3k Jan 07, 2023
 819 Dec 30, 2022
819 Dec 30, 2022
 48 Dec 14, 2022
48 Dec 14, 2022
 4 Nov 20, 2022
4 Nov 20, 2022