MOT-Tracking-by-Detection-Pipeline
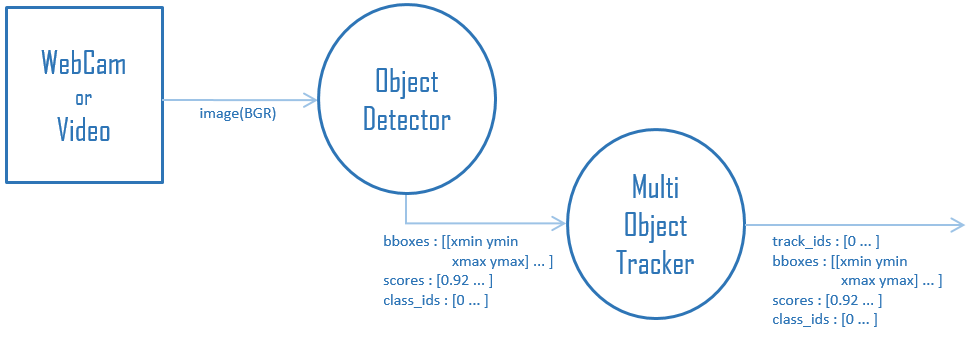
Tracking-by-Detection形式のMOT(Multi Object Tracking)について、
DetectionとTrackingの処理を分離して寄せ集めたフレームワークです。
09.MOT.mp4
Usage
デモの実行方法は以下です。
python main.py
- --device
カメラデバイス番号の指定
デフォルト:0 - --movie
動画ファイルの指定 ※指定時はカメラデバイスより優先
デフォルト:指定なし - --detector
Object Detectionのモデル選択
yolox, efficientdet, ssd, centernet, nanodet, mediapipe_face, mediapipe_hand の何れかを指定
デフォルト:yolox - --tracker
トラッキングアルゴリズムの選択
motpy, bytetrack, norfair の何れかを指定
デフォルト:bytetrack
Direcotry
│ main.py
│ test.mp4
├─Detector
│ │ detector.py
│ └─xxxxxxxx
│ │ xxxxxxxx.py
│ │ config.json
│ │ LICENSE
│ └─model
│ xxxxxxxx.onnx
└─Tracker
│ tracker.py
└─yyyyyyyy
│ yyyyyyyy.py
│ config.json
│ LICENSE
└─tracker
各モデル、トラッキングアルゴリズムを格納しているディレクトリには、
ライセンス条項とコンフィグを同梱しています。
Detector
| モデル名 | 取得元リポジトリ | ライセンス | 備考 |
|---|---|---|---|
| YOLOX | Megvii-BaseDetection/YOLOX | Apache-2.0 | YOLOX-ONNX-TFLite-Sampleにて ONNX化したモデルを使用 |
| EfficientDet | tensorflow/models | Apache-2.0 | Object-Detection-API-TensorFlow2ONNXにて ONNX化したモデルを使用 |
| SSD MobileNet v2 FPNLite | tensorflow/models | Apache-2.0 | Object-Detection-API-TensorFlow2ONNXにて ONNX化したモデルを使用 |
| CenterNet | tensorflow/models | Apache-2.0 | Object-Detection-API-TensorFlow2ONNXにて ONNX化したモデルを使用 |
| NanoDet | RangiLyu/nanodet | Apache-2.0 | NanoDet-ONNX-Sampleにて ONNX化したモデルを使用 |
| MediaPipe Face Detection | google/mediapipe | Apache-2.0 | 目、鼻、口、耳のキーポイントは未使用 |
| MediaPipe Hands | google/mediapipe | Apache-2.0 | ランドマークから外接矩形を算出し使用 |
Tracker
| アルゴリズム名 | 取得元リポジトリ | ライセンス | 備考 |
|---|---|---|---|
| motpy | wmuron/motpy | MIT | マルチクラス対応 |
| ByteTrack | ifzhang/ByteTrack | MIT | - |
| Norfair | tryolabs/norfair | MIT | - |
Author
高橋かずひと(https://twitter.com/KzhtTkhs)
License
MOT-Tracking-by-Detection-Pipeline is under MIT License.
※MOT-Tracking-by-Detection-Pipelineのソースコード自体はMIT Licenseでの提供ですが、
各アルゴリズムのソースコードは、それぞれのライセンスに従います。
詳細は各ディレクトリ同梱のLICENSEファイルをご確認ください。
License(Movie)
サンプル動画はNHKクリエイティブ・ライブラリーのイタリア ミラノの横断歩道を使用しています。

 326 Dec 30, 2022
326 Dec 30, 2022
 55 Dec 27, 2022
55 Dec 27, 2022
 22 Dec 24, 2022
22 Dec 24, 2022
 325 Dec 13, 2022
325 Dec 13, 2022
 399 Jan 02, 2023
399 Jan 02, 2023
 38 Dec 07, 2022
38 Dec 07, 2022
 77 Dec 27, 2022
77 Dec 27, 2022
 260 Dec 28, 2022
260 Dec 28, 2022
 254 Jan 02, 2023
254 Jan 02, 2023
 122 Dec 11, 2022
122 Dec 11, 2022
 74 Dec 03, 2022
74 Dec 03, 2022
 9 Dec 27, 2022
9 Dec 27, 2022
 22 Mar 13, 2022
22 Mar 13, 2022
 1.3k Dec 23, 2022
1.3k Dec 23, 2022
 127 Dec 23, 2022
127 Dec 23, 2022
 136 Dec 29, 2022
136 Dec 29, 2022
 59 Dec 06, 2022
59 Dec 06, 2022
 55 Dec 30, 2022
55 Dec 30, 2022
 184 Dec 11, 2022
184 Dec 11, 2022
 24 Oct 24, 2022
24 Oct 24, 2022