neural-style-pt
This is a PyTorch implementation of the paper A Neural Algorithm of Artistic Style by Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. The code is based on Justin Johnson's Neural-Style.
The paper presents an algorithm for combining the content of one image with the style of another image using convolutional neural networks. Here's an example that maps the artistic style of The Starry Night onto a night-time photograph of the Stanford campus:



Applying the style of different images to the same content image gives interesting results. Here we reproduce Figure 2 from the paper, which renders a photograph of the Tubingen in Germany in a variety of styles:






Here are the results of applying the style of various pieces of artwork to this photograph of the golden gate bridge:












Content / Style Tradeoff
The algorithm allows the user to trade-off the relative weight of the style and content reconstruction terms, as shown in this example where we port the style of Picasso's 1907 self-portrait onto Brad Pitt:





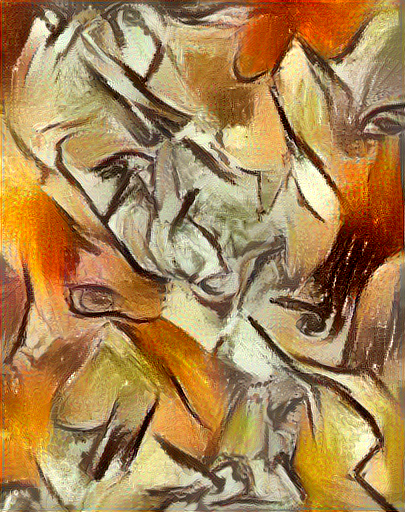
Style Scale
By resizing the style image before extracting style features, we can control the types of artistic features that are transfered from the style image; you can control this behavior with the -style_scale flag. Below we see three examples of rendering the Golden Gate Bridge in the style of The Starry Night. From left to right, -style_scale is 2.0, 1.0, and 0.5.



Multiple Style Images
You can use more than one style image to blend multiple artistic styles.
Clockwise from upper left: "The Starry Night" + "The Scream", "The Scream" + "Composition VII", "Seated Nude" + "Composition VII", and "Seated Nude" + "The Starry Night"




Style Interpolation
When using multiple style images, you can control the degree to which they are blended:



Transfer style but not color
If you add the flag -original_colors 1 then the output image will retain the colors of the original image.



Setup:
Dependencies:
Optional dependencies:
- For CUDA backend:
- CUDA 7.5 or above
- For cuDNN backend:
- cuDNN v6 or above
- For ROCm backend:
- ROCm 2.1 or above
- For MKL backend:
- MKL 2019 or above
- For OpenMP backend:
- OpenMP 5.0 or above
After installing the dependencies, you'll need to run the following script to download the VGG model:
python models/download_models.py
This will download the original VGG-19 model. The original VGG-16 model will also be downloaded. By default the original VGG-19 model is used.
If you have a smaller memory GPU then using NIN Imagenet model will be better and gives slightly worse yet comparable results. You can get the details on the model from BVLC Caffe ModelZoo. The NIN model is downloaded when you run the download_models.py script.
You can find detailed installation instructions for Ubuntu and Windows in the installation guide.
Usage
Basic usage:
python neural_style.py -style_image <image.jpg> -content_image <image.jpg>
cuDNN usage with NIN Model:
python neural_style.py -style_image examples/inputs/picasso_selfport1907.jpg -content_image examples/inputs/brad_pitt.jpg -output_image profile.png -model_file models/nin_imagenet.pth -gpu 0 -backend cudnn -num_iterations 1000 -seed 123 -content_layers relu0,relu3,relu7,relu12 -style_layers relu0,relu3,relu7,relu12 -content_weight 10 -style_weight 500 -image_size 512 -optimizer adam

To use multiple style images, pass a comma-separated list like this:
-style_image starry_night.jpg,the_scream.jpg.
Note that paths to images should not contain the ~ character to represent your home directory; you should instead use a relative path or a full absolute path.
Options:
-image_size: Maximum side length (in pixels) of the generated image. Default is 512.-style_blend_weights: The weight for blending the style of multiple style images, as a comma-separated list, such as-style_blend_weights 3,7. By default all style images are equally weighted.-gpu: Zero-indexed ID of the GPU to use; for CPU mode set-gputoc.
Optimization options:
-content_weight: How much to weight the content reconstruction term. Default is 5e0.-style_weight: How much to weight the style reconstruction term. Default is 1e2.-tv_weight: Weight of total-variation (TV) regularization; this helps to smooth the image. Default is 1e-3. Set to 0 to disable TV regularization.-num_iterations: Default is 1000.-init: Method for generating the generated image; one ofrandomorimage. Default israndomwhich uses a noise initialization as in the paper;imageinitializes with the content image.-init_image: Replaces the initialization image with a user specified image.-optimizer: The optimization algorithm to use; eitherlbfgsoradam; default islbfgs. L-BFGS tends to give better results, but uses more memory. Switching to ADAM will reduce memory usage; when using ADAM you will probably need to play with other parameters to get good results, especially the style weight, content weight, and learning rate.-learning_rate: Learning rate to use with the ADAM optimizer. Default is 1e1.-normalize_gradients: If this flag is present, style and content gradients from each layer will be L1 normalized.
Output options:
-output_image: Name of the output image. Default isout.png.-print_iter: Print progress everyprint_iteriterations. Set to 0 to disable printing.-save_iter: Save the image everysave_iteriterations. Set to 0 to disable saving intermediate results.
Layer options:
-content_layers: Comma-separated list of layer names to use for content reconstruction. Default isrelu4_2.-style_layers: Comma-separated list of layer names to use for style reconstruction. Default isrelu1_1,relu2_1,relu3_1,relu4_1,relu5_1.
Other options:
-style_scale: Scale at which to extract features from the style image. Default is 1.0.-original_colors: If you set this to 1, then the output image will keep the colors of the content image.-model_file: Path to the.pthfile for the VGG Caffe model. Default is the original VGG-19 model; you can also try the original VGG-16 model.-pooling: The type of pooling layers to use; one ofmaxoravg. Default ismax. The VGG-19 models uses max pooling layers, but the paper mentions that replacing these layers with average pooling layers can improve the results. I haven't been able to get good results using average pooling, but the option is here.-seed: An integer value that you can specify for repeatable results. By default this value is random for each run.-multidevice_strategy: A comma-separated list of layer indices at which to split the network when using multiple devices. See Multi-GPU scaling for more details.-backend:nn,cudnn,openmp, ormkl. Default isnn.mklrequires Intel's MKL backend.-cudnn_autotune: When using the cuDNN backend, pass this flag to use the built-in cuDNN autotuner to select the best convolution algorithms for your architecture. This will make the first iteration a bit slower and can take a bit more memory, but may significantly speed up the cuDNN backend.
Frequently Asked Questions
Problem: The program runs out of memory and dies
Solution: Try reducing the image size: -image_size 256 (or lower). Note that different image sizes will likely require non-default values for -style_weight and -content_weight for optimal results. If you are running on a GPU, you can also try running with -backend cudnn to reduce memory usage.
Problem: -backend cudnn is slower than default NN backend
Solution: Add the flag -cudnn_autotune; this will use the built-in cuDNN autotuner to select the best convolution algorithms.
Problem: Get the following error message:
Missing key(s) in state_dict: "classifier.0.bias", "classifier.0.weight", "classifier.3.bias", "classifier.3.weight". Unexpected key(s) in state_dict: "classifier.1.weight", "classifier.1.bias", "classifier.4.weight", "classifier.4.bias".
Solution: Due to a mix up with layer locations, older models require a fix to be compatible with newer versions of PyTorch. The included donwload_models.py script will automatically perform these fixes after downloading the models.
Memory Usage
By default, neural-style-pt uses the nn backend for convolutions and L-BFGS for optimization. These give good results, but can both use a lot of memory. You can reduce memory usage with the following:
- Use cuDNN: Add the flag
-backend cudnnto use the cuDNN backend. This will only work in GPU mode. - Use ADAM: Add the flag
-optimizer adamto use ADAM instead of L-BFGS. This should significantly reduce memory usage, but may require tuning of other parameters for good results; in particular you should play with the learning rate, content weight, and style weight. This should work in both CPU and GPU modes. - Reduce image size: If the above tricks are not enough, you can reduce the size of the generated image; pass the flag
-image_size 256to generate an image at half the default size.
With the default settings, neural-style-pt uses about 3.7 GB of GPU memory on my system; switching to ADAM and cuDNN reduces the GPU memory footprint to about 1GB.
Speed
Speed can vary a lot depending on the backend and the optimizer. Here are some times for running 500 iterations with -image_size=512 on a Tesla K80 with different settings:
-backend nn -optimizer lbfgs: 117 seconds-backend nn -optimizer adam: 100 seconds-backend cudnn -optimizer lbfgs: 124 seconds-backend cudnn -optimizer adam: 107 seconds-backend cudnn -cudnn_autotune -optimizer lbfgs: 109 seconds-backend cudnn -cudnn_autotune -optimizer adam: 91 seconds
Here are the same benchmarks on a GTX 1080:
-backend nn -optimizer lbfgs: 56 seconds-backend nn -optimizer adam: 38 seconds-backend cudnn -optimizer lbfgs: 40 seconds-backend cudnn -optimizer adam: 40 seconds-backend cudnn -cudnn_autotune -optimizer lbfgs: 23 seconds-backend cudnn -cudnn_autotune -optimizer adam: 24 seconds
Multi-GPU scaling
You can use multiple CPU and GPU devices to process images at higher resolutions; different layers of the network will be computed on different devices. You can control which GPU and CPU devices are used with the -gpu flag, and you can control how to split layers across devices using the -multidevice_strategy flag.
For example in a server with four GPUs, you can give the flag -gpu 0,1,2,3 to process on GPUs 0, 1, 2, and 3 in that order; by also giving the flag -multidevice_strategy 3,6,12 you indicate that the first two layers should be computed on GPU 0, layers 3 to 5 should be computed on GPU 1, layers 6 to 11 should be computed on GPU 2, and the remaining layers should be computed on GPU 3. You will need to tune the -multidevice_strategy for your setup in order to achieve maximal resolution.
We can achieve very high quality results at high resolution by combining multi-GPU processing with multiscale generation as described in the paper Controlling Perceptual Factors in Neural Style Transfer by Leon A. Gatys, Alexander S. Ecker, Matthias Bethge, Aaron Hertzmann and Eli Shechtman.
Here is a 4016 x 2213 image generated on a server with eight Tesla K80 GPUs:
The script used to generate this image can be found here.
Implementation details
Images are initialized with white noise and optimized using L-BFGS.
We perform style reconstructions using the conv1_1, conv2_1, conv3_1, conv4_1, and conv5_1 layers and content reconstructions using the conv4_2 layer. As in the paper, the five style reconstruction losses have equal weights.
Citation
If you find this code useful for your research, please cite:
@misc{ProGamerGov2018,
author = {ProGamerGov},
title = {neural-style-pt},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/ProGamerGov/neural-style-pt}},
}

















 87 Dec 06, 2022
87 Dec 06, 2022
 16 Dec 29, 2022
16 Dec 29, 2022
 101 Dec 12, 2022
101 Dec 12, 2022
 21 Dec 02, 2022
21 Dec 02, 2022
 4 Jul 19, 2022
4 Jul 19, 2022
 2 May 19, 2022
2 May 19, 2022
 4 Jan 06, 2023
4 Jan 06, 2023
 1.4k Dec 31, 2022
1.4k Dec 31, 2022
 93 Nov 28, 2022
93 Nov 28, 2022
 32 Dec 15, 2022
32 Dec 15, 2022
 17 Jan 13, 2022
17 Jan 13, 2022
 76 Dec 22, 2022
76 Dec 22, 2022
 2 Jan 28, 2022
2 Jan 28, 2022
 547 Jan 03, 2023
547 Jan 03, 2023
 6 Sep 12, 2022
6 Sep 12, 2022
 20 Nov 15, 2022
20 Nov 15, 2022
 79 Dec 30, 2022
79 Dec 30, 2022
 68 Dec 15, 2022
68 Dec 15, 2022
 3 May 28, 2021
3 May 28, 2021