Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Trong bài viết này mình sẽ sử dụng pretrain model SimCSE_Vietnamese để cải thiện elastic search trong bài toán semantic search.
Mọi người có thể xem bài viết hướng dẫn đầy đủ tại đây.
Cài đặt:
git clone https://github.com/vovanphuc/elastic_simCSE.git
cd elastic_simCSE
pip install -r requirements.txt
Đánh index cho toàn bộ data
python3 index_elastic.py
Search keyword và so sánh giữa BM25 (elasticsearch thường) và simCSE:
streamlit run main.py
Kết quả tìm kiếm:
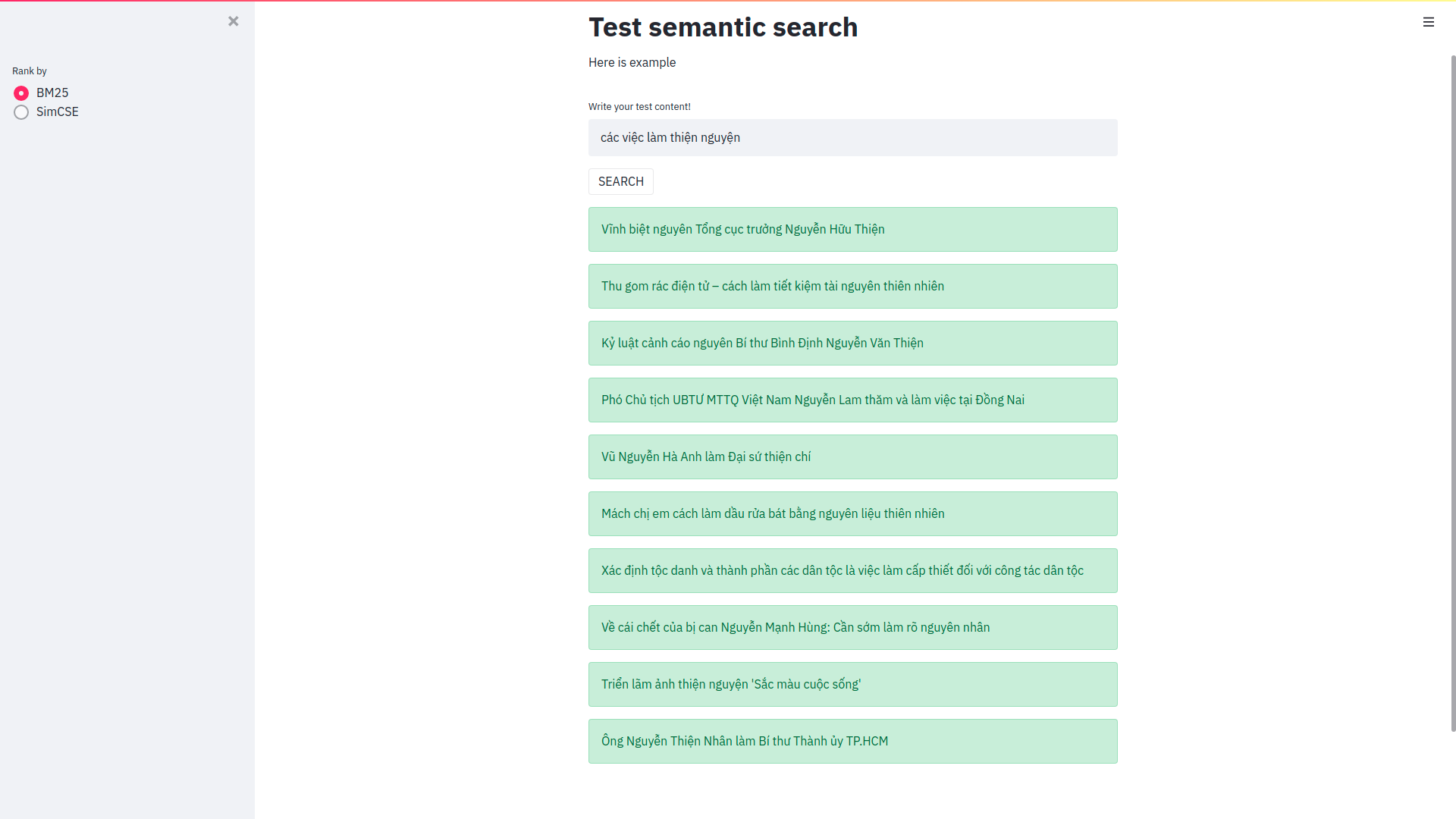
Kết quả khi sử dụng elasticsearch bình thường.
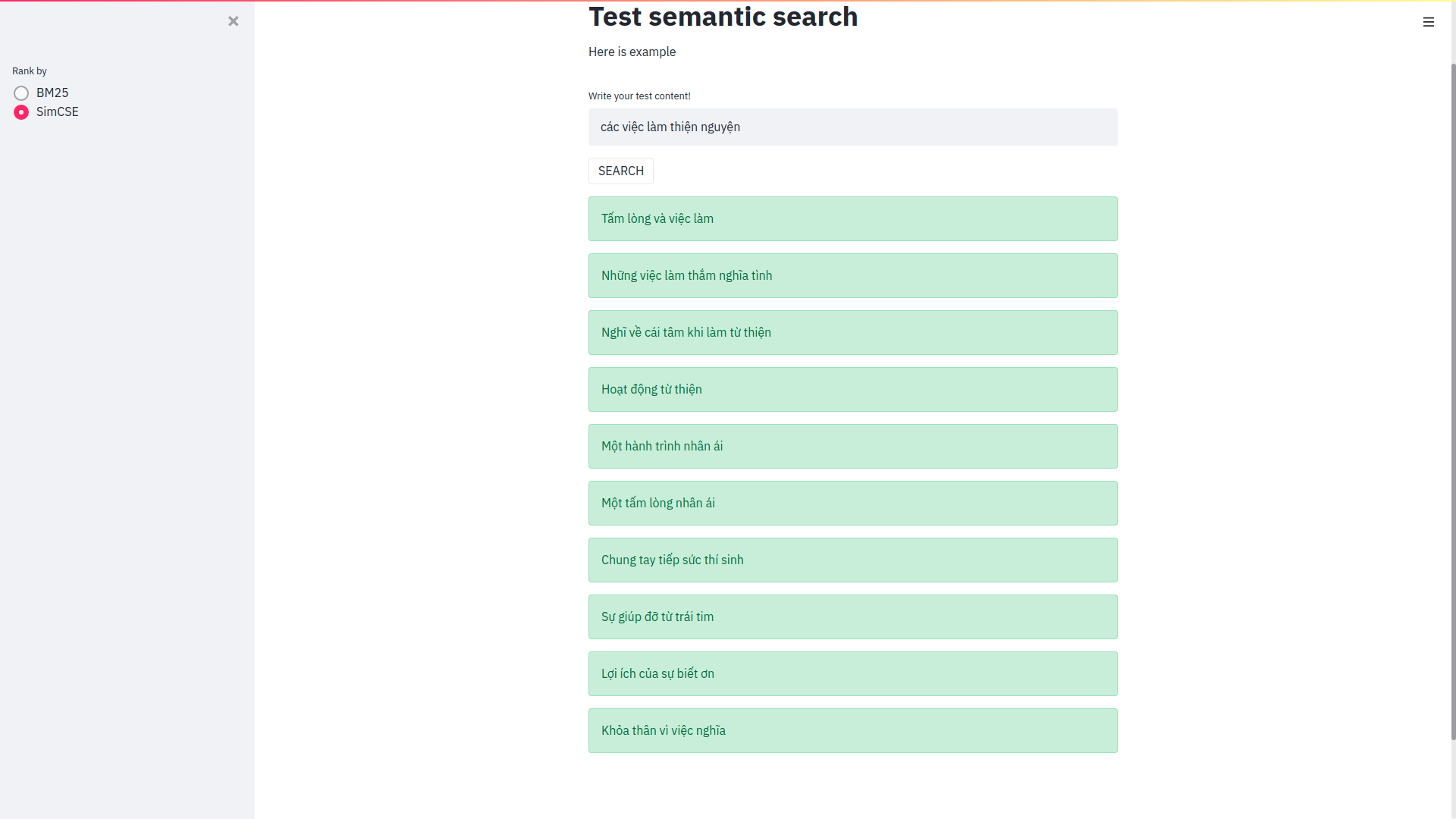
Kết quả khi sử dụng SimCSE_VietNamese.
Contact:
Email: [email protected]
Facebook: facebook.com/vovanphucc
Linkedin: linkedin.com/in/vovanphuc

 1 Mar 20, 2022
1 Mar 20, 2022
 478 Dec 25, 2022
478 Dec 25, 2022
 13 Oct 24, 2022
13 Oct 24, 2022
 6k Dec 31, 2022
6k Dec 31, 2022
 2 Feb 10, 2022
2 Feb 10, 2022
 0 Feb 21, 2022
0 Feb 21, 2022
 169 Dec 21, 2022
169 Dec 21, 2022
 9 Jan 11, 2022
9 Jan 11, 2022
 1 Oct 10, 2022
1 Oct 10, 2022
 77 Dec 27, 2022
77 Dec 27, 2022
 65 Sep 21, 2022
65 Sep 21, 2022
 2 Feb 17, 2022
2 Feb 17, 2022
 5 Oct 21, 2022
5 Oct 21, 2022
 2 Jun 24, 2022
2 Jun 24, 2022
 130 Jan 04, 2023
130 Jan 04, 2023
 6 Feb 10, 2022
6 Feb 10, 2022
 988 Jan 04, 2023
988 Jan 04, 2023
 2 Mar 04, 2022
2 Mar 04, 2022
 2 Nov 13, 2021
2 Nov 13, 2021
 91 Nov 29, 2022
91 Nov 29, 2022