Visual Question Answering in pytorch
/!\ New version of pytorch for VQA available here: https://github.com/Cadene/block.bootstrap.pytorch
This repo was made by Remi Cadene (LIP6) and Hedi Ben-Younes (LIP6-Heuritech), two PhD Students working on VQA at UPMC-LIP6 and their professors Matthieu Cord (LIP6) and Nicolas Thome (LIP6-CNAM). We developed this code in the frame of a research paper called MUTAN: Multimodal Tucker Fusion for VQA which is (as far as we know) the current state-of-the-art on the VQA 1.0 dataset.
The goal of this repo is two folds:
- to make it easier to reproduce our results,
- to provide an efficient and modular code base to the community for further research on other VQA datasets.
If you have any questions about our code or model, don't hesitate to contact us or to submit any issues. Pull request are welcome!
News:
- 16th january 2018: a pretrained vqa2 model and web demo
- 18th july 2017: VQA2, VisualGenome, FBResnet152 (for pytorch) added v2.0 commit msg
- 16th july 2017: paper accepted at ICCV2017
- 30th may 2017: poster accepted at CVPR2017 (VQA Workshop)
Summary:
- Introduction
- Installation
- Reproducing results on VQA 1.0
- Reproducing results on VQA 2.0
- Documentation
- Quick examples
- Citation
- Acknowledgment
Introduction
What is the task about?
The task is about training models in a end-to-end fashion on a multimodal dataset made of triplets:
- an image with no other information than the raw pixels,
- a question about visual content(s) on the associated image,
- a short answer to the question (one or a few words).
As you can see in the illustration bellow, two different triplets (but same image) of the VQA dataset are represented. The models need to learn rich multimodal representations to be able to give the right answers.
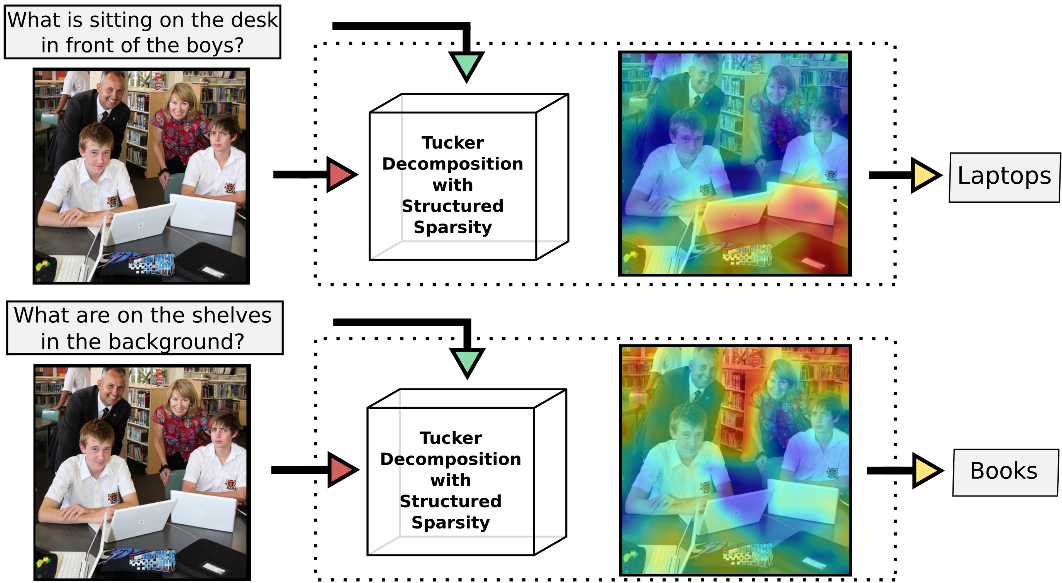
The VQA task is still on active research. However, when it will be solved, it could be very useful to improve human-to-machine interfaces (especially for the blinds).
Quick insight about our method
The VQA community developped an approach based on four learnable components:
- a question model which can be a LSTM, GRU, or pretrained Skipthoughts,
- an image model which can be a pretrained VGG16 or ResNet-152,
- a fusion scheme which can be an element-wise sum, concatenation, MCB, MLB, or Mutan,
- optionally, an attention scheme which may have several "glimpses".
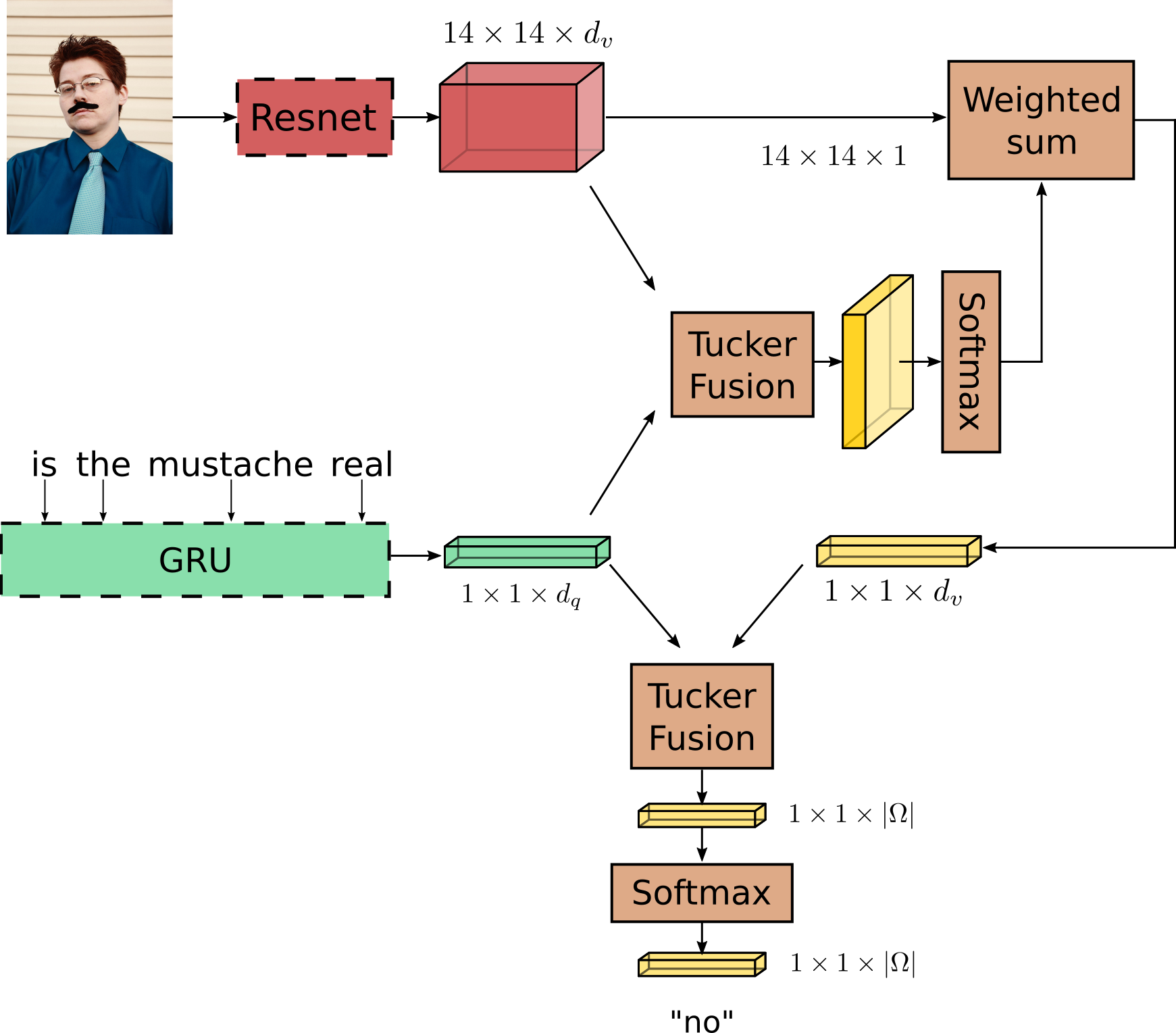
One of our claim is that the multimodal fusion between the image and the question representations is a critical component. Thus, our proposed model uses a Tucker Decomposition of the correlation Tensor to model richer multimodal interactions in order to provide proper answers. Our best model is based on :
- a pretrained Skipthoughts for the question model,
- features from a pretrained Resnet-152 (with images of size 3x448x448) for the image model,
- our proposed Mutan (based on a Tucker Decomposition) for the fusion scheme,
- an attention scheme with two "glimpses".
Installation
Requirements
First install python 3 (we don't provide support for python 2). We advise you to install python 3 and pytorch with Anaconda:
conda create --name vqa python=3
source activate vqa
conda install pytorch torchvision cuda80 -c soumith
Then clone the repo (with the --recursive flag for submodules) and install the complementary requirements:
cd $HOME
git clone --recursive https://github.com/Cadene/vqa.pytorch.git
cd vqa.pytorch
pip install -r requirements.txt
Submodules
Our code has two external dependencies:
- VQA is used to evaluate results files on the valset with the OpendEnded accuracy,
- skip-thoughts.torch is used to import pretrained GRUs and embeddings,
- pretrained-models.pytorch is used to load pretrained convnets.
Data
Data will be automaticaly downloaded and preprocessed when needed. Links to data are stored in vqa/datasets/vqa.py, vqa/datasets/coco.py and vqa/datasets/vgenome.py.
Reproducing results on VQA 1.0
Features
As we first developped on Lua/Torch7, we used the features of ResNet-152 pretrained with Torch7. We ported the pretrained resnet152 trained with Torch7 in pytorch in the v2.0 release. We will provide all the extracted features soon. Meanwhile, you can download the coco features as following:
mkdir -p data/coco/extract/arch,fbresnet152torch
cd data/coco/extract/arch,fbresnet152torch
wget https://data.lip6.fr/coco/trainset.hdf5
wget https://data.lip6.fr/coco/trainset.txt
wget https://data.lip6.fr/coco/valset.hdf5
wget https://data.lip6.fr/coco/valset.txt
wget https://data.lip6.fr/coco/testset.hdf5
wget https://data.lip6.fr/coco/testset.txt
/!\ There are currently 3 versions of ResNet152:
- fbresnet152torch which is the torch7 model,
- fbresnet152 which is the porting of the torch7 in pytorch,
- resnet152 which is the pretrained model from torchvision (we've got lower results with it).
Pretrained VQA models
We currently provide three models trained with our old Torch7 code and ported to Pytorch:
- MutanNoAtt trained on the VQA 1.0 trainset,
- MLBAtt trained on the VQA 1.0 trainvalset and VisualGenome,
- MutanAtt trained on the VQA 1.0 trainvalset and VisualGenome.
mkdir -p logs/vqa
cd logs/vqa
wget http://webia.lip6.fr/~cadene/Downloads/vqa.pytorch/logs/vqa/mutan_noatt_train.zip
wget http://webia.lip6.fr/~cadene/Downloads/vqa.pytorch/logs/vqa/mlb_att_trainval.zip
wget http://webia.lip6.fr/~cadene/Downloads/vqa.pytorch/logs/vqa/mutan_att_trainval.zip
Even if we provide results files associated to our pretrained models, you can evaluate them once again on the valset, testset and testdevset using a single command:
python train.py -e --path_opt options/vqa/mutan_noatt_train.yaml --resume ckpt
python train.py -e --path_opt options/vqa/mlb_noatt_trainval.yaml --resume ckpt
python train.py -e --path_opt options/vqa/mutan_att_trainval.yaml --resume ckpt
To obtain test and testdev results on VQA 1.0, you will need to zip your result json file (name it as results.zip) and to submit it on the evaluation server.
Reproducing results on VQA 2.0
Features 2.0
You must download the coco dataset (and visual genome if needed) and then extract the features with a convolutional neural network.
Pretrained VQA models 2.0
We currently provide three models trained with our current pytorch code on VQA 2.0
- MutanAtt trained on the trainset with the fbresnet152 features,
- MutanAtt trained on thetrainvalset with the fbresnet152 features.
cd $VQAPYTORCH
mkdir -p logs/vqa2
cd logs/vqa2
wget http://data.lip6.fr/cadene/vqa.pytorch/vqa2/mutan_att_train.zip
wget http://data.lip6.fr/cadene/vqa.pytorch/vqa2/mutan_att_trainval.zip
Documentation
Architecture
.
├── options # default options dir containing yaml files
├── logs # experiments dir containing directories of logs (one by experiment)
├── data # datasets directories
| ├── coco # images and features
| ├── vqa # raw, interim and processed data
| ├── vgenome # raw, interim, processed data + images and features
| └── ...
├── vqa # vqa package dir
| ├── datasets # datasets classes & functions dir (vqa, coco, vgenome, images, features, etc.)
| ├── external # submodules dir (VQA, skip-thoughts.torch, pretrained-models.pytorch)
| ├── lib # misc classes & func dir (engine, logger, dataloader, etc.)
| └── models # models classes & func dir (att, fusion, notatt, seq2vec, convnets)
|
├── train.py # train & eval models
├── eval_res.py # eval results files with OpenEnded metric
├── extract.py # extract features from coco with CNNs
└── visu.py # visualize logs and monitor training
Options
There are three kind of options:
- options from the yaml options files stored in the
optionsdirectory which are used as default (path to directory, logs, model, features, etc.) - options from the ArgumentParser in the
train.pyfile which are set to None and can overwrite default options (learning rate, batch size, etc.) - options from the ArgumentParser in the
train.pyfile which are set to default values (print frequency, number of threads, resume model, evaluate model, etc.)
You can easly add new options in your custom yaml file if needed. Also, if you want to grid search a parameter, you can add an ArgumentParser option and modify the dictionnary in train.py:L80.
Datasets
We currently provide four datasets:
- COCOImages currently used to extract features, it comes with three datasets: trainset, valset and testset
- VisualGenomeImages currently used to extract features, it comes with one split: trainset
- VQA 1.0 comes with four datasets: trainset, valset, testset (including test-std and test-dev) and "trainvalset" (concatenation of trainset and valset)
- VQA 2.0 same but twice bigger (however same images than VQA 1.0)
We plan to add:
Models
We currently provide four models:
- MLBNoAtt: a strong baseline (BayesianGRU + Element-wise product)
- MLBAtt: the previous state-of-the-art which adds an attention strategy
- MutanNoAtt: our proof of concept (BayesianGRU + Mutan Fusion)
- MutanAtt: the current state-of-the-art
We plan to add several other strategies in the futur.
Quick examples
Extract features from COCO
The needed images will be automaticaly downloaded to dir_data and the features will be extracted with a resnet152 by default.
There are three options for mode :
att: features will be of size 2048x14x14,noatt: features will be of size 2048,both: default option.
Beware, you will need some space on your SSD:
- 32GB for the images,
- 125GB for the train features,
- 123GB for the test features,
- 61GB for the val features.
python extract.py -h
python extract.py --dir_data data/coco --data_split train
python extract.py --dir_data data/coco --data_split val
python extract.py --dir_data data/coco --data_split test
Note: By default our code will share computations over all available GPUs. If you want to select only one or a few, use the following prefix:
CUDA_VISIBLE_DEVICES=0 python extract.py
CUDA_VISIBLE_DEVICES=1,2 python extract.py
Extract features from VisualGenome
Same here, but only train is available:
python extract.py --dataset vgenome --dir_data data/vgenome --data_split train
Train models on VQA 1.0
Display help message, selected options and run default. The needed data will be automaticaly downloaded and processed using the options in options/vqa/default.yaml.
python train.py -h
python train.py --help_opt
python train.py
Run a MutanNoAtt model with default options.
python train.py --path_opt options/vqa/mutan_noatt_train.yaml --dir_logs logs/vqa/mutan_noatt_train
Run a MutanAtt model on the trainset and evaluate on the valset after each epoch.
python train.py --vqa_trainsplit train --path_opt options/vqa/mutan_att_trainval.yaml
Run a MutanAtt model on the trainset and valset (by default) and run throw the testset after each epoch (produce a results file that you can submit to the evaluation server).
python train.py --vqa_trainsplit trainval --path_opt options/vqa/mutan_att_trainval.yaml
Train models on VQA 2.0
See options of vqa2/mutan_att_trainval:
python train.py --path_opt options/vqa2/mutan_att_trainval.yaml
Train models on VQA (1.0 or 2.0) + VisualGenome
See options of vqa2/mutan_att_trainval_vg:
python train.py --path_opt options/vqa2/mutan_att_trainval_vg.yaml
Monitor training
Create a visualization of an experiment using plotly to monitor the training, just like the picture bellow (click the image to access the html/js file):
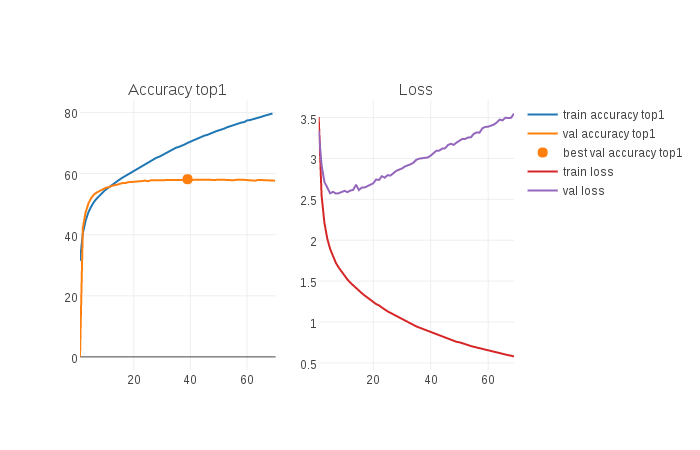
Note that you have to wait until the first open ended accuracy has finished processing and then the html file will be created and will pop out on your default browser. The html will be refreshed every 60 seconds. However, you will currently need to press F5 on your browser to see the change.
python visu.py --dir_logs logs/vqa/mutan_noatt
Create a visualization of multiple experiments to compare them or monitor them like the picture bellow (click the image to access the html/js file):
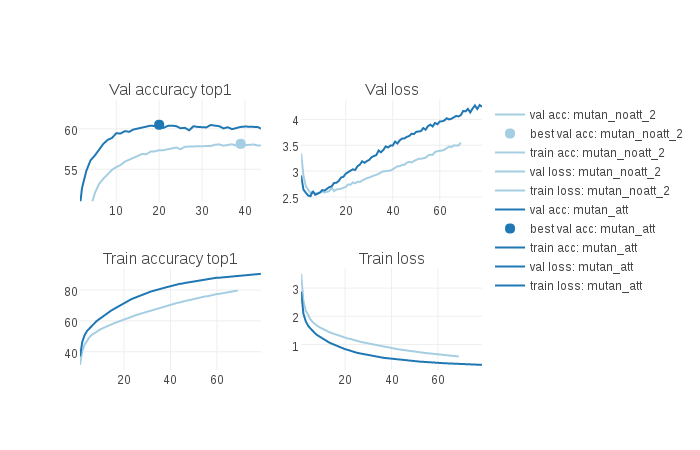
python visu.py --dir_logs logs/vqa/mutan_noatt,logs/vqa/mutan_att
Restart training
Restart the model from the last checkpoint.
python train.py --path_opt options/vqa/mutan_noatt.yaml --dir_logs logs/vqa/mutan_noatt --resume ckpt
Restart the model from the best checkpoint.
python train.py --path_opt options/vqa/mutan_noatt.yaml --dir_logs logs/vqa/mutan_noatt --resume best
Evaluate models on VQA
Evaluate the model from the best checkpoint. If your model has been trained on the training set only (vqa_trainsplit=train), the model will be evaluate on the valset and will run throw the testset. If it was trained on the trainset + valset (vqa_trainsplit=trainval), it will not be evaluate on the valset.
python train.py --vqa_trainsplit train --path_opt options/vqa/mutan_att.yaml --dir_logs logs/vqa/mutan_att --resume best -e
Web demo
You must set your local ip address and port in demo_server.py line 169 and your global ip address and port in demo_web/js/custom.js line 51. The port associated to the global ip address must redirect to your local ip address.
Launch your API:
CUDA_VISIBLE_DEVICES=0 python demo_server.py
Open demo_web/index.html on your browser to access the API with a human interface.
Citation
Please cite the arXiv paper if you use Mutan in your work:
@article{benyounescadene2017mutan,
author = {Hedi Ben-Younes and
R{\'{e}}mi Cad{\`{e}}ne and
Nicolas Thome and
Matthieu Cord},
title = {MUTAN: Multimodal Tucker Fusion for Visual Question Answering},
journal = {ICCV},
year = {2017},
url = {http://arxiv.org/abs/1705.06676}
}
Acknowledgment
Special thanks to the authors of MLB for providing some Torch7 code, MCB for providing some Caffe code, and our professors and friends from LIP6 for the perfect working atmosphere.

















 187 Dec 27, 2022
187 Dec 27, 2022
 48 Dec 29, 2022
48 Dec 29, 2022
 13 Dec 24, 2022
13 Dec 24, 2022
 86 Dec 21, 2022
86 Dec 21, 2022
 4 Dec 15, 2022
4 Dec 15, 2022
 1.6k Jan 01, 2023
1.6k Jan 01, 2023
 284 Dec 31, 2022
284 Dec 31, 2022
 24 Nov 03, 2022
24 Nov 03, 2022
 75 Dec 13, 2022
75 Dec 13, 2022
 12 Sep 02, 2022
12 Sep 02, 2022
 2 Sep 24, 2022
2 Sep 24, 2022
 1 May 24, 2022
1 May 24, 2022
 34 Dec 05, 2022
34 Dec 05, 2022
 1 Dec 14, 2021
1 Dec 14, 2021
 32 Dec 23, 2022
32 Dec 23, 2022
 53 Jul 17, 2022
53 Jul 17, 2022
 18 Nov 18, 2022
18 Nov 18, 2022
 47 Nov 24, 2022
47 Nov 24, 2022
 69 Dec 12, 2022
69 Dec 12, 2022
 5 Oct 18, 2022
5 Oct 18, 2022