Dear Authors of FedScale,
I didn't want to comment too much on FedScale because I thought all the experts in the field knew the truth. But you promote your outdated paper for a long time without based on facts and your co-author (e.g., Jiachen) always publicly claim the inaccurate advantages of FedScale over FedML on the Internet, which is a deep harm and disrespect to FedML's past academic efforts and current industrialization efforts. Therefore, it is necessary for me to state some facts here, and let people know the truth.
Summary
FedScale paper have adopted the method of evaluating the old version of FedML during the ICML submission (3 months expired at the time of submission), and still did not mention it during Camera Ready (6 months expired) and during the conference speech period (about 10 months expired). The issue of comparing with FedML in an old version, and in this case, widely publicizing its so-called advantages that are not based on facts and new version, has brought a lot of harm and loss to FedML. Aside from the harm caused by the publication and publicity of the old version, even the comparison of the old version is academically inaccurate and wrong: there are 4 core arguments in the paper, 3 are not in line with the facts, and the fourth has highly overlaps with existing papers. In addition, the ICML paper substantially overlaps with a proceeding-based published paper at another workshop. Based on these issues, we think this paper violates the dual submission policy and does not meet the criteria for publication. We also hope FedScale team can update paper (https://arxiv.org/pdf/2105.11367v5.pdf) and media articles (Zhihu, etc.) in a timely manner, clarifying the above issues, avoiding misunderstandings among users and peers in the Chinese and English communities, and terminating unnecessary reputation damage .
Issue 1: FedScale widely promotes its so-called advantages that are not based new version (10 months outdated until today)
- Your ICML 2022 paper uses a version 3.5 months before the submission deadline, 6 months before the review/rebuttal deadline (review open date). Reviewers should notice this issue. I believe the rebuttal date is much after our advanced feature release, not mentioning that you only compare with part of our code in an old version.
- You promote your ICML 2022 paper on social media (e.g., Zhihu) without mentioning the version date and ID. The earliest date of this promotion is already 6 months outdated, compared to the date you compare with FedML. At that time, FedML already released new version with many advanced features. Your improper claim in the promotion raises too much misunderstanding and concern of FedML company, which invades our reputation a lot (friends and investors come to ask the issue).
- The date you present your ICML 2022 in the main conference is already 10 months outdated. You promoted it at social media during that week. Unfortunately, you still didn't address the version ID issue. This further invades FedML reputation (we got concern messages from friends and users at that week). The fact is that we already released a lot of features. Even so, FedML team still kept silent and still believe people can tell the truth.
- Your paper didn't mention the version in the main text. Until today, the version ID you mentioned in the appendix is a version that is already 10 months outdated.
https://arxiv.org/pdf/2105.11367v5.pdf - Table 1's comment on FedML is fully wrong and outdated.
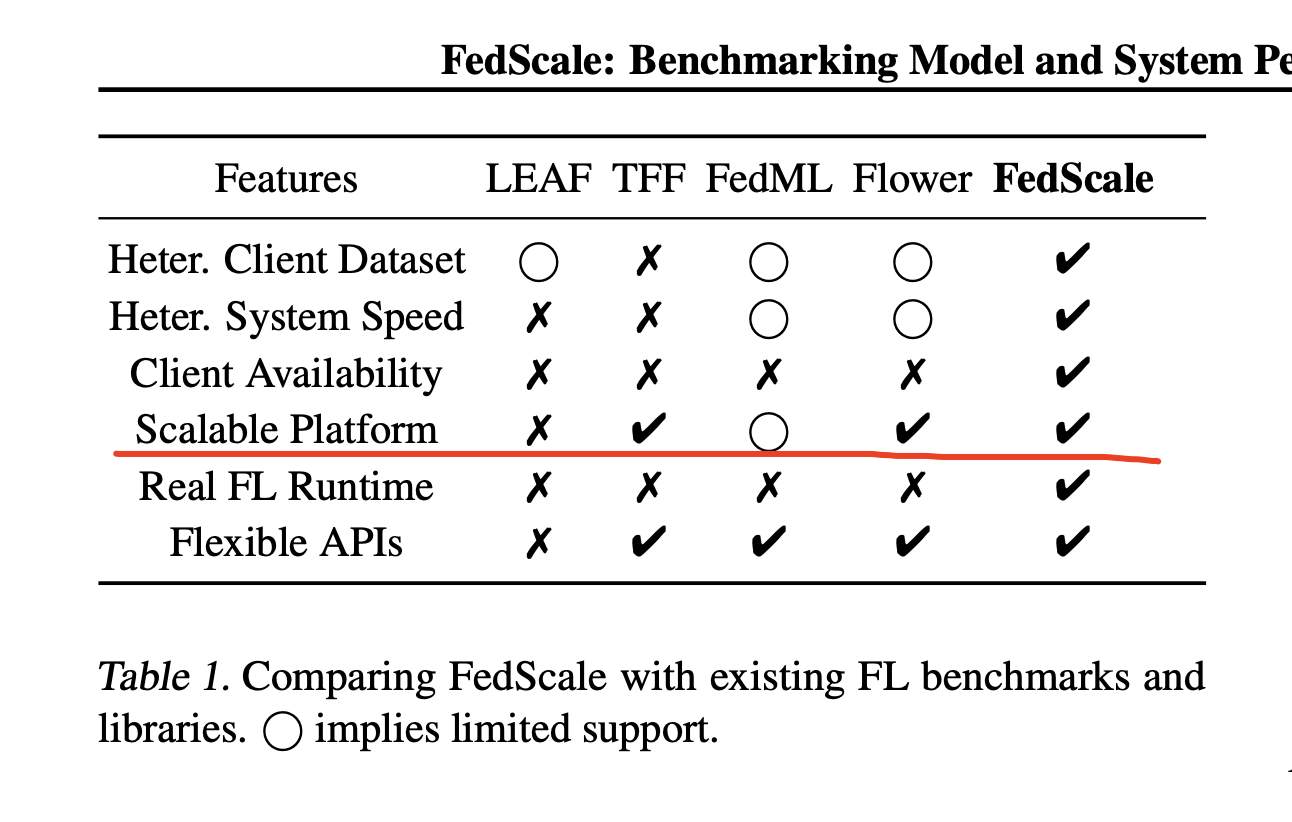
My comments: It's surprising to many engineers and researchers at USC and FedML that you overclaim that your platform has stronger "Scalable Platform". Please check our platform at https://fedml.ai.
FedML AI platform releases the world’s federated learning open platform on the public cloud with an in-depth introduction of products and technologies!
https://medium.com/@FedML/fedml-ai-platform-releases-the-worlds-federated-learning-open-platform-on-public-cloud-with-an-8024e68a70b6
Issues 2: The evaluation of FedML old version (Oct, 2021) is not based on facts. In addition, the core contribution of FedScale ICML paper (system and data heterogeneity) overlaps a published paper Oort. ICML reviewers should be aware of these issues.
Quote from https://arxiv.org/pdf/2105.11367v5.pdf: "First, they are limited in the versatility of data for various real-world FL applications. Indeed, even though they may have quite a few datasets and FL training tasks (e.g., LEAF (Caldas et al.,
2019)), their datasets often contain synthetically generated partitions derived from conventional datasets (e.g., CIFAR)
and do not represent realistic characteristics. This is because these benchmarks are mostly borrowed from traditional ML benchmarks (e.g., MLPerf (Mattson et al., 2020)) or designed for simulated FL environments like TensorFlow Federated (TFF) (tff) or PySyft (pys). Second, existing benchmarks often overlook system speed, connectivity, and availability of the clients (e.g., FedML (He et al., 2020) and Flower (Beutel et al., 2021)). This discourages FL efforts from considering system efficiency and leads to overly optimistic statistical performance (§2). Third, their datasets are primarily small-scale, because their experimental environments are unable to emulate large-scale FL deployments. While real FL often involves thousands of participants in each training round (Kairouz et al., 2021b; Yang et al., 2018), most existing benchmarking platforms can merely support the training of tens of participants per round. Finally, most of them lack user-friendly APIs for automated integration, resulting in great engineering efforts for benchmarking at scale"
These four core arguments are not based on facts:
- The 1st argument (about dataset) is wrong and not in line with the fact and exsisting works. We already support a large number of datasets in 2020 that conform to the habits of the ICML/NeurIPS/ICLR community: https://doc.fedml.ai/simulation/user_guide/datasets-and-models.html, and slso supports real datasets (FedNLP, FedGraphNN, FedCV, FedIoT) contained in massive applications: https://github.com/FedML-AI/FedML/tree/master/python/app. The timelines for these works all predate October 2021. These works have been published in the workshops and main conferences of major conferences. It is important to note that these works were published 6 months earlier than the old version of FedML mentioned in the ICML paper, and basically more than half a year earlier than the ICML 2022 submission deadline.
FedGraphNN: FedGraphNN: A Federated Learning System and Benchmark for Graph Neural Networks. https://arxiv.org/abs/2104.07145 (Arxiv Time: 4 Apr 2021)
FedNLP: FedNLP: Benchmarking Federated Learning Methods for Natural Language Processing Tasks. https://arxiv.org/abs/2104.08815 (Arxiv Time: 8 Apr 2021)
FedCV: https://arxiv.org/abs/2111.11066 (Arxiv time: 22 Nov 2021)
FedIoT: https://arxiv.org/abs/2106.07976v1 (Arxiv time: 15 Jun 2021)
- the 3rd argument (unable to emulate large-scale FL deployments) is also not based on facts:
(1) https://arxiv.org/pdf/2105.11367v5.pdf - "FedML can only support 30 participants because of its suboptimal scalability, which under-reports the FL performance that the algorithm can indeed achieve"
My comments: This doesn't match the fact. From the oldest version of FedML, it always supports arbitrary number of clients training by using the single process (standalone in the old version) sequential training. In addition, our users can run parallel experiments (one GPU per job/run) with multiple GPUs to accelerate the hyperparameter tuning. This avoids communication cost in emulator level. In our latest version, it supports sequential training with multiple nodes via efficient scheduler. Therefore, such a comment does not match the fact.
(3) https://arxiv.org/pdf/2105.11367v5.pdf - "Third, their datasets are primarily small-scale, because their experimental environments are unable to emulate large-scale FL deployments."
My comments: this is also misleading to paper readers. In our old version, we already support many large-scale datasets for reseachers in ML community: https://doc.fedml.ai/simulation/user_guide/datasets-and-models.html. They are widely used by many ICML/NeurIPS/ICLR papers. Recently, our latest version even support many realistic and large-scale datasetes in CV, NLP, healthcare, graph neural networks, and IoT. See some links at:
https://github.com/FedML-AI/FedML/tree/master/python/app
https://github.com/FedML-AI/FedML/tree/master/iot
Each one is supported by top-tier conference papers. For example, the NLP one (https://arxiv.org/abs/2104.08815) is connected to Huggingface and accepted to NACCL 2022.
- the 4th argument (API not friendly) also does not respect FedML's works.
We released FedNLP, FedGraphNN, FedCV, FedIoT and other application frameworks as early as 1.5 years ago (https://open.fedml.ai/platform/appStore), all based on the FedML core framework, after so many applications Verification has long proven its convenience. Regardless of these differences, the best way to prove "convenience" is the user data, which you can look at our GitHub stars, paper citations, platform user number, etc.
We also put together a brief introduction to APIs to see who is more convenient: https://medium.com/@FedML/fedml-releases-simple-and-flexible-apis-boosting-innovation-in-algorithm-and-system-optimization-b21c2f4b88c8
- Regarding 2nd key argument, we think it has been mentioned in another paper Oort (highly overlapping, please compare the two papers; Oort is here: https://arxiv.org/abs/2010.06081), which does not belong to the spirit of ICML that requires independent contribution and novelty of a published paper. Specifically, system heterogeneity (system speed, connectivity and availability) has been described in Section 2.2 of Oort's original paper, and also clearly mentioned in Section 7.1 of the experimental section. System speed, connectivity and availability are the same things as Section 3.2 in the original FedScale article. Oort says:
We simulate real-world heterogeneous client system performance and data in both training and testing evaluations using an open-source FL benchmark [48]: (1) Heterogeneous device runtimes (speed) of different models, network throughput/connectivity (connectivity), device model, and availability are emulated using data from AI Benchmark [1] and Network Measurements on mobiles [6].
Issues 3: issues in FedScale and Oort: unrealistic overlap between system speed, data distribution, and client device availability
Quote from https://arxiv.org/pdf/2105.11367v5.pdf: "Second, existing benchmarks often overlook system speed, connectivity, and availability of the clients (e.g., FedML (He et al., 2020) and Flower (Beutel et al., 2021)). This discourages FL efforts from considering system efficiency and leads to overly optimistic statistical performance (§2)."
My comments: this is misleading. My question is "how can you match a realistic overlapping of system speed, data distribution statistics, and client device availability?" You get them from three independent databases, which does not match the practice. Then you build Oort based on this unrealistic assumption. FedScale team never clearly answers this question. This benchmark definitely brings issues in numerical optimization theory. We ML and System researchers do not hope this misleading benchmark to misguide the research in ML area.
Moreover, such a comment ("existing benchmarks often overlook system speed, connectivity, and availability of the clients") is extremely disrespectful to the work of an industrialized team who has expertise more than this. Distributed system is the hardcore area that FedML engineering team focuses on. Maybe your team only reads part of the materials (white paper? or part of our source code?). Please refer to a comprehensive material list here:
FedML Homepage: https://fedml.ai/
FedML Open Source: https://github.com/FedML-AI
FedML Platform: https://open.fedml.ai
FedML Use Cases: https://open.fedml.ai/platform/appStore
FedML Documentation: https://doc.fedml.ai
FedML Research: https://fedml.ai/research-papers/ (50+ papers covering many aspects including security and privacy)
Issues 4: FedScale only supports running on the same number of iteration locally, however, many ICML/NeurIPS/ICLR papers (almost all) are working on the same number of epochs. This differs from the entire ML community significantly.
https://github.com/SymbioticLab/FedScale/blob/51cc4a1e0ab553cd79ecb59af211008788f1af39/fedscale/core/execution/client.py#L50
Issue 5: We suspect that FedScale ICML paper violates the dual submission policy in ML community
The FedScale ICML version (ICML proceeding https://proceedings.mlr.press/v162/lai22a/lai22a.pdf) overlaps substantially with a workshop paper with proceeding (https://dl.acm.org/doi/10.1145/3477114.3488760). The workshop date is October 2021, at least 3 months earlier than the ICML 2022 submission deadline. Normally, ICML/NeurIPS/ICLR do not allow submissions that are already published somewhere else with proceeding using the same title/author/core contribution.
(1) These two papers have the same title "FedScale: Benchmarking Model and System Performance of Federated Learning at Scale".
(2) These two papers have 5 authors overlapping
Workshop authors: Fan Lai, Yinwei Dai, Xiangfeng Zhu, Harsha V. Madhyastha, Mosharaf Chowdhury
ICML authors: Fan Lai, Yinwei Dai, Sanjay S. Singapuram, Jiachen Liu, Xiangfeng Zhu, Harsha V. Madhyastha, Mosharaf Chowdhury
(two authors are added in the ICML version)
(3) substantial contribution and core argument overlapping. See the two key paragraphs in these two papers.

 Note: these two papers are talking about the same arguments with the same wording.
Note: these two papers are talking about the same arguments with the same wording.
ICML policy: https://icml.cc/Conferences/2022/StyleAuthorInstructions
As mentioned in issue 2, FedScale ICML 2022 paper also overlaps a key contribution with another published paper at OSDI 2021:
The 2nd key argument has been mentioned in another paper Oort (highly overlapping, please compare the two papers; Oort is here: https://arxiv.org/abs/2010.06081), which does not belong to the spirit of ICML that requires independent contribution and novelty of a published paper.
Specifically, system heterogeneity (system speed, connectivity and availability) has been described in Section 2.2 of Oort's original paper, and also clearly mentioned in Section 7.1 of the experimental section. System speed, connectivity and availability are the same things as Section 3.2 in the original FedScale article. Oort says:
We simulate real-world heterogeneous client system performance and data in both training and testing evaluations using an open-source FL benchmark [48]: (1) Heterogeneous device runtimes (speed) of different models, network throughput/connectivity (connectivity), device model, and availability are emulated using data from AI Benchmark [1] and Network Measurements on mobiles [6].
Versions / Dependencies
Code: https://github.com/SymbioticLab/FedScale (51cc4a1)
Paper: https://arxiv.org/pdf/2105.11367v5.pdf (v5)
help wanted


![[<FedScale component: Core|Dataloader|etc...>]](https://avatars.githubusercontent.com/u/104707526?v=4)




![[Core] Async aggregator freezes during evaluation](https://avatars.githubusercontent.com/u/12105532?v=4)





 9 Oct 25, 2022
9 Oct 25, 2022
 25 Oct 14, 2022
25 Oct 14, 2022
 41 Nov 09, 2022
41 Nov 09, 2022
 247 Dec 28, 2022
247 Dec 28, 2022
 33 Dec 23, 2022
33 Dec 23, 2022
 85 Dec 15, 2022
85 Dec 15, 2022
 473 Jan 09, 2023
473 Jan 09, 2023
 276 Dec 31, 2022
276 Dec 31, 2022
 1 Nov 12, 2021
1 Nov 12, 2021
 6 Sep 15, 2022
6 Sep 15, 2022
 1 Dec 27, 2021
1 Dec 27, 2021
 7 Aug 08, 2022
7 Aug 08, 2022
 15 Oct 17, 2022
15 Oct 17, 2022
 116 Jan 04, 2023
116 Jan 04, 2023
 9 Sep 28, 2022
9 Sep 28, 2022
 86 Dec 29, 2022
86 Dec 29, 2022
 108 Dec 29, 2022
108 Dec 29, 2022
 147 Dec 28, 2022
147 Dec 28, 2022
 5 Jan 05, 2023
5 Jan 05, 2023
 44 Dec 17, 2022
44 Dec 17, 2022