AST: Audio Spectrogram Transformer
- Introduction
- Citing
- Getting Started
- ESC-50 Recipe
- Speechcommands Recipe
- AudioSet Recipe
- Pretrained Models
- Contact
Introduction
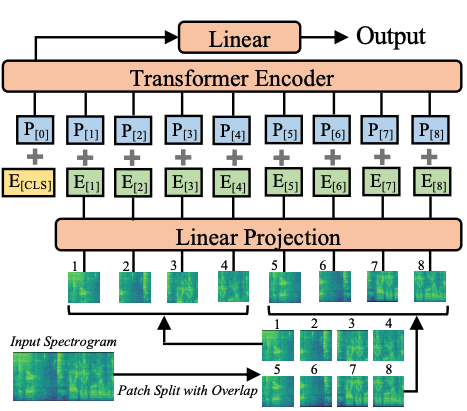
This repository contains the official implementation (in PyTorch) of the Audio Spectrogram Transformer (AST) proposed in the Interspeech 2021 paper AST: Audio Spectrogram Transformer (Yuan Gong, Yu-An Chung, James Glass).
AST is the first convolution-free, purely attention-based model for audio classification which supports variable length input and can be applied to various tasks. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2. For details, please refer to the paper and the ISCA SIGML talk.
Please have a try! AST can be used with a few lines of code, and we also provide recipes to reproduce the SOTA results on AudioSet, ESC-50, and Speechcommands with almost one click.
The AST model file is in src/models/ast_models.py, the recipes are in egs/[audioset,esc50,speechcommands]/run.sh, when you run run.sh, it will call /src/run.py, which will then call /src/dataloader.py and /src/traintest.py, which will then call /src/models/ast_models.py.
Citing
Please cite our paper(s) if you find this repository useful. The first paper proposes the Audio Spectrogram Transformer while the second paper describes the training pipeline that we applied on AST to achieve the new state-of-the-art on AudioSet.
@article{gong2021ast,
title={Ast: Audio spectrogram transformer},
author={Gong, Yuan and Chung, Yu-An and Glass, James},
journal={arXiv preprint arXiv:2104.01778},
year={2021}}
@article{gong2021psla,
title={PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation},
author={Gong, Yuan and Chung, Yu-An and Glass, James},
journal={arXiv preprint arXiv:2102.01243},
year={2021}}
Getting Started
Step 1. Clone or download this repository and set it as the working directory, create a virtual environment and install the dependencies.
cd ast/
python3 -m venv venvast
source venvast/bin/activate
pip install -r requirements.txt
Step 2. Test the AST model.
ASTModel(label_dim=527, \
fstride=10, tstride=10, \
input_fdim=128, input_tdim=1024, \
imagenet_pretrain=True, audioset_pretrain=False, \
model_size='base384')
Parameters:
label_dim : The number of classes (default:527).
fstride: The stride of patch spliting on the frequency dimension, for 16*16 patchs, fstride=16 means no overlap, fstride=10 means overlap of 6 (used in the paper). (default:10)
tstride: The stride of patch spliting on the time dimension, for 16*16 patchs, tstride=16 means no overlap, tstride=10 means overlap of 6 (used in the paper). (default:10)
input_fdim: The number of frequency bins of the input spectrogram. (default:128)
input_tdim: The number of time frames of the input spectrogram. (default:1024, i.e., 10.24s)
imagenet_pretrain: If True, use ImageNet pretrained model. (default: True, we recommend to set it as True for all tasks.)
audioset_pretrain: IfTrue, use full AudioSet And ImageNet pretrained model. Currently only support base384 model with fstride=tstride=10. (default: False, we recommend to set it as True for all tasks except AudioSet.)
model_size: The model size of AST, should be in [tiny224, small224, base224, base384] (default: base384).
cd ast/src
python
import os
import torch
from models import ASTModel
# download pretrained model in this directory
os.environ['TORCH_HOME'] = '../pretrained_models'
# assume each input spectrogram has 100 time frames
input_tdim = 100
# assume the task has 527 classes
label_dim = 527
# create a pseudo input: a batch of 10 spectrogram, each with 100 time frames and 128 frequency bins
test_input = torch.rand([10, input_tdim, 128])
# create an AST model
ast_mdl = ASTModel(label_dim=label_dim, input_tdim=input_tdim, imagenet_pretrain=True)
test_output = ast_mdl(test_input)
# output should be in shape [10, 527], i.e., 10 samples, each with prediction of 527 classes.
print(test_output.shape)
ESC-50 Recipe
The ESC-50 recipe is in ast/egs/esc50/run_esc.sh, the script will automatically download the ESC-50 dataset and resample it to 16kHz, then run standard 5-cross validation and report the result. The recipe was tested on 4 GTX TITAN GPUs with 12GB memory. The result is saved in ast/egs/esc50/exp/yourexpname/acc_fold.csv (the accuracy of fold 1-5 and the averaged accuracy), you can also check details in result.csv and best_result.csv (accuracy, AUC, loss, etc of each epoch / best epoch). We attached our log file in ast/egs/esc50/test-esc50-f10-t10-p-b48-lr1e-5, the model achieves 95.75% accuracy.
To run the recipe, simply comment out . /data/sls/scratch/share-201907/slstoolchainrc in ast/egs/esc50/run_esc.sh, adjust the path if needed, and run:
cd ast/egs/esc50
(slurm user) sbatch run_esc50.sh
(local user) ./run_esc50.sh
Speechcommands V2 Recipe
The Speechcommands recipe is in ast/egs/speechcommands/run_sc.sh, the script will automatically download the Speechcommands V2 dataset, train an AST model on the training set, validate it on the validation set, and evaluate it on the test set. The recipe was tested on 4 GTX TITAN GPUs with 12GB memory. The result is saved in ast/egs/speechcommands/exp/yourexpname/eval_result.csv in format [val_acc, val_AUC, eval_acc, eval_AUC], you can also check details in result.csv (accuracy, AUC, loss, etc of each epoch). We attached our log file in ast/egs/speechcommends/test-speechcommands-f10-t10-p-b128-lr2.5e-4-0.5-false, the model achieves 98.12% accuracy.
To run the recipe, simply comment out . /data/sls/scratch/share-201907/slstoolchainrc in ast/egs/esc50/run_sc.sh, adjust the path if needed, and run:
cd ast/egs/speechcommands
(slurm user) sbatch run_sc.sh
(local user) ./run_sc.sh
Audioset Recipe
Audioset is a little bit more complex, you will need to prepare your data json files (i.e., train_data.json and eval_data.json) by your self. The reason is that the raw wavefiles of Audioset is not released and you need to download them by yourself. We have put a sample json file in ast/egs/audioset/data/datafiles, please generate files in the same format (You can also refer to ast/egs/esc50/prep_esc50.py and ast/egs/speechcommands/prep_sc.py.). Please keep the label code consistent with ast/egs/audioset/data/class_labels_indices.csv.
Once you have the json files, you will need to generate the sampling weight file of your training data (please check our PSLA paper to see why it is needed).
cd ast/egs/audioset
python gen_weight_file.py ./data/datafiles/train_data.json
Then you just need to change the tr_data and te_data in /ast/egs/audioset/run.sh and then
cd ast/egs/audioset
(slurm user) sbatch run.sh
(local user) ./run.sh
You should get a model achieves 0.448 mAP (without weight averaging) and 0.459 (with weight averaging). This is the best single model reported in the paper. The result of each epoch is saved in ast/egs/audioset/exp/yourexpname/result.csv in format [mAP, mAUC, precision, recall, d_prime, train_loss, valid_loss, cum_mAP, cum_mAUC, lr] , where cum_ results are the checkpoint ensemble results (i.e., averaging the prediction of checkpoint models of each epoch, please check our PSLA paper for details). The result of weighted averaged model is saved in wa_result.csv in format [mAP, AUC, precision, recall, d-prime]. We attached our log file in ast/egs/audioset/test-full-f10-t10-pTrue-b12-lr1e-5/, the model achieves 0.459 mAP.
In order to reproduce ensembe results of 0.475 mAP and 0.485 mAP, please train 3 models use the same setting (i.e., repeat above three times) and train 6 models with different tstride and fstride, and average the output of the models. Please refer to ast/egs/audioset/ensemble.py. We attached our ensemble log in /ast/egs/audioset/exp/ensemble-s.log and ensemble-m.log. You can use our pretrained models (see below) to test ensemble result.
Pretrained Models
We provide full AudioSet pretrained models.
- Full AudioSet, 10 tstride, 10 fstride, with Weight Averaging (0.459 mAP)
- Full AudioSet, 10 tstride, 10 fstride, without Weight Averaging, Model 1 (0.450 mAP)
- Full AudioSet, 10 tstride, 10 fstride, without Weight Averaging, Model 2 (0.448 mAP)
- Full AudioSet, 10 tstride, 10 fstride, without Weight Averaging, Model 3 (0.448 mAP)
- Full AudioSet, 12 tstride, 12 fstride, without Weight Averaging, Model (0.447 mAP)
- Full AudioSet, 14 tstride, 14 fstride, without Weight Averaging, Model (0.443 mAP)
- Full AudioSet, 16 tstride, 16 fstride, without Weight Averaging, Model (0.442 mAP)
Ensemble model 2-4 achieves 0.475 mAP, Ensemble model 2-7 achieves and 0.485 mAP. You can download these models at one click using ast/egs/audioset/download_models.sh. Once you download the model, you can try ast/egs/audioset/ensemble.py, you need to change the eval_data_path and mdl_list to run it. We attached our ensemble log in /ast/egs/audioset/exp/ensemble-s.log and ensemble-m.log.
If you want to finetune AudioSet-pretrained AST model on your task, you can simply set the audioset_pretrain=True when you create the AST model, it will automatically download model 1 (0.459 mAP). In our ESC-50 recipe, AudioSet pretraining is used.
Contact
If you have a question, please bring up an issue (preferred) or send me an email [email protected].

 1 Jan 20, 2022
1 Jan 20, 2022
 290 Dec 25, 2022
290 Dec 25, 2022
 602 Jan 07, 2023
602 Jan 07, 2023
 17 Aug 16, 2022
17 Aug 16, 2022
 81 Dec 16, 2022
81 Dec 16, 2022
 134 Dec 19, 2022
134 Dec 19, 2022
 800 Dec 05, 2022
800 Dec 05, 2022
 18 Sep 26, 2022
18 Sep 26, 2022
 39 Dec 13, 2022
39 Dec 13, 2022
 75 Dec 12, 2022
75 Dec 12, 2022
 266 Dec 28, 2022
266 Dec 28, 2022
 34 Dec 02, 2022
34 Dec 02, 2022
 10 Nov 25, 2022
10 Nov 25, 2022
 265 Dec 22, 2022
265 Dec 22, 2022
 0 Feb 25, 2022
0 Feb 25, 2022
 85 Dec 30, 2022
85 Dec 30, 2022
 115 Dec 18, 2022
115 Dec 18, 2022
 19 Nov 12, 2021
19 Nov 12, 2021
 1.2k Jan 03, 2023
1.2k Jan 03, 2023
 7 Sep 12, 2022
7 Sep 12, 2022