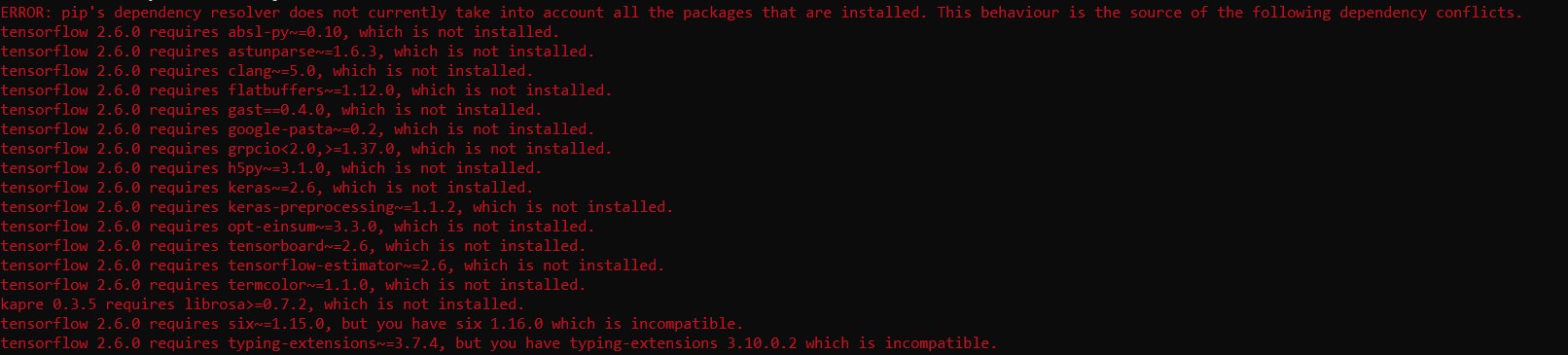
See two instances of PyQtWebEngine below (the first line and the last line) I'm not sure which of the libraries requested for install both require PyQtWebEngine. They have different requirements, maybe add something earlier that addresses both of these dependencies before installing those libraries?:
Collecting PyQtWebEngine-Qt5>=5.15.0
Using cached PyQtWebEngine_Qt5-5.15.2-py3-none-win_amd64.whl (60.0 MB)
Collecting black>=22.3.0
Using cached black-22.8.0-cp39-cp39-win_amd64.whl (1.2 MB)
Collecting pluggy>=1.0.0
Using cached pluggy-1.0.0-py2.py3-none-any.whl (13 kB)
Collecting ujson>=3.0.0
Using cached ujson-5.4.0-cp39-cp39-win_amd64.whl (37 kB)
Collecting python-lsp-jsonrpc>=1.0.0
Using cached python_lsp_jsonrpc-1.0.0-py3-none-any.whl (8.5 kB)
Collecting yapf
Using cached yapf-0.32.0-py2.py3-none-any.whl (190 kB)
Collecting pycodestyle<2.9.0,>=2.8.0
Using cached pycodestyle-2.8.0-py2.py3-none-any.whl (42 kB)
Collecting autopep8<1.7.0,>=1.6.0
Using cached autopep8-1.6.0-py2.py3-none-any.whl (45 kB)
Collecting pydocstyle>=2.0.0
Using cached pydocstyle-6.1.1-py3-none-any.whl (37 kB)
Collecting whatthepatch
Using cached whatthepatch-1.0.2-py2.py3-none-any.whl (11 kB)
Collecting pyflakes<2.5.0,>=2.4.0
Using cached pyflakes-2.4.0-py2.py3-none-any.whl (69 kB)
Collecting flake8<4.1.0,>=4.0.0
Using cached flake8-4.0.1-py2.py3-none-any.whl (64 kB)
Collecting rope>=0.10.5
Using cached rope-1.3.0-py3-none-any.whl (199 kB)
Collecting inflection<1,>0.3.0
Using cached inflection-0.5.1-py2.py3-none-any.whl (9.5 kB)
Collecting ipython-genutils
Using cached ipython_genutils-0.2.0-py2.py3-none-any.whl (26 kB)
Collecting urllib3<1.27,>=1.21.1
Using cached urllib3-1.26.12-py2.py3-none-any.whl (140 kB)
Collecting charset-normalizer<3,>=2
Using cached charset_normalizer-2.1.1-py3-none-any.whl (39 kB)
Requirement already satisfied: certifi>=2017.4.17 in c:\users\user\anaconda3\envs\datascienv\lib\site-packages (from requests>=1.1.0->kat->datascienv) (2022.6.15)
Collecting idna<4,>=2.5
Using cached idna-3.3-py3-none-any.whl (61 kB)
Collecting snowballstemmer>=1.1
Using cached snowballstemmer-2.2.0-py2.py3-none-any.whl (93 kB)
Collecting alabaster<0.8,>=0.7
Using cached alabaster-0.7.12-py2.py3-none-any.whl (14 kB)
Collecting sphinxcontrib-applehelp
Using cached sphinxcontrib_applehelp-1.0.2-py2.py3-none-any.whl (121 kB)
Collecting sphinxcontrib-qthelp
Using cached sphinxcontrib_qthelp-1.0.3-py2.py3-none-any.whl (90 kB)
Collecting sphinxcontrib-devhelp
Using cached sphinxcontrib_devhelp-1.0.2-py2.py3-none-any.whl (84 kB)
Collecting babel>=1.3
Using cached Babel-2.10.3-py3-none-any.whl (9.5 MB)
Collecting sphinxcontrib-serializinghtml>=1.1.5
Using cached sphinxcontrib_serializinghtml-1.1.5-py2.py3-none-any.whl (94 kB)
Collecting imagesize
Using cached imagesize-1.4.1-py2.py3-none-any.whl (8.8 kB)
Collecting docutils<0.20,>=0.14
Using cached docutils-0.19-py3-none-any.whl (570 kB)
Collecting sphinxcontrib-jsmath
Using cached sphinxcontrib_jsmath-1.0.1-py2.py3-none-any.whl (5.1 kB)
Collecting sphinxcontrib-htmlhelp>=2.0.0
Using cached sphinxcontrib_htmlhelp-2.0.0-py2.py3-none-any.whl (100 kB)
Collecting google-auth-oauthlib<0.5,>=0.4.1
Using cached google_auth_oauthlib-0.4.6-py2.py3-none-any.whl (18 kB)
Collecting protobuf>=3.9.2
Using cached protobuf-3.19.4-cp39-cp39-win_amd64.whl (895 kB)
Collecting markdown>=2.6.8
Using cached Markdown-3.4.1-py3-none-any.whl (93 kB)
Collecting tensorboard-plugin-wit>=1.6.0
Using cached tensorboard_plugin_wit-1.8.1-py3-none-any.whl (781 kB)
Collecting tensorboard-data-server<0.7.0,>=0.6.0
Using cached tensorboard_data_server-0.6.1-py3-none-any.whl (2.4 kB)
Collecting google-auth<3,>=1.6.3
Using cached google_auth-2.11.0-py2.py3-none-any.whl (167 kB)
Collecting Cython==0.29.28
Using cached Cython-0.29.28-py2.py3-none-any.whl (983 kB)
Collecting smart-open>=1.8.1
Using cached smart_open-6.1.0-py3-none-any.whl (58 kB)
Collecting entrypoints<1
Using cached entrypoints-0.4-py3-none-any.whl (5.3 kB)
Collecting querystring-parser<2
Using cached querystring_parser-1.2.4-py2.py3-none-any.whl (7.9 kB)
Collecting gitpython<4,>=2.1.0
Using cached GitPython-3.1.27-py3-none-any.whl (181 kB)
Collecting alembic<2
Using cached alembic-1.8.1-py3-none-any.whl (209 kB)
Collecting databricks-cli<1,>=0.8.7
Using cached databricks-cli-0.17.3.tar.gz (77 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
Collecting sqlalchemy<2,>=1.4.0
Using cached SQLAlchemy-1.4.41-cp39-cp39-win_amd64.whl (1.6 MB)
Collecting sqlparse<1,>=0.4.0
Using cached sqlparse-0.4.2-py3-none-any.whl (42 kB)
Collecting waitress<3
Using cached waitress-2.1.2-py3-none-any.whl (57 kB)
Collecting prometheus-flask-exporter<1
Using cached prometheus_flask_exporter-0.20.3-py3-none-any.whl (18 kB)
Collecting docker<6,>=4.0.0
Using cached docker-5.0.3-py2.py3-none-any.whl (146 kB)
Collecting regex>=2021.8.3
Using cached regex-2022.8.17-cp39-cp39-win_amd64.whl (263 kB)
Collecting argon2-cffi
Using cached argon2_cffi-21.3.0-py3-none-any.whl (14 kB)
Collecting terminado>=0.8.3
Using cached terminado-0.15.0-py3-none-any.whl (16 kB)
Collecting prometheus-client
Using cached prometheus_client-0.14.1-py3-none-any.whl (59 kB)
Collecting Send2Trash>=1.8.0
Using cached Send2Trash-1.8.0-py3-none-any.whl (18 kB)
Collecting numexpr
Using cached numexpr-2.8.3-cp39-cp39-win_amd64.whl (92 kB)
Collecting pyLDAvis
Using cached pyLDAvis-3.3.0.tar.gz (1.7 MB)
Installing build dependencies: started
Installing build dependencies: finished with status 'done'
Getting requirements to build wheel: started
Getting requirements to build wheel: finished with status 'done'
Installing backend dependencies: started
Installing backend dependencies: finished with status 'done'
Preparing metadata (pyproject.toml): started
Preparing metadata (pyproject.toml): finished with status 'done'
Using cached pyLDAvis-3.2.2.tar.gz (1.7 MB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
Collecting future
Using cached future-0.18.2.tar.gz (829 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
Collecting funcy
Using cached funcy-1.17-py2.py3-none-any.whl (33 kB)
Collecting numba>=0.51
Using cached numba-0.56.2-cp39-cp39-win_amd64.whl (2.5 MB)
Collecting catalogue<2.1.0,>=2.0.6
Using cached catalogue-2.0.8-py3-none-any.whl (17 kB)
Collecting pathy>=0.3.5
Using cached pathy-0.6.2-py3-none-any.whl (42 kB)
Collecting srsly<3.0.0,>=2.4.3
Using cached srsly-2.4.4-cp39-cp39-win_amd64.whl (450 kB)
Collecting langcodes<4.0.0,>=3.2.0
Using cached langcodes-3.3.0-py3-none-any.whl (181 kB)
Collecting preshed<3.1.0,>=3.0.2
Using cached preshed-3.0.7-cp39-cp39-win_amd64.whl (96 kB)
Collecting wasabi<1.1.0,>=0.9.1
Using cached wasabi-0.10.1-py3-none-any.whl (26 kB)
Collecting spacy-legacy<3.1.0,>=3.0.9
Using cached spacy_legacy-3.0.10-py2.py3-none-any.whl (21 kB)
Collecting cymem<2.1.0,>=2.0.2
Using cached cymem-2.0.6-cp39-cp39-win_amd64.whl (36 kB)
Collecting spacy-loggers<2.0.0,>=1.0.0
Using cached spacy_loggers-1.0.3-py3-none-any.whl (9.3 kB)
Collecting murmurhash<1.1.0,>=0.28.0
Using cached murmurhash-1.0.8-cp39-cp39-win_amd64.whl (18 kB)
Collecting typer<0.5.0,>=0.3.0
Using cached typer-0.4.2-py3-none-any.whl (27 kB)
Collecting thinc<8.2.0,>=8.1.0
Using cached thinc-8.1.0-cp39-cp39-win_amd64.whl (1.3 MB)
Collecting pynndescent>=0.5
Using cached pynndescent-0.5.7.tar.gz (1.1 MB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
Collecting Mako
Using cached Mako-1.2.2-py3-none-any.whl (78 kB)
Collecting sniffio>=1.1
Using cached sniffio-1.3.0-py3-none-any.whl (10 kB)
Collecting lazy-object-proxy>=1.4.0
Using cached lazy_object_proxy-1.7.1-cp39-cp39-win_amd64.whl (22 kB)
Collecting pathspec>=0.9.0
Using cached pathspec-0.10.1-py3-none-any.whl (27 kB)
Collecting black>=22.3.0
Using cached black-22.6.0-cp39-cp39-win_amd64.whl (1.2 MB)
Using cached black-22.3.0-cp39-cp39-win_amd64.whl (1.1 MB)
INFO: pip is looking at multiple versions of binaryornot to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of bcrypt to determine which version is compatible with other requirements. This could take a while.
Collecting bcrypt>=3.1.3
Using cached bcrypt-3.2.2-cp36-abi3-win_amd64.whl (29 kB)
INFO: pip is looking at multiple versions of babel to determine which version is compatible with other requirements. This could take a while.
Collecting babel>=1.3
Using cached Babel-2.10.2-py3-none-any.whl (9.5 MB)
INFO: pip is looking at multiple versions of autopep8 to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of attrs to determine which version is compatible with other requirements. This could take a while.
Collecting attrs>=17.4.0
Using cached attrs-21.4.0-py2.py3-none-any.whl (60 kB)
INFO: pip is looking at multiple versions of astroid to determine which version is compatible with other requirements. This could take a while.
Collecting astroid<2.8,>=2.7.2
Using cached astroid-2.7.2-py3-none-any.whl (238 kB)
INFO: pip is looking at multiple versions of anyio to determine which version is compatible with other requirements. This could take a while.
Collecting anyio<4,>=3.0.0
Using cached anyio-3.6.0-py3-none-any.whl (80 kB)
INFO: pip is looking at multiple versions of alembic to determine which version is compatible with other requirements. This could take a while.
Collecting alembic<2
Using cached alembic-1.8.0-py3-none-any.whl (209 kB)
INFO: pip is looking at multiple versions of alabaster to determine which version is compatible with other requirements. This could take a while.
Collecting alabaster<0.8,>=0.7
Using cached alabaster-0.7.11-py2.py3-none-any.whl (14 kB)
INFO: pip is looking at multiple versions of wordcloud to determine which version is compatible with other requirements. This could take a while.
Collecting wordcloud
Using cached wordcloud-1.8.1.tar.gz (220 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
INFO: pip is looking at multiple versions of umap-learn to determine which version is compatible with other requirements. This could take a while.
Collecting umap-learn
Using cached umap-learn-0.5.2.tar.gz (86 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
INFO: pip is looking at multiple versions of textblob to determine which version is compatible with other requirements. This could take a while.
Collecting textblob
Using cached textblob-0.17.0-py2.py3-none-any.whl (636 kB)
INFO: pip is looking at multiple versions of spacy to determine which version is compatible with other requirements. This could take a while.
Collecting spacy
Using cached spacy-3.4.0-cp39-cp39-win_amd64.whl (11.8 MB)
INFO: pip is looking at multiple versions of scikit-plot to determine which version is compatible with other requirements. This could take a while.
Collecting scikit-plot
Using cached scikit_plot-0.3.6-py3-none-any.whl (33 kB)
INFO: pip is looking at multiple versions of pyod to determine which version is compatible with other requirements. This could take a while.
Collecting pyod
Using cached pyod-1.0.3.tar.gz (125 kB)
Preparing metadata (setup.py): started
Preparing metadata (setup.py): finished with status 'done'
INFO: pip is looking at multiple versions of pyldavis to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of notebook to determine which version is compatible with other requirements. This could take a while.
Collecting notebook
Using cached notebook-6.4.11-py3-none-any.whl (9.9 MB)
INFO: pip is looking at multiple versions of nltk to determine which version is compatible with other requirements. This could take a while.
Collecting nltk
Using cached nltk-3.6.7-py3-none-any.whl (1.5 MB)
INFO: pip is looking at multiple versions of mlflow to determine which version is compatible with other requirements. This could take a while.
Collecting mlflow
Using cached mlflow-1.27.0-py3-none-any.whl (17.9 MB)
INFO: pip is looking at multiple versions of jupyter-console to determine which version is compatible with other requirements. This could take a while.
Collecting jupyter-console
Using cached jupyter_console-6.4.3-py3-none-any.whl (22 kB)
INFO: pip is looking at multiple versions of graphviz to determine which version is compatible with other requirements. This could take a while.
Collecting graphviz
Using cached graphviz-0.20-py3-none-any.whl (46 kB)
INFO: pip is looking at multiple versions of cython to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of gensim to determine which version is compatible with other requirements. This could take a while.
Collecting gensim
Using cached gensim-4.1.2-cp39-cp39-win_amd64.whl (24.0 MB)
INFO: pip is looking at multiple versions of yellowbrick to determine which version is compatible with other requirements. This could take a while.
Collecting yellowbrick>=1.0.1
Using cached yellowbrick-1.4-py3-none-any.whl (274 kB)
INFO: pip is looking at multiple versions of wrapt to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of wheel to determine which version is compatible with other requirements. This could take a while.
Collecting wheel~=0.35
Using cached wheel-0.37.1-py2.py3-none-any.whl (35 kB)
INFO: pip is looking at multiple versions of werkzeug to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of watchdog to determine which version is compatible with other requirements. This could take a while.
Collecting watchdog>=0.10.3
Using cached watchdog-2.1.8-py3-none-win_amd64.whl (77 kB)
INFO: pip is looking at multiple versions of tornado to determine which version is compatible with other requirements. This could take a while.
Collecting tornado>=5.1
Using cached tornado-6.1-cp39-cp39-win_amd64.whl (422 kB)
INFO: pip is looking at multiple versions of three-merge to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of threadpoolctl to determine which version is compatible with other requirements. This could take a while.
Collecting threadpoolctl>=2.0.0
Using cached threadpoolctl-3.0.0-py3-none-any.whl (14 kB)
INFO: pip is looking at multiple versions of textdistance to determine which version is compatible with other requirements. This could take a while.
Collecting textdistance>=4.2.0
Using cached textdistance-4.3.0-py3-none-any.whl (29 kB)
INFO: pip is looking at multiple versions of termcolor to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of tensorflow-estimator to determine which version is compatible with other requirements. This could take a while.
Collecting tensorflow-estimator~=2.6
Using cached tensorflow_estimator-2.9.0-py2.py3-none-any.whl (438 kB)
INFO: pip is looking at multiple versions of protobuf to determine which version is compatible with other requirements. This could take a while.
Collecting protobuf>=3.9.2
Using cached protobuf-3.19.3-cp39-cp39-win_amd64.whl (895 kB)
INFO: pip is looking at multiple versions of tensorboard to determine which version is compatible with other requirements. This could take a while.
Collecting tensorboard~=2.6
Using cached tensorboard-2.9.1-py3-none-any.whl (5.8 MB)
INFO: pip is looking at multiple versions of spyder-kernels to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of sphinx to determine which version is compatible with other requirements. This could take a while.
Collecting sphinx>=0.6.6
Using cached Sphinx-5.1.0-py3-none-any.whl (3.2 MB)
INFO: pip is looking at multiple versions of six to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of rtree to determine which version is compatible with other requirements. This could take a while.
Collecting rtree>=0.9.7
Using cached Rtree-0.9.7-cp39-cp39-win_amd64.whl (424 kB)
INFO: pip is looking at multiple versions of requests to determine which version is compatible with other requirements. This could take a while.
Collecting requests>=1.1.0
Using cached requests-2.28.0-py3-none-any.whl (62 kB)
INFO: pip is looking at multiple versions of qtpy to determine which version is compatible with other requirements. This could take a while.
Collecting qtpy>=2.1.0
Using cached QtPy-2.1.0-py3-none-any.whl (68 kB)
INFO: pip is looking at multiple versions of qtconsole to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of qtawesome to determine which version is compatible with other requirements. This could take a while.
Collecting qtawesome>=1.0.2
Using cached QtAwesome-1.1.0-py3-none-any.whl (2.3 MB)
INFO: pip is looking at multiple versions of qstylizer to determine which version is compatible with other requirements. This could take a while.
Collecting qstylizer>=0.1.10
Using cached qstylizer-0.2.1-py2.py3-none-any.whl (15 kB)
INFO: pip is looking at multiple versions of qdarkstyle to determine which version is compatible with other requirements. This could take a while.
Collecting qdarkstyle<3.1.0,>=3.0.2
Using cached QDarkStyle-3.0.2-py2.py3-none-any.whl (453 kB)
INFO: pip is looking at multiple versions of pyzmq to determine which version is compatible with other requirements. This could take a while.
Collecting pyzmq>=22.1.0
Using cached pyzmq-23.2.0-cp39-cp39-win_amd64.whl (992 kB)
INFO: pip is looking at multiple versions of pyyaml to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of pytz to determine which version is compatible with other requirements. This could take a while.
Collecting pytz>=2020.1
Using cached pytz-2022.2-py2.py3-none-any.whl (504 kB)
INFO: pip is looking at multiple versions of python-lsp-server[all] to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple versions of python-lsp-black to determine which version is compatible with other requirements. This could take a while.
Collecting python-lsp-black>=1.2.0
Using cached python_lsp_black-1.2.0-py3-none-any.whl (6.2 kB)
Collecting black>=22.1.0
Using cached black-22.1.0-cp39-cp39-win_amd64.whl (1.1 MB)
INFO: pip is looking at multiple versions of python-dateutil to determine which version is compatible with other requirements. This could take a while.
Collecting python-dateutil>=2.1
Using cached python_dateutil-2.8.1-py2.py3-none-any.whl (227 kB)
INFO: pip is looking at multiple versions of pyqtwebengine to determine which version is compatible with other requirements. This could take a while.
Collecting pyqtwebengine<5.16
Using cached PyQtWebEngine-5.15.5-cp36-abi3-win_amd64.whl (181 kB)
INFO: pip is looking at multiple versions of python-lsp-black to determine which version is compatible with other requirements. This could take a while.
Using cached PyQtWebEngine-5.15.4-cp36.cp37.cp38.cp39-none-win_amd64.whl (182 kB)
Using cached PyQtWebEngine-5.15.3-cp36.cp37.cp38.cp39-none-win_amd64.whl (182 kB)
Collecting PyQtWebEngine-Qt>=5.15
Using cached PyQtWebEngine_Qt-5.15.2-py3-none-win_amd64.whl (60.0 MB)
INFO: This is taking longer than usual. You might need to provide the dependency resolver with stricter constraints to reduce runtime. See https://pip.pypa.io/warnings/backtracking for guidance. If you want to abort this run, press Ctrl + C.
INFO: pip is looking at multiple versions of python-dateutil to determine which version is compatible with other requirements. This could take a while.
Collecting pyqtwebengine<5.16
See error below:
Collecting PyQtWebEngine-Qt>=5.15
Using cached PyQtWebEngine_Qt-5.15.2-py3-none-win_amd64.whl (60.0 MB)
INFO: This is taking longer than usual. You might need to provide the dependency resolver with stricter constraints to reduce runtime. See https://pip.pypa.io/warnings/backtracking for guidance. If you want to abort this run, press Ctrl + C.
INFO: pip is looking at multiple versions of python-dateutil to determine which version is compatible with other requirements. This could take a while.
Collecting pyqtwebengine<5.16
Using cached PyQtWebEngine-5.15.2-5.15.2-cp35.cp36.cp37.cp38.cp39-none-win_amd64.whl (60.2 MB)
Using cached PyQtWebEngine-5.15.1-5.15.1-cp35.cp36.cp37.cp38.cp39-none-win_amd64.whl (58.2 MB)
Using cached PyQtWebEngine-5.15.0.tar.gz (48 kB)
Installing build dependencies: started
Installing build dependencies: finished with status 'done'
Getting requirements to build wheel: started
Getting requirements to build wheel: finished with status 'done'
Preparing metadata (pyproject.toml): started
Preparing metadata (pyproject.toml): finished with status 'error'
error: subprocess-exited-with-error
Preparing metadata (pyproject.toml) did not run successfully.
exit code: 1
[5481 lines of output]
Querying qmake about your Qt installation...
These bindings will be built: QtWebEngineCore, QtWebEngine, QtWebEngineWidgets.
Generating the QtWebEngineCore bindings...
Generating the QtWebEngine bindings...
Generating the QtWebEngineWidgets bindings...
Generating the .pro file for the QtWebEngineCore module...
Generating the .pro file for the QtWebEngine module...
Generating the .pro file for the QtWebEngineWidgets module...
Generating the top-level .pro file...
Generating the Makefiles...
_in_process.py: 'C:\Users\user\anaconda3\envs\datascienv\Library\bin\qmake.exe -recursive PyQtWebEngine.pro' failed returning 3
Traceback (most recent call last):
File "C:\Users\user\anaconda3\envs\datascienv\lib\shutil.py", line 631, in _rmtree_unsafe
os.rmdir(path)
PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'C:\\Users\\USER~1\\AppData\\Local\\Temp\\tmpvigdas1o'
I did install with Administrator privileges and have Microsoft Visual C++ 14.0+ installed. I also installed the qtbase5-dev from https://wiki.qt.io/Building_Qt_5_from_Git#Getting_the_source_code according to their directions.
See full error log below.
datascienv_error_log.txt


 2 May 26, 2022
2 May 26, 2022

 1 Feb 11, 2022
1 Feb 11, 2022
 98 Dec 22, 2022
98 Dec 22, 2022

 2 Jan 20, 2022
2 Jan 20, 2022
 2 Jun 27, 2022
2 Jun 27, 2022

 3.7k Jan 3, 2023
3.7k Jan 3, 2023

 898 Jan 9, 2023
898 Jan 9, 2023
 2 Dec 19, 2021
2 Dec 19, 2021

 97 Dec 8, 2022
97 Dec 8, 2022



 450 Dec 30, 2022
450 Dec 30, 2022
 11 Dec 13, 2022
11 Dec 13, 2022
 50 Jan 05, 2023
50 Jan 05, 2023
 1 Oct 03, 2021
1 Oct 03, 2021
 53 Dec 08, 2022
53 Dec 08, 2022
 186 Dec 29, 2022
186 Dec 29, 2022
 1 Feb 15, 2022
1 Feb 15, 2022
 19 Nov 24, 2022
19 Nov 24, 2022
 102 Nov 16, 2022
102 Nov 16, 2022
 2 Jul 22, 2022
2 Jul 22, 2022
 17 Jul 09, 2022
17 Jul 09, 2022
 102 Nov 10, 2022
102 Nov 10, 2022
 1 Oct 20, 2021
1 Oct 20, 2021
 1 Dec 09, 2021
1 Dec 09, 2021
 65 Dec 09, 2022
65 Dec 09, 2022
 711 Dec 26, 2022
711 Dec 26, 2022
 12 May 26, 2022
12 May 26, 2022
 1 Dec 16, 2021
1 Dec 16, 2021
 1 Nov 17, 2021
1 Nov 17, 2021