linear-tree
A python library to build Model Trees with Linear Models at the leaves.
Overview
Linear Model Trees combine the learning ability of Decision Tree with the predictive and explicative power of Linear Models. Like in tree-based algorithms, the data are split according to simple decision rules. The goodness of slits is evaluated in gain terms fitting Linear Models in the nodes. This implies that the models in the leaves are linear instead of constant approximations like in classical Decision Trees.
linear-tree is developed to be fully integrable with scikit-learn. LinearTreeRegressor and LinearTreeClassifier are provided as scikit-learn BaseEstimator. They are wrappers that build a decision tree on the data fitting a linear estimator from sklearn.linear_model. All the models available in sklearn.linear_model can be used as linear estimators.
Installation
pip install linear-tree
The module depends on NumPy, SciPy and Scikit-Learn (>=0.23.0). Python 3.6 or above is supported.
Media
- Linear Tree: the perfect mix of Linear Model and Decision Tree
- Model Tree: handle Data Shifts mixing Linear Model and Decision Tree
- Explainable AI with Linear Trees
Usage
Regression
from sklearn.linear_model import LinearRegression
from lineartree import LinearTreeRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=4,
n_informative=2, n_targets=1,
random_state=0, shuffle=False)
regr = LinearTreeRegressor(base_estimator=LinearRegression())
regr.fit(X, y)
Classification
from sklearn.linear_model import RidgeClassifier
from lineartree import LinearTreeClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=100, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
clf = LinearTreeClassifier(base_estimator=RidgeClassifier())
clf.fit(X, y)
More examples in the notebooks folder.
Check the API Reference to see the parameter configurations and the available methods.
Examples
Show the model tree structure:
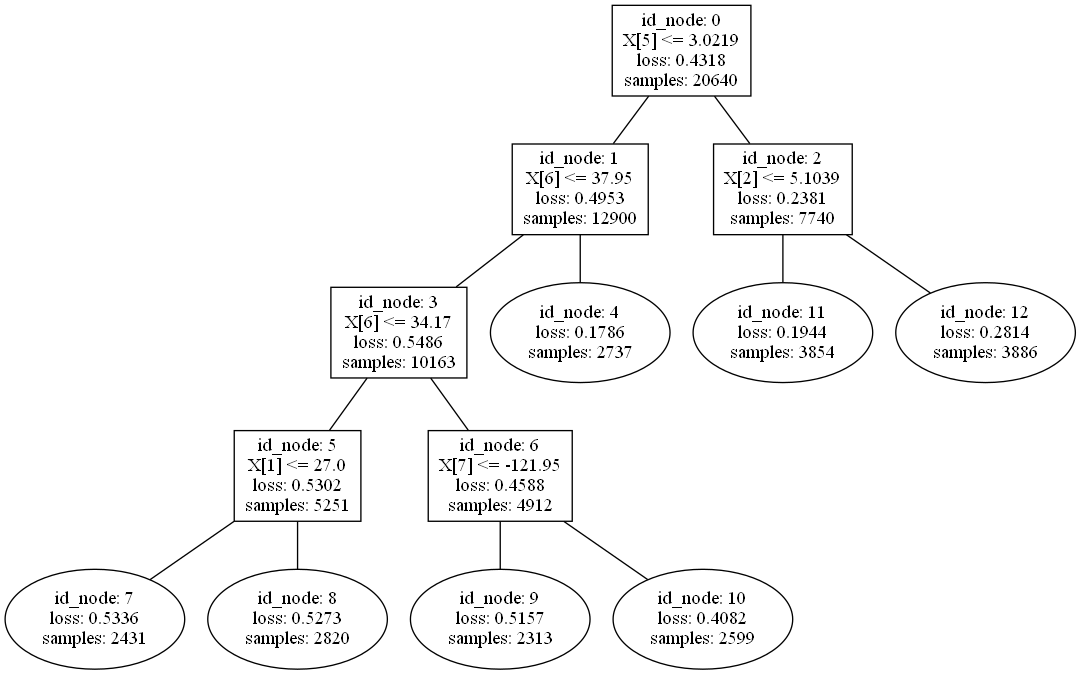
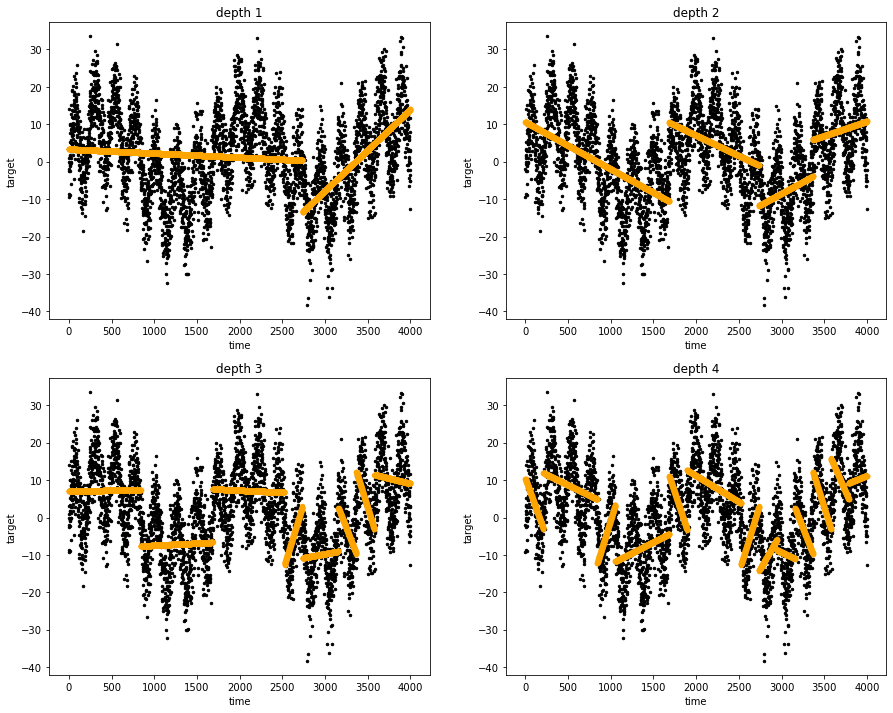
Linear Tree Regressor at work:
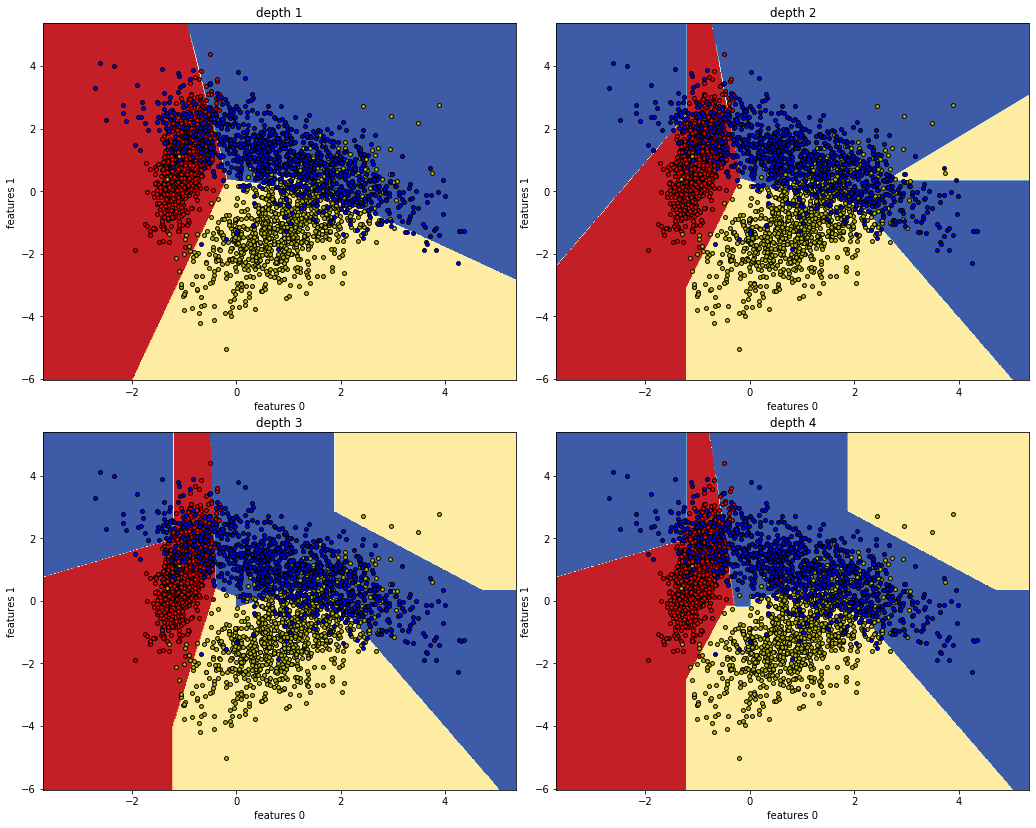
Linear Tree Classifier at work:
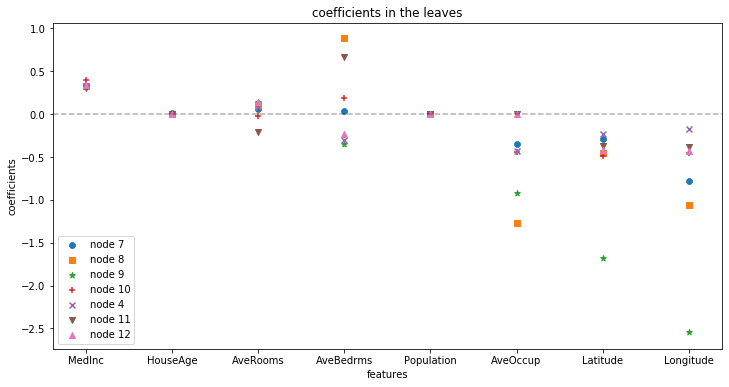
Extract and examine coefficients at the leaves:













 378 Dec 30, 2022
378 Dec 30, 2022
 146 Dec 25, 2022
146 Dec 25, 2022
 2.3k Jan 09, 2023
2.3k Jan 09, 2023
 102 Dec 21, 2022
102 Dec 21, 2022
 425 Dec 22, 2022
425 Dec 22, 2022
 41 May 18, 2022
41 May 18, 2022
 10 Oct 10, 2022
10 Oct 10, 2022
 46 Nov 20, 2022
46 Nov 20, 2022
 149 Jan 07, 2023
149 Jan 07, 2023
 100 Jan 01, 2023
100 Jan 01, 2023
 182 Dec 27, 2022
182 Dec 27, 2022
 63 Dec 31, 2022
63 Dec 31, 2022
 0 Oct 06, 2021
0 Oct 06, 2021
 83 Jan 07, 2023
83 Jan 07, 2023
 1.9k Dec 15, 2022
1.9k Dec 15, 2022
 167 Jan 08, 2023
167 Jan 08, 2023
 1 Nov 30, 2021
1 Nov 30, 2021
 0 Nov 17, 2022
0 Nov 17, 2022
 232 Dec 31, 2022
232 Dec 31, 2022
 63 Dec 05, 2022
63 Dec 05, 2022