A brief explanation
This script provides a quick way to setup a Time-of-day (Tod) Access Control List (ACL) for a Hostapd Wifi Access Point.
It uses the hostapd-cli's whitelist to only allow certain MAC addresses to join the AP.
Setup
The following
-
Install python 3 or above & hostapd
-
Make a Wifi AP with hostapd, enable hostapd_cli and MAC whitelist by adding to the config:
macaddr_acl=0 accept_mac_file=/etc/hostapd/hostapd.accept ctrl_interface=/var/run/hostapd ctrl_interface_group=0 -
Place the following files inside /etc/hostapd/:
- hostapd.accept
- mac-time-of-day-acces.py
-
Configure crontab (
$ sudo crontab -u root -e) with the following rule to execute the script every minute:* * * * * python /etc/hostapd/mac-time-of-day-access.py -
Set your time of day MAC based filters with the file mac-time-filter.json
mac-time-filter.json
Format
{
"mac": [
["start (H:M:S)", "end (H:M:S)"],
…
],
…
}
Example
{
"48:01:C5:76:14:53": [
["10:00:00","12:00:00"],
["16:00:00","21:30:00"]
]
}
 49 Dec 26, 2022
49 Dec 26, 2022
 14 Aug 24, 2022
14 Aug 24, 2022
 189 Jan 2, 2023
189 Jan 2, 2023

 540 Dec 30, 2022
540 Dec 30, 2022

 213 Dec 22, 2022
213 Dec 22, 2022
 43 Dec 28, 2022
43 Dec 28, 2022
 78 Dec 12, 2022
78 Dec 12, 2022
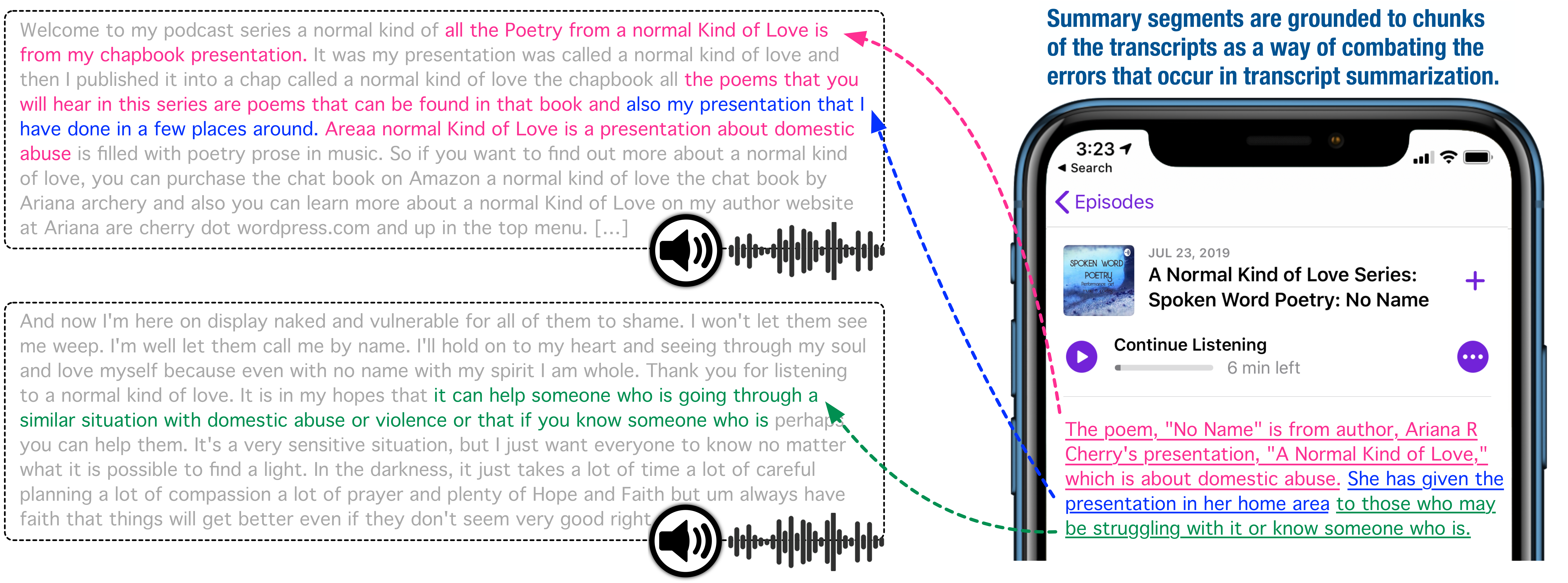
 10 Jul 1, 2022
10 Jul 1, 2022
 14 Jan 3, 2023
14 Jan 3, 2023

 247 Dec 26, 2022
247 Dec 26, 2022
 38 Oct 17, 2022
38 Oct 17, 2022
 75 Jul 15, 2022
75 Jul 15, 2022
 394 Dec 17, 2022
394 Dec 17, 2022
 4 Jul 01, 2022
4 Jul 01, 2022
 31 Oct 30, 2022
31 Oct 30, 2022
 6.1k Dec 29, 2022
6.1k Dec 29, 2022
 255 Dec 26, 2022
255 Dec 26, 2022
 24 Sep 11, 2022
24 Sep 11, 2022
 5 Aug 15, 2022
5 Aug 15, 2022
 2 Dec 20, 2021
2 Dec 20, 2021
 2 Oct 02, 2022
2 Oct 02, 2022
 112 Dec 22, 2022
112 Dec 22, 2022
 767 Jan 09, 2023
767 Jan 09, 2023
 1 Jan 27, 2022
1 Jan 27, 2022
 431 Dec 19, 2022
431 Dec 19, 2022
 237 Nov 04, 2022
237 Nov 04, 2022
 2 Mar 09, 2022
2 Mar 09, 2022
 0 Feb 08, 2022
0 Feb 08, 2022