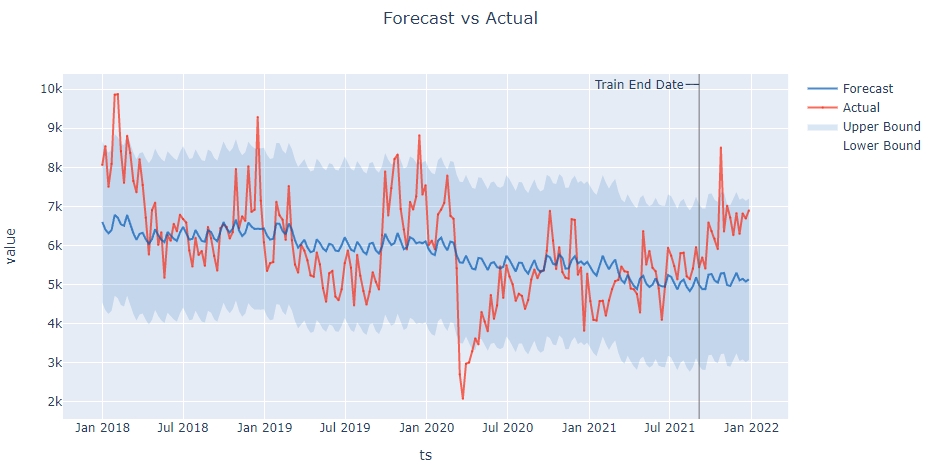
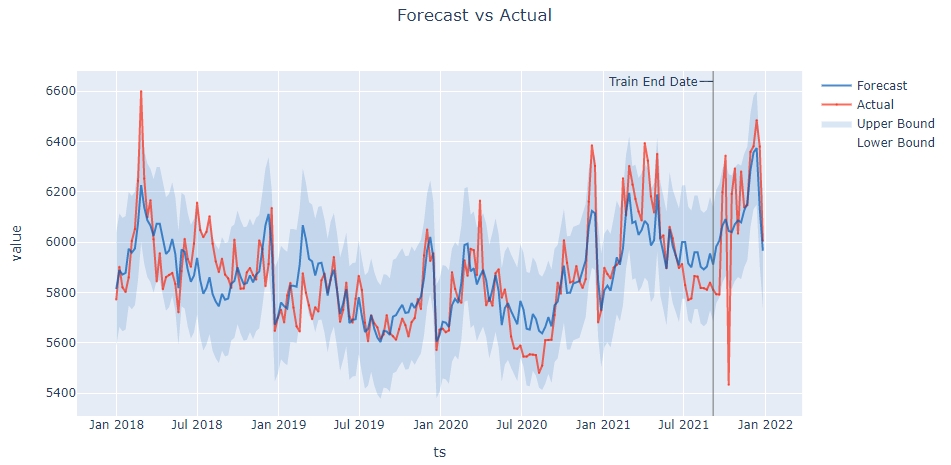
I have some time series forecasts of weekly data where forecasts are too smooth or not really pronounced (not sure how to describe it). Another time series however, for the same dates, same general value range, same model parameters, shows "correct" variability. Both datasets show the same warnings when run (generally about daily event timestamps due to weekly data and a warning that data is highly fragmented)
In another dataset (I have not currently access to), removing the last entry from the time-series fixed the variability. This does however not work for the dataset1 below.
Is this a bug or intended behaviour? If this is intended, which parameters would I have to tweak to mitigate this? Thx for your help
Dataset1: relatively smooth forcast (False)
Dataset2: correct variability forecast (True)
I am using the following settings for the model (Greykite v.0.4.0):
- ForecastConfig(model_template=ModelTemplateEnum.SILVERKITE.name, forecast_horizon=16, coverage=0.95)
- metadata = MetadataParam(anomaly_info=None, date_format=None, freq='W', time_col='date', train_end_date=None, value_col='value')
- model_components =
{ 'autoregression': None,
'changepoints': {
'changepoints_dict': {
'method': 'auto',
'yearly_seasonality_order': 15,
'regularization_strength': 0.5,
'resample_freq': '7D',
'potential_changepoint_n': 25,
'no_changepoint_proportion_from_end': 0.2
}
},
'custom': {
'fit_algorithm_dict': {
'fit_algorithm': 'ridge'
}
},
'events': {
'holidays_to_model_separately': 'ALL_HOLIDAYS_IN_COUNTRIES',
'holiday_lookup_countries': ['DE'],
'holiday_pre_num_days': 4,
'holiday_post_num_days': 1,
'holiday_pre_post_num_dict': None,
'daily_event_df_dict': {
'Mothersday': date event_name
0 2017-05-14 Mothersday
1 2018-05-13 Mothersday
2 2019-05-12 Mothersday
3 2020-05-10 Mothersday
4 2021-05-09 Mothersday
5 2022-05-08 Mothersday
6 2023-05-14 Mothersday
7 2024-05-12 Mothersday
8 2025-05-11 Mothersday,
'Black Friday': date event_name
0 2017-11-24 Black Friday
1 2018-11-23 Black Friday
2 2019-11-29 Black Friday
3 2020-11-27 Black Friday
4 2021-11-26 Black Friday
5 2022-11-25 Black Friday
6 2023-11-24 Black Friday
7 2024-11-29 Black Friday
8 2025-11-29 Black Friday
}
},
'growth': None,
'hyperparameter_override': None,
'regressors': None,
'lagged_regressors': None,
'seasonality': None,
'uncertainty': None
}
DataSet1 (False):
df1 = pd.DataFrame.from_dict({'date':{0:'2017-12-31',1:'2018-01-07',2:'2018-01-14',3:'2018-01-21',4:'2018-01-28',5:'2018-02-04',6:'2018-02-11',7:'2018-02-18',8:'2018-02-25',9:'2018-03-04',10:'2018-03-11',11:'2018-03-18',12:'2018-03-25',13:'2018-04-01',14:'2018-04-08',15:'2018-04-15',16:'2018-04-22',17:'2018-04-29',18:'2018-05-06',19:'2018-05-13',20:'2018-05-20',21:'2018-05-27',22:'2018-06-03',23:'2018-06-10',24:'2018-06-17',25:'2018-06-24',26:'2018-07-01',27:'2018-07-08',28:'2018-07-15',29:'2018-07-22',30:'2018-07-29',31:'2018-08-05',32:'2018-08-12',33:'2018-08-19',34:'2018-08-26',35:'2018-09-02',36:'2018-09-09',37:'2018-09-16',38:'2018-09-23',39:'2018-09-30',40:'2018-10-07',41:'2018-10-14',42:'2018-10-21',43:'2018-10-28',44:'2018-11-04',45:'2018-11-11',46:'2018-11-18',47:'2018-11-25',48:'2018-12-02',49:'2018-12-09',50:'2018-12-16',51:'2018-12-23',52:'2018-12-30',53:'2019-01-06',54:'2019-01-13',55:'2019-01-20',56:'2019-01-27',57:'2019-02-03',58:'2019-02-10',59:'2019-02-17',60:'2019-02-24',61:'2019-03-03',62:'2019-03-10',63:'2019-03-17',64:'2019-03-24',65:'2019-03-31',66:'2019-04-07',67:'2019-04-14',68:'2019-04-21',69:'2019-04-28',70:'2019-05-05',71:'2019-05-12',72:'2019-05-19',73:'2019-05-26',74:'2019-06-02',75:'2019-06-09',76:'2019-06-16',77:'2019-06-23',78:'2019-06-30',79:'2019-07-07',80:'2019-07-14',81:'2019-07-21',82:'2019-07-28',83:'2019-08-04',84:'2019-08-11',85:'2019-08-18',86:'2019-08-25',87:'2019-09-01',88:'2019-09-08',89:'2019-09-15',90:'2019-09-22',91:'2019-09-29',92:'2019-10-06',93:'2019-10-13',94:'2019-10-20',95:'2019-10-27',96:'2019-11-03',97:'2019-11-10',98:'2019-11-17',99:'2019-11-24',100:'2019-12-01',101:'2019-12-08',102:'2019-12-15',103:'2019-12-22',104:'2019-12-29',105:'2020-01-05',106:'2020-01-12',107:'2020-01-19',108:'2020-01-26',109:'2020-02-02',110:'2020-02-09',111:'2020-02-16',112:'2020-02-23',113:'2020-03-01',114:'2020-03-08',115:'2020-03-15',116:'2020-03-22',117:'2020-03-29',118:'2020-04-05',119:'2020-04-12',120:'2020-04-19',121:'2020-04-26',122:'2020-05-03',123:'2020-05-10',124:'2020-05-17',125:'2020-05-24',126:'2020-05-31',127:'2020-06-07',128:'2020-06-14',129:'2020-06-21',130:'2020-06-28',131:'2020-07-05',132:'2020-07-12',133:'2020-07-19',134:'2020-07-26',135:'2020-08-02',136:'2020-08-09',137:'2020-08-16',138:'2020-08-23',139:'2020-08-30',140:'2020-09-06',141:'2020-09-13',142:'2020-09-20',143:'2020-09-27',144:'2020-10-04',145:'2020-10-11',146:'2020-10-18',147:'2020-10-25',148:'2020-11-01',149:'2020-11-08',150:'2020-11-15',151:'2020-11-22',152:'2020-11-29',153:'2020-12-06',154:'2020-12-13',155:'2020-12-20',156:'2020-12-27',157:'2021-01-03',158:'2021-01-10',159:'2021-01-17',160:'2021-01-24',161:'2021-01-31',162:'2021-02-07',163:'2021-02-14',164:'2021-02-21',165:'2021-02-28',166:'2021-03-07',167:'2021-03-14',168:'2021-03-21',169:'2021-03-28',170:'2021-04-04',171:'2021-04-11',172:'2021-04-18',173:'2021-04-25',174:'2021-05-02',175:'2021-05-09',176:'2021-05-16',177:'2021-05-23',178:'2021-05-30',179:'2021-06-06',180:'2021-06-13',181:'2021-06-20',182:'2021-06-27',183:'2021-07-04',184:'2021-07-11',185:'2021-07-18',186:'2021-07-25',187:'2021-08-01',188:'2021-08-08',189:'2021-08-15',190:'2021-08-22',191:'2021-08-29',192:'2021-09-05',193:'2021-09-12',194:'2021-09-19',195:'2021-09-26',196:'2021-10-03',197:'2021-10-10',198:'2021-10-17',199:'2021-10-24',200:'2021-10-31',201:'2021-11-07',202:'2021-11-14',203:'2021-11-21',204:'2021-11-28',205:'2021-12-05',206:'2021-12-12',207:'2021-12-19',208:'2021-12-26'},'value':{0:8057,1:8543,2:7500,3:8090,4:9858,5:9869,6:8414,7:7599,8:8805,9:8367,10:7650,11:7360,12:8205,13:7547,14:6710,15:5767,16:6902,17:7093,18:6013,19:6337,20:5172,21:6260,22:6120,23:6551,24:6363,25:6785,26:6675,27:6586,28:5872,29:5460,30:6195,31:5756,32:5856,33:5477,34:6472,35:6183,36:5732,37:5356,38:6440,39:6531,40:6473,41:6177,42:6343,43:7956,44:6439,45:6745,46:6628,47:8026,48:6859,49:6915,50:9287,51:7145,52:6082,53:5345,54:5546,55:5574,56:7117,57:6770,58:6660,59:6140,60:7521,61:6136,62:5511,63:5304,64:6010,65:5868,66:5615,67:5232,68:5202,69:5820,70:5514,71:4909,72:4558,73:5287,74:5342,75:4692,76:4599,77:4877,78:5545,79:5871,80:5430,81:4465,82:5759,83:5225,84:4832,85:4486,86:4818,87:5314,88:5070,89:4873,90:6263,91:7893,92:6766,93:7463,94:8210,95:8325,96:6934,97:6408,98:5899,99:7113,100:6919,101:7253,102:8818,103:7302,104:7541,105:6010,106:6122,107:5899,108:6794,109:6915,110:7089,111:7788,112:6756,113:6683,114:5414,115:2699,116:2075,117:2972,118:3004,119:3290,120:3620,121:3467,122:4297,123:4053,124:3803,125:4732,126:4120,127:4465,128:5465,129:4656,130:5495,131:5204,132:5005,133:4581,134:4761,135:4708,136:4375,137:4603,138:5127,139:5383,140:5162,141:5345,142:5358,143:5867,144:6885,145:6122,146:5395,147:5954,148:5318,149:5175,150:5152,151:6669,152:6654,153:5248,154:5436,155:3814,156:5276,157:4573,158:4096,159:4079,160:4574,161:4583,162:4201,163:4592,164:4880,165:5087,166:5116,167:5461,168:5337,169:5321,170:4897,171:4876,172:4756,173:4283,174:6367,175:5509,176:5856,177:5429,178:5338,179:4899,180:4094,181:4936,182:5940,183:5737,184:5471,185:5131,186:5799,187:5813,188:5209,189:5141,190:5408,191:5957,192:5442,193:5692,194:5408,195:6587,196:6365,197:6173,198:5907,199:8504,200:6358,201:7015,202:6714,203:6263,204:6826,205:6296,206:6818,207:6688,208:6895}})
Dataset2 (True):
df2 = pd.DataFrame.from_dict({'date':{0:'2017-12-31',1:'2018-01-07',2:'2018-01-14',3:'2018-01-21',4:'2018-01-28',5:'2018-02-04',6:'2018-02-11',7:'2018-02-18',8:'2018-02-25',9:'2018-03-04',10:'2018-03-11',11:'2018-03-18',12:'2018-03-25',13:'2018-04-01',14:'2018-04-08',15:'2018-04-15',16:'2018-04-22',17:'2018-04-29',18:'2018-05-06',19:'2018-05-13',20:'2018-05-20',21:'2018-05-27',22:'2018-06-03',23:'2018-06-10',24:'2018-06-17',25:'2018-06-24',26:'2018-07-01',27:'2018-07-08',28:'2018-07-15',29:'2018-07-22',30:'2018-07-29',31:'2018-08-05',32:'2018-08-12',33:'2018-08-19',34:'2018-08-26',35:'2018-09-02',36:'2018-09-09',37:'2018-09-16',38:'2018-09-23',39:'2018-09-30',40:'2018-10-07',41:'2018-10-14',42:'2018-10-21',43:'2018-10-28',44:'2018-11-04',45:'2018-11-11',46:'2018-11-18',47:'2018-11-25',48:'2018-12-02',49:'2018-12-09',50:'2018-12-16',51:'2018-12-23',52:'2018-12-30',53:'2019-01-06',54:'2019-01-13',55:'2019-01-20',56:'2019-01-27',57:'2019-02-03',58:'2019-02-10',59:'2019-02-17',60:'2019-02-24',61:'2019-03-03',62:'2019-03-10',63:'2019-03-17',64:'2019-03-24',65:'2019-03-31',66:'2019-04-07',67:'2019-04-14',68:'2019-04-21',69:'2019-04-28',70:'2019-05-05',71:'2019-05-12',72:'2019-05-19',73:'2019-05-26',74:'2019-06-02',75:'2019-06-09',76:'2019-06-16',77:'2019-06-23',78:'2019-06-30',79:'2019-07-07',80:'2019-07-14',81:'2019-07-21',82:'2019-07-28',83:'2019-08-04',84:'2019-08-11',85:'2019-08-18',86:'2019-08-25',87:'2019-09-01',88:'2019-09-08',89:'2019-09-15',90:'2019-09-22',91:'2019-09-29',92:'2019-10-06',93:'2019-10-13',94:'2019-10-20',95:'2019-10-27',96:'2019-11-03',97:'2019-11-10',98:'2019-11-17',99:'2019-11-24',100:'2019-12-01',101:'2019-12-08',102:'2019-12-15',103:'2019-12-22',104:'2019-12-29',105:'2020-01-05',106:'2020-01-12',107:'2020-01-19',108:'2020-01-26',109:'2020-02-02',110:'2020-02-09',111:'2020-02-16',112:'2020-02-23',113:'2020-03-01',114:'2020-03-08',115:'2020-03-15',116:'2020-03-22',117:'2020-03-29',118:'2020-04-05',119:'2020-04-12',120:'2020-04-19',121:'2020-04-26',122:'2020-05-03',123:'2020-05-10',124:'2020-05-17',125:'2020-05-24',126:'2020-05-31',127:'2020-06-07',128:'2020-06-14',129:'2020-06-21',130:'2020-06-28',131:'2020-07-05',132:'2020-07-12',133:'2020-07-19',134:'2020-07-26',135:'2020-08-02',136:'2020-08-09',137:'2020-08-16',138:'2020-08-23',139:'2020-08-30',140:'2020-09-06',141:'2020-09-13',142:'2020-09-20',143:'2020-09-27',144:'2020-10-04',145:'2020-10-11',146:'2020-10-18',147:'2020-10-25',148:'2020-11-01',149:'2020-11-08',150:'2020-11-15',151:'2020-11-22',152:'2020-11-29',153:'2020-12-06',154:'2020-12-13',155:'2020-12-20',156:'2020-12-27',157:'2021-01-03',158:'2021-01-10',159:'2021-01-17',160:'2021-01-24',161:'2021-01-31',162:'2021-02-07',163:'2021-02-14',164:'2021-02-21',165:'2021-02-28',166:'2021-03-07',167:'2021-03-14',168:'2021-03-21',169:'2021-03-28',170:'2021-04-04',171:'2021-04-11',172:'2021-04-18',173:'2021-04-25',174:'2021-05-02',175:'2021-05-09',176:'2021-05-16',177:'2021-05-23',178:'2021-05-30',179:'2021-06-06',180:'2021-06-13',181:'2021-06-20',182:'2021-06-27',183:'2021-07-04',184:'2021-07-11',185:'2021-07-18',186:'2021-07-25',187:'2021-08-01',188:'2021-08-08',189:'2021-08-15',190:'2021-08-22',191:'2021-08-29',192:'2021-09-05',193:'2021-09-12',194:'2021-09-19',195:'2021-09-26',196:'2021-10-03',197:'2021-10-10',198:'2021-10-17',199:'2021-10-24',200:'2021-10-31',201:'2021-11-07',202:'2021-11-14',203:'2021-11-21',204:'2021-11-28',205:'2021-12-05',206:'2021-12-12',207:'2021-12-19',208:'2021-12-26'},'value':{0:5772,1:5902,2:5820,3:5802,4:5860,5:6005,6:6052,7:6244,8:6600,9:6253,10:6099,11:6167,12:6011,13:5844,14:5956,15:5813,16:5861,17:5870,18:5877,19:5834,20:5721,21:5885,22:6013,23:5933,24:5902,25:5994,26:6157,27:6048,28:6020,29:6041,30:6103,31:5994,32:5923,33:5881,34:5934,35:5871,36:5856,37:5818,38:6010,39:5884,40:5815,41:5816,42:5880,43:5897,44:5869,45:5851,46:6007,47:5973,48:5825,49:5913,50:6136,51:5647,52:5700,53:5731,54:5681,55:5788,56:5838,57:5740,58:5665,59:5645,60:5876,61:5799,62:5749,63:5694,64:5741,65:5724,66:5848,67:5875,68:5800,69:5851,70:5941,71:5816,72:5683,73:5731,74:5839,75:5705,76:5680,77:5775,78:5866,79:5810,80:5680,81:5606,82:5709,83:5677,84:5661,85:5616,86:5633,87:5710,88:5638,89:5626,90:5612,91:5654,92:5696,93:5670,94:5625,95:5682,96:5698,97:5774,98:5734,99:5947,100:6050,101:5925,102:5956,103:5571,104:5652,105:5656,106:5642,107:5649,108:5881,109:5814,110:5774,111:5759,112:5928,113:5866,114:5973,115:5968,116:5869,117:6165,118:5875,119:5749,120:5779,121:5747,122:5876,123:5892,124:5779,125:5812,126:5742,127:5625,128:5578,129:5576,130:5589,131:5545,132:5545,133:5554,134:5553,135:5551,136:5480,137:5509,138:5610,139:5611,140:5612,141:5710,142:5839,143:5795,144:6008,145:5918,146:5840,147:5844,148:5905,149:5844,150:5818,151:5853,152:6161,153:6385,154:6303,155:5681,156:5729,157:5898,158:5873,159:5856,160:5899,161:5910,162:5926,163:6254,164:6107,165:6303,166:6229,167:6172,168:6122,169:6086,170:6394,171:6324,172:6182,173:6118,174:6351,175:6015,176:6027,177:5896,178:6061,179:6015,180:5946,181:5897,182:5913,183:5829,184:5770,185:5776,186:5865,187:5863,188:5818,189:5817,190:5811,191:5839,192:5811,193:5793,194:5792,195:6198,196:6344,197:5433,198:6192,199:6293,200:6034,201:6281,202:6138,203:6147,204:6359,205:6381,206:6485,207:6380,208:6006}})


 So my regressor is already forecasted and no lagging needed.
But I keep getting this error saying
So my regressor is already forecasted and no lagging needed.
But I keep getting this error saying 

















 15 Jun 20, 2022
15 Jun 20, 2022
 4 Dec 27, 2022
4 Dec 27, 2022
 416 Jan 06, 2023
416 Jan 06, 2023
 1 Jan 28, 2022
1 Jan 28, 2022
 2.4k Jan 02, 2023
2.4k Jan 02, 2023
 558 Dec 28, 2022
558 Dec 28, 2022
 0 Jan 31, 2022
0 Jan 31, 2022
 1 Jan 08, 2022
1 Jan 08, 2022
 33 Dec 27, 2022
33 Dec 27, 2022
 179 Dec 31, 2022
179 Dec 31, 2022
 64 Nov 30, 2022
64 Nov 30, 2022
 2 Jul 19, 2022
2 Jul 19, 2022
 1.4k Jan 01, 2023
1.4k Jan 01, 2023
 547 Dec 21, 2022
547 Dec 21, 2022
 802 Jan 01, 2023
802 Jan 01, 2023
 1.4k Jan 03, 2023
1.4k Jan 03, 2023
 152 Jan 02, 2023
152 Jan 02, 2023
 275 Dec 28, 2022
275 Dec 28, 2022
 32k Dec 30, 2022
32k Dec 30, 2022
 1 Nov 05, 2021
1 Nov 05, 2021